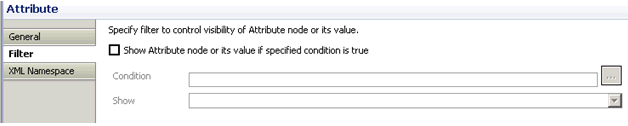
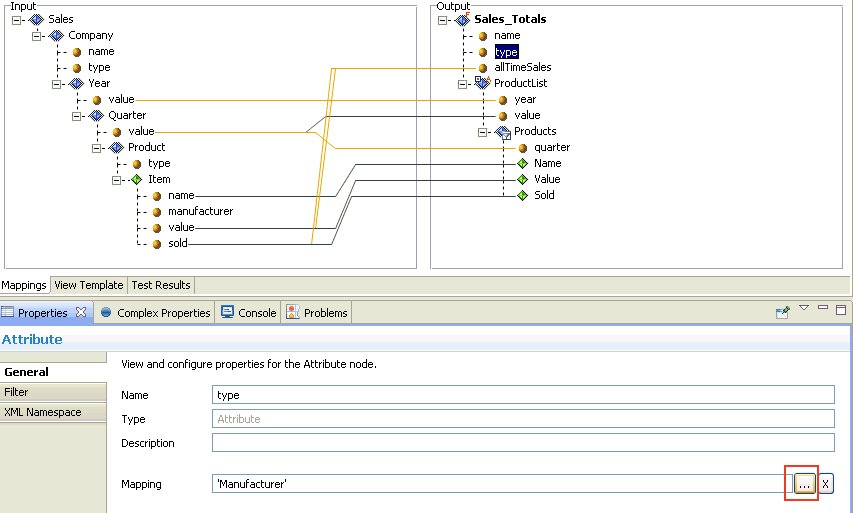
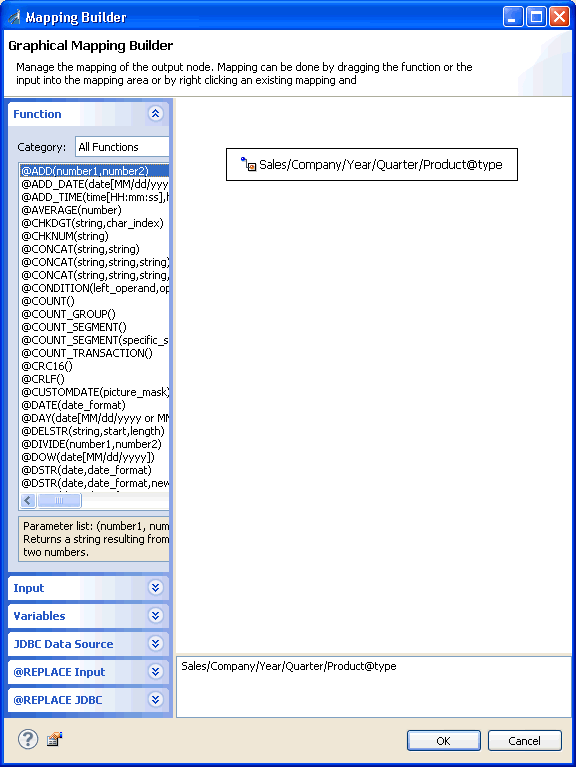
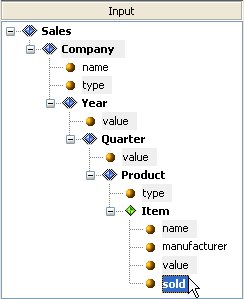
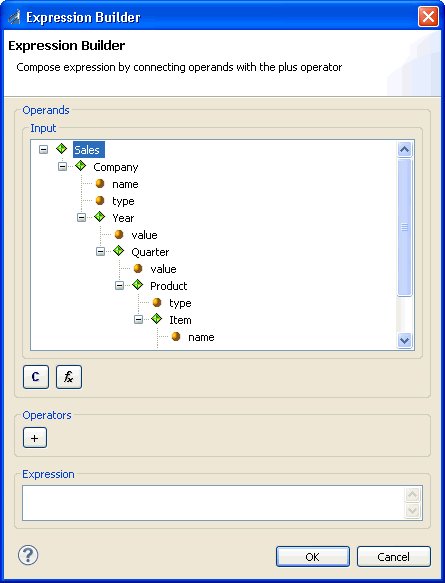
Mappings Tab
|
In this section: |
The Mappings tab is the workspace and default display for designing a Transform component.
The following information is available on the Mappings tab:
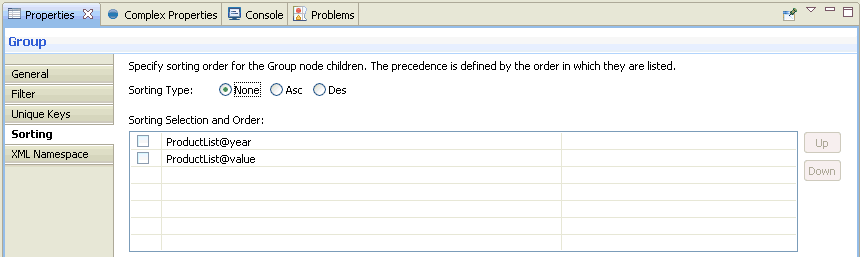
- Input and
output document structure tree. You can entirely or partially expand
or collapse the structure nodes.
Note: As part of the document structure tree, the individual fields and records of your input and output are referred to as nodes throughout this manual.
- The data associations
between input and output nodes, represented by lines between nodes.
If you do not want to display the mapping lines, click the Hide Mappings button to disable this option.
- Details of
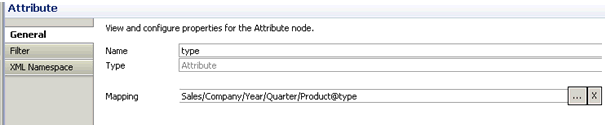
a particular structure node.
You can right-click the node and select Properties.
The Mappings tab includes the following panes, which systematically display mapping-related information:
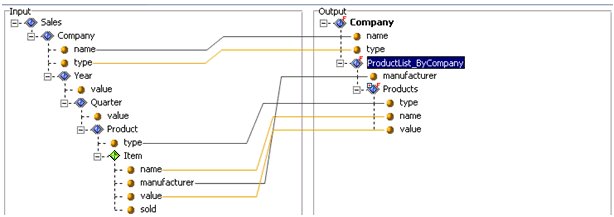
- Input. This pane is displayed on the left. It contains the visual representation of the document tree of the structure of the input data (incoming document). The input structure is read only on the Mappings tab.
- Output. This pane is displayed to the right of the Input pane. It is your workspace for designing the structural layout of the output document, building its visual representation and specifying its properties.
When working with structures, you can perform the following tasks:
- Load and configure
input or output structure nodes. Input configuration is limited.
For more information on loading the input and output documents, see Configuring a Transform.
- Drag and drop nodes from the Input pane to the Output pane in order to copy parts of the input document tree to the output.
- Add or delete a structure node.
The following menus let you easily perform various mapping-related tasks:
- The Input Node menu provides the available options for manipulating the nodes in the input structure, which is displayed in the Input pane. For more information, see Input Node Workspace Menu.
- The Output Node menu provides the available options for manipulating the nodes in the output structure, which is displayed in the Output pane. For more information, see Output Node Workspace Menu.
- The Mapping Values menu provides the available options for assigning values to the nodes in the output structure, which is displayed in the Mapping pane. For more information, see Mapping Values.
Input Node Workspace Menu
Right-click an input node in the workspace to display the menu options that are available for the nodes in the Input pane. You can expand or collapse various nodes within the structure tree, copy a node, and show or hide mappings between input and output nodes.
The following image shows the options available on the Input Node menu.
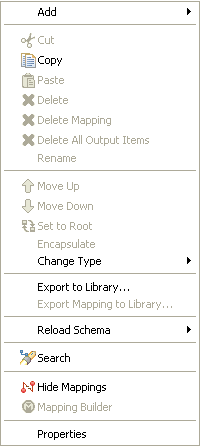
The following table describes the Input Node menu options.
|
Option |
Description |
|---|---|
|
Copy |
Copies the selected input node and enables you to paste it in the output. |
|
Reload Schema |
Reloads the schema for the Input or Output structure pane. |
|
Search |
Opens the Search dialog box, enabling you to search for text or to search for and map input and output nodes. |
|
Hide Mappings |
Toggles between showing and hiding the mapping lines between the input and output structures. |
|
Properties |
Displays the properties of the selected input node. |
Output Node Workspace Menu
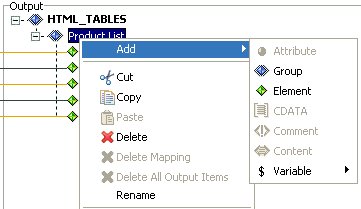
Right-click an output node in the workspace to display the menu options that are available for the nodes in the Output pane. The following image shows the options available on the Output Node menu.
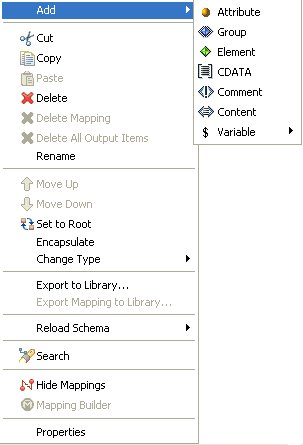
The options that are available on the Output Node menu depend on which node is currently selected in the Output pane.
You can disable certain options, depending on the type and position of the output node in the structure (for example, group, element, or attribute) or the data format (for example, XML or EDI X12).
The Add and Change Type option lists are dynamic. They also depend on the type of the output node and the output data format.
The following table describes the options available on the Output Node menu.
|
Option |
Description |
|---|---|
|
Add |
Enables you to alter the existing output structure by inserting a new structure node of a specific type. The following types of structure nodes are supported:
Refer to the Add submenu of a particular node for the list of enabled node types that you are permitted to add. The values of the available node types are enabled or disabled according to the mapping rules for the output data format. For example, if the XML data format is used, the only available types of nodes that you can add to an element type of node is an attribute node or a CDATA node. |
|
Cut |
Cuts the selected output node, making it available for the paste output operation. |
|
Copy |
Copies the selected node to a location that you determine. |
|
Paste |
Pastes the cut or copied node. |
|
Delete |
Removes a node from the Output structure. A confirmation dialog box is displayed for this option. |
|
Delete Mapping |
Deletes the selected mapping. |
|
Delete All Output Items |
Deletes all output items. |
|
Rename |
Renames the selected output structure node. This option is also available if you double-click the name of the node. |
|
Move Up |
Moves the selected node up the output structure tree, under the same parent node. |
|
Move Down |
Moves the selected node down the output structure tree, under the same parent node. |
|
Set to Root |
Enables you to represent the root of the document structure tree. This option is not available for record-based data formats, such as CSV. This option is available only for the nodes of type Group, because this is the only type of node that is permitted to perform the root functionality. |
|
Encapsulate |
Creates an invisible parent group wrapped around the output node that you choose to encapsulate. The encapsulating feature is useful when you are resolving complex looping or mapping issues. For an example, explore the WebFOCUS_Banklist sample transform project that is packaged with iWay Transformer. |
|
Change Type |
Changes the type of the node to one of the following:
For more information, see Output Structure. |
|
Export to Library |
Exports the selected component to the library. |
|
Export Mapping to Library |
Exports the selected mapping to the library. |
|
Reload Schema |
Reloads the schema for the Input or Output structure pane. |
|
Search |
Opens the Search dialog box, enabling you to search for text or to search for and map input and output nodes. |
|
Hide Mappings |
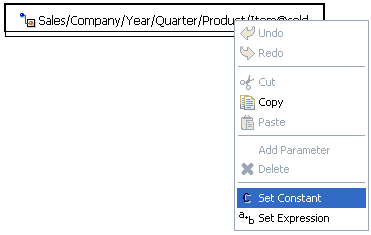
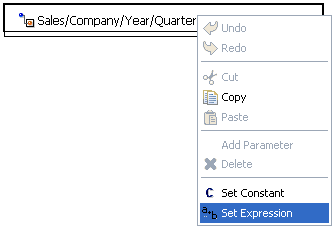
Toggles between showing and hiding the mapping lines between the input and output nodes. The mappings signify the relationships between the input and output nodes, where the particular input value is used to construct the value of the output node. |
|
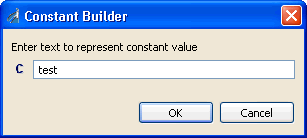
Mapping Builder |
Opens the Mapping Builder window, which enables you to modify the mapping value by changing the input node that it maps to. Alternatively, you can add a function, constant, or expression to the existing mapping. For more information on how to use the Mapping Builder, see Working With Functions. |
|
Properties |
Displays the Properties tab, which shows the layout and structural information pertaining to the selected output node. For more information, see Group Properties. |
Input Structure
The input structure contains the input, which represents the groups, elements, and attributes encoded in the input document. Each node in this tree has exactly one parent, and can have more than one child.
The following table describes the various components provided in iWay Transformer to represent input nodes. Definitions of basic terms commonly used for nodes within an input document tree are also provided.
|
Input Document The incoming document or message to which transformations apply. The following formats are supported:
The input document is displayed on the input pane as a visual representation of the input document tree. It maintains a logical order of component nodes, such as groups or elements, in relation to the underlying document, wrapping the nodes that are contained within other nodes. For more information, see the Input Document Tree Example that follows. Each input node contains a name that identifies the type of the node, optionally a number of attributes, or content. |
|
Group Block of data that has a group element as its root. It can contain other groups or elements nested within, as children. Multiple groups can also exist on the same level. A group was formerly called a parent. iWay Transformer does not support mixed content group nodes containing data values. However, the group node for XML and HTML data formats can have any number of attribute nodes inside, if applicable. |
|
Element Usually belongs to the group as a leaf, which cannot have any other nested groups or elements. It typically stores a data value. In XML and HTML data formats, it can contain attribute nodes or CDATA. |
|
Attribute Value associated with a group or element, consisting of a name, and an associated textual value. Attributes are used for XML and HTML data formats only. Each group or element can have zero to many attributes. |
|
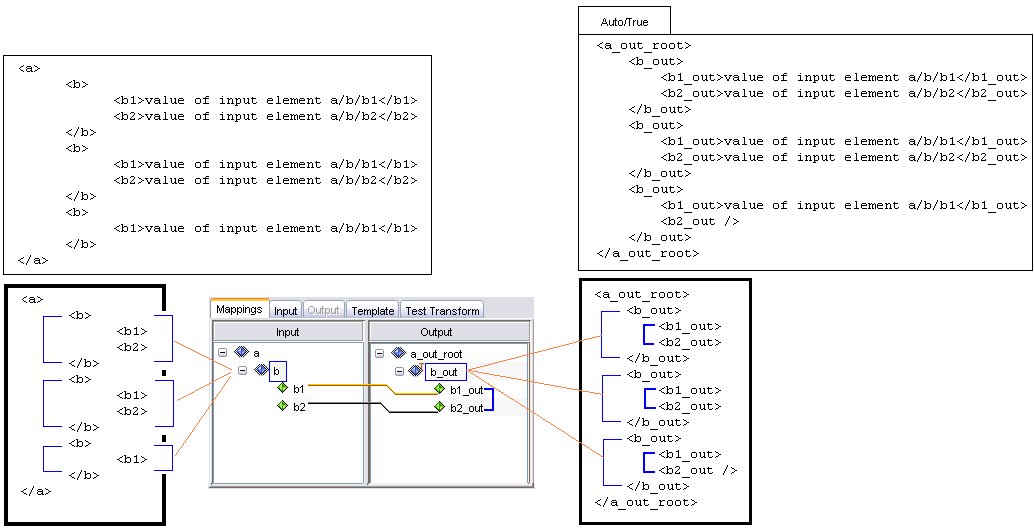
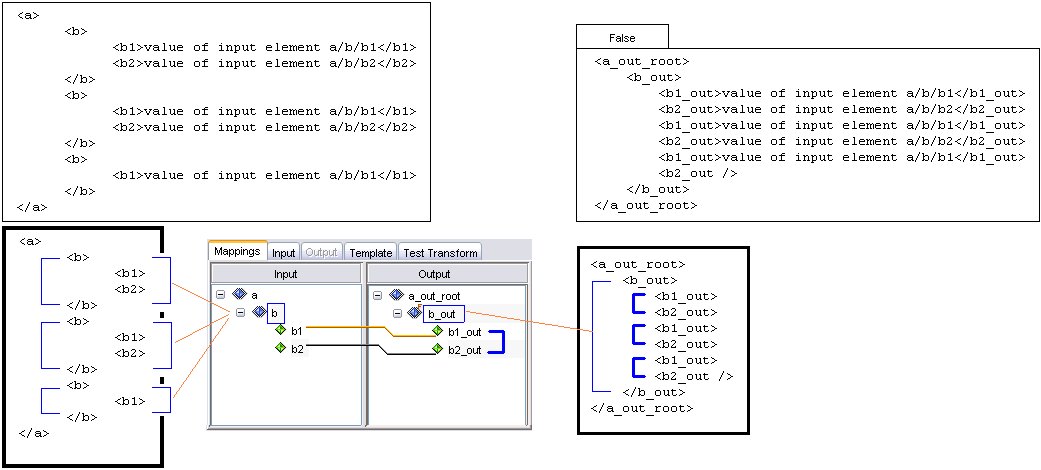
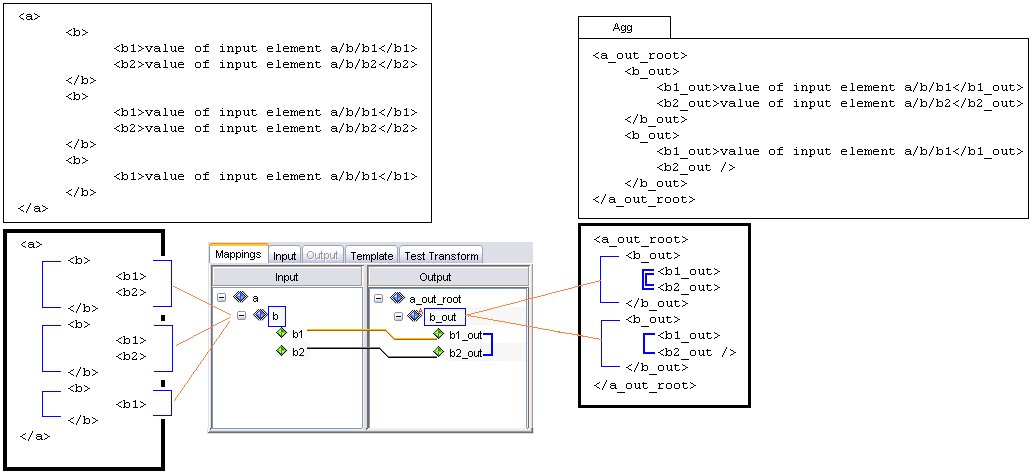
Example of Input Document Tree Sample document tree of groups, elements, and attributes encoded in the input message. Each node in this tree has exactly one parent, and may have more than one child. The following is a section of an XML input document:  The following is a tree structure representation of the preceding XML: 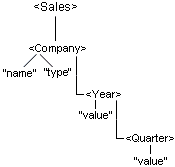 In iWay Transformer, the resulting input document tree is as follows: 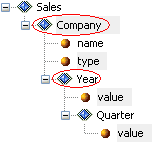 You can collapse or expand the document tree from the given node to its deepest descendant. iWay Transformer supports a set of different relationships that link nodes together. |


The common types of document tree relationships are described in the following table.
|
Parent The input can have more than one parent (root group). Parent is a group in relation to the elements or groups contained within it. In the preceding example, the group, Company, is a parent of two elements, Year and Quarter. |
|
Child Node A is called the child of node B, if and only if B is the parent of A. In the preceding example, the element Year is a child of the Company group. |
|
Descendant Node A is called a descendant of node B, if either (1) A is a child of B, or (2) A is the child of node C, which is a descendant of B. |
|
Ancestor Node A is called an ancestor of node B, if and only if B is a descendant of A. |
|
Sibling Node A is called a sibling of node B, if and only if B and A share the same parent. Node A is a preceding sibling if it comes before B in the input document tree. Node B is a following sibling if it comes after A in the input document tree. |
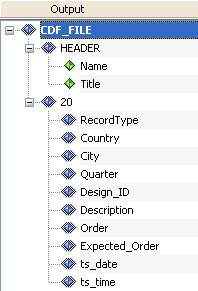
Output Structure
The output structure contains the output document tree, which represents the completed structure of groups, elements, and other supported node types, such as attributes or CDATA, encoded in the output document.
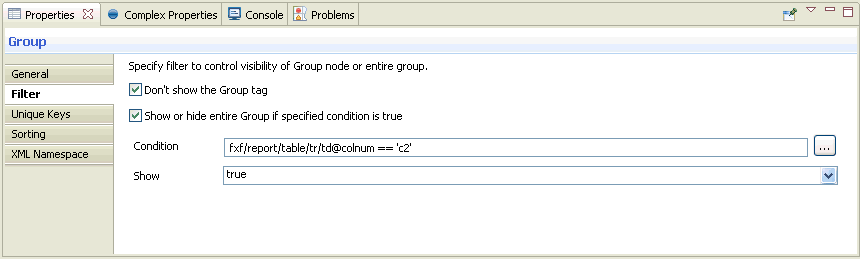
Each node in this tree has exactly one parent group. It can have one or more sibling nodes, unless it is the root node in the tree, which has to be unique according to the mapping rules in iWay Transformer. You can adjust the properties of the given node, such as visibility or namespace, to affect its appearance in the actual output document.
This topic examines the output document tree in the XML to HTML table example, which is included as a sample Transform component.
The output structure is represented as follows:
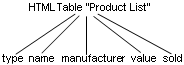
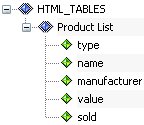
In iWay Transformer, the output document tree is visualized as follows in the Output pane of the Mappings tab:

 button,
which opens the Input Fields pane. Select an input node to be mapped
from the hierarchy tree and click
button,
which opens the Input Fields pane. Select an input node to be mapped
from the hierarchy tree and click