In this section:
In this section: |
The output hierarchy provides a graphical representation of how the output data will be organized. The output hierarchy defines output elements line-by-line and uses a tree structure containing nodes of supported types (for example, group or element) to produce the desired output according to your requirements. Nodes of type Group and elements are typically the primary building blocks for the document tree node set, with the essential group at the root of the document tree, from which the rest of the structure derives. Groups can have children and can be nested, which means that group nodes can be children and parents in relation to other group nodes. Element nodes cannot have children but they are always derived from the group node, which means they are acting as leaves of the group.
Note: You can change the visibility of groups and elements or use pre-defined looping mechanisms to present your output data in the format specific to your requirements.
The following node types are supported in the mapping structures of the Mapping Builder:
One of the useful methods for adding new output nodes is structure mapping. For more information about structure mapping, see Group . Another method of adding new output nodes is by building your document output tree, which is achieved by right-clicking an existing output node and selecting Add followed by the type of node you wish to add.
For a description of each available output node, see Mapping Types.
The type of the output node you may insert will depend on the type of the parent node to which you want to add your data node. For example, if you right-click an XML element node in your output structure, you may discover that the only possible type of nodes which can be added to that element node is an attribute node. By following these restrictions, the integrity of the output structure is maintained.
You can review the available options for the output node type by right-clicking the parent node and selecting the Add submenu.
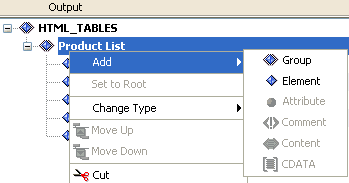
A group is a block of data that has a group node as its root. It can contain other group or element nodes nested within, and other node types if supported (for example, attribute or CDATA for XML data format). Multiple groups can also exist on the same level. The nodes contained within a certain group are also called children of this particular group, sometimes referred to as a parent group in relation to the nodes nested within it.
Every output structure, regardless of the output data format, has at least one group node at its root. A group marks the start of an output block by specifying the start of an output loop. The first node in your output structure, referred to as a Root, is created automatically by Transformer when you create your initial output structure. You can then build your structure from the root group node by adding the nodes of supported type one by one, or by copying the blocks of data from existing input or output structures. The output is produced by looping through the entire output structure (starting from the root group), one or more times (iterations), depending on your settings, while reading the mapped values from the input file.
Consider the CDF output structure displayed in the following image.
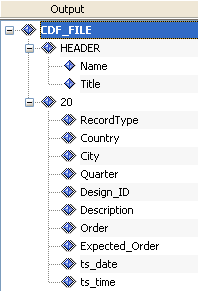
The first output node, CDF_FILE, is the first group node and is also called the Root. The presence of the Root node ensures that Transformer loops over the entire output structure if needed. The next node in the output tree is a HEADER node, which is also a group type of node. Appearance of the HEADER node marks an output block of data, which includes the child element nodes Name and Title. The node, 20, is also a group node, which contains an output block of data to include the next ten child element nodes (RecordType to ts_time). Group nodes are distinguished by the Group icon, which has a blue diamond shape with a double border. Element nodes are distinguished by the Element icon, which has a blue diamond shape.
The following list contains the visual variations of the group node when a specific property is configured for it.
A group node that has its visible property set to false. This means that even though the group node is present in the output structure during design time, the invisible node’s value or the whole block of its children nodes will not be displayed in the run-time output produced by the project. For more information on hiding a group, see Filter Tab.

A group that has a context applied. The context property is the explicitly defined reference of the output group node to the particular input group node. It helps to control looping, and to resolve challenges and opportunities in the area of data structure searching. It is especially useful for nested multi-level repeated structures. It operates on the logical structure of the message (similar to XPath). It is available for use by any data format supported by Transformer.
In the following image, the context is applied to the group node b on the output, which indicates that this output node should relate its content and looping to the corresponding node from the input structure. In this case it is group node b, which is under parent node a. The notation used by Transformer is a/b.
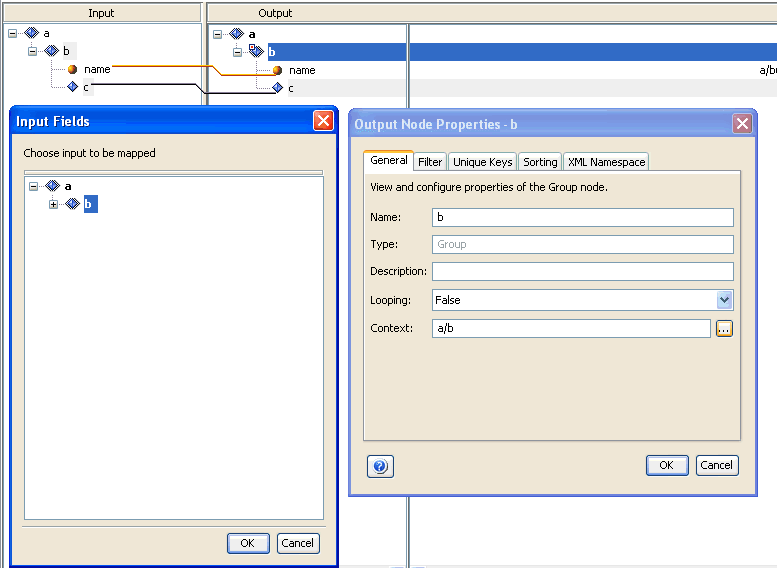
To set the context property, right-click the group node b in the Output pane and select Properties. The Properties dialog box opens and displays the General tab by default.
In the
Context field, specify the path value for the looping node on the
input side. Click the ellipses button  ,
which opens the Input Fields pane. Select an input node to be mapped
from the hierarchy tree and click OK.
,
which opens the Input Fields pane. Select an input node to be mapped
from the hierarchy tree and click OK.
For more information on setting a context for a group, see General Tab. For more information on using the context sample that is provided with Transformer, see Sample Transformations.

A group that has a filter applied. The filter property is useful when your incoming document data may contain loop iterations that should not appear in your output, according to your requirements. The filter property is designed to help you remove unnecessary blocks of data. For more information on specifying a filter for a group, see Filter Tab.
Depending on the group properties (loop, context, and filter) that are specified in the Output Node Properties dialog box, the group icon changes in the Output pane to reflect these settings. The following table lists all of these variations for your reference.
|
Group Setting |
Visible Icon |
Invisible Icon |
|---|---|---|
|
Loop is set to true |
|
|
|
Loop is set to false |
|
|
|
Loop is set to aggregate |
|
|
|
Context is applied and loop is true |
|
|
|
Context is applied and loop is false |
|
|
|
Context is applied and loop is aggregate |
|
|
|
Filter is applied and loop is true |
|
|
|
Filter is applied and loop is false |
|
|
|
Filter is applied and loop is aggregate |
|
|
|
Context and filter are applied and loop is true |
|
|
|
Context and filter are applied and loop is false |
|
|
|
Context and filter are applied and loop is aggregate |
|
|
Additional XML Output Structures
In Transformer, it is easy to create complex output structures for your output file. The way you arrange the nested components in the Output pane of the Mapping window is exactly how your output will be structured.
You can use parent nodes to create complex output structures with nested parent nodes and output loops for the XML output formats (XML and e-business). EDI (X12, HIPAA, EDIFACT, and SWIFT) output is treated as XML output due to the use of the e-business metadata by the Transformation Engine.
In addition to indicating the possible start of an output loop, a group node can also play an important role in building the following structures depending on the output data format:
A set of useful properties is available for group output nodes. To view the properties of the group node in the Dictionary tab of the Output pane, you must right-click a group node and then, select Properties. The Properties dialog box opens, as shown in the following image.
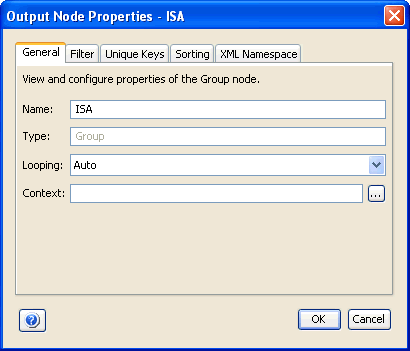
The General tab is displayed by default. Notice that the Type field contains a default value of Group, which indicates the type of mapping node being used. The properties of a group node are displayed on the following tabs:
The following sections describe the tabs and options available from the Properties dialog box for the group node.
The General tab displays information such as the name and type of the node, as well as looping and context settings of the current node.
In order to determine how your group node will loop, you need to examine the list of available values from the Looping drop-down list, and select the applicable option.
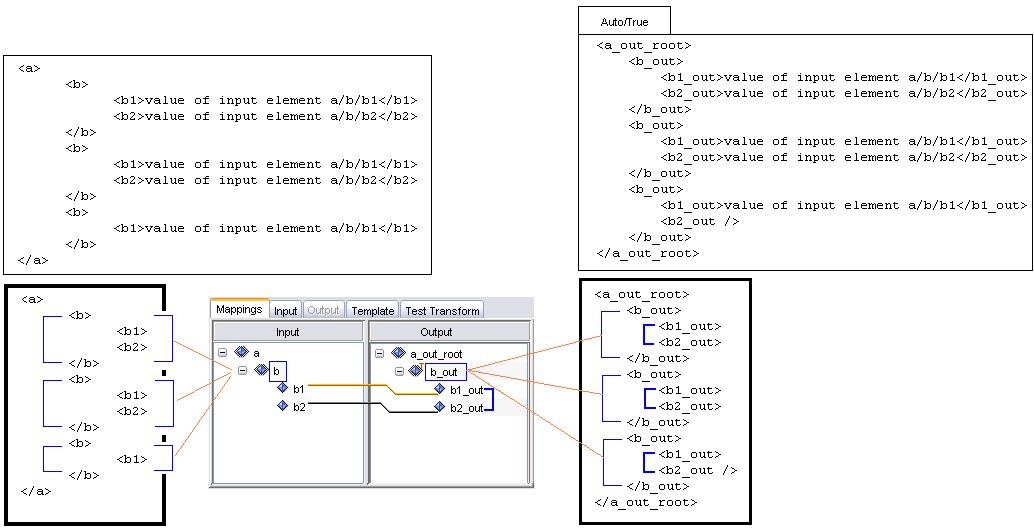
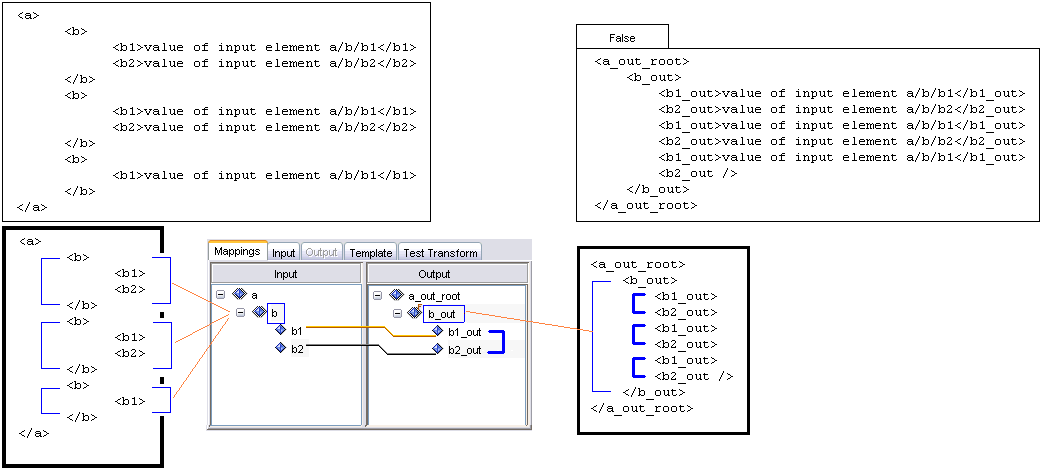
If aggregate looping is selected for the particular group, it means that all instances of this group node which have the same attribute values are combined into one unique group node. Any nodes that are children of these elements are also gathered and made subordinate to the new parent node.
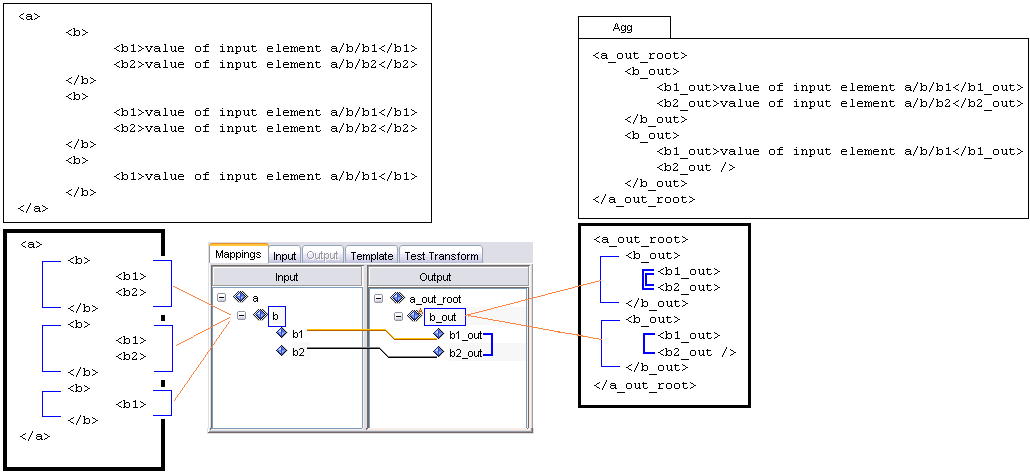
For more information on aggregate looping, see Sample Transformations.
The Context field in the General tab is an advanced feature designed to help control local looping. Applying a context to a group node in your output structure can solve looping complexity issues. It is especially useful in projects, which require you to make references to input nodes located in different places within the hierarchy of a structure. The Context specifies the location of the node where the block of input that is being used for looping begins. Generally, this should be set to the innermost group block from your input structure, which encapsulates all of the input data that must be used within this output group node.
To better understand how the Context feature works, you can examine one of the iWay sample XML projects, located in the following directory:
<iWaySMHome>\tools\transformer\samples\transform_projects\xml\XML_to_XML\Context\Context.gxpwhere:
Is the directory where iWay Service Manager was installed.
The input to output structure mapping is shown in the following image.
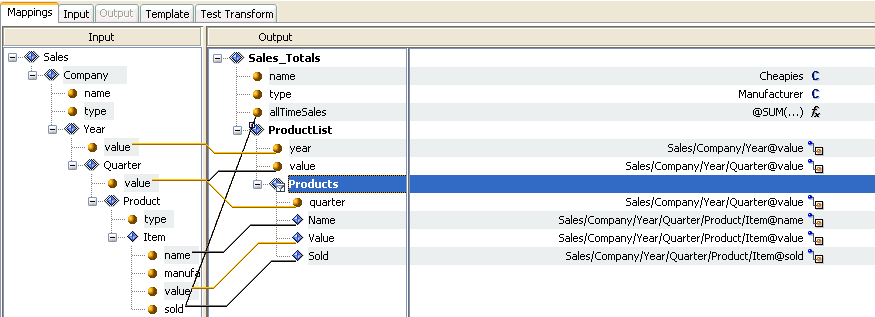
The input is an XML file that lists the details for the sales of a company item. The input information is organized by the year, quarter, product type, and the individual (brand). The output is an XML file containing the sales only for items from the specific manufacturer, for example, Cheapies. The output sales are arranged by year, quarter, and item.
Note that Product List has looping set to aggregate and context is set to Sales/Company/Year. Aggregation looping is required to enforce that only one parent node will exist in the output per each quarter. The reason why the context is set to Year is that the Year is the lowest group node in the input structure hierarchy that contains all of the information used within the Product List node. The input node Year opens the block of data in which the looping will occur.
When a context is applied to a group, the group icon in the Output pane is displayed as follows:
The following image shows the Filter tab of the Properties (group node) dialog box.
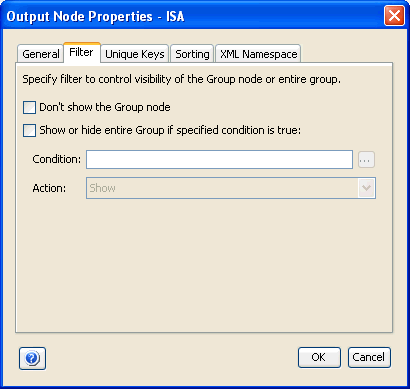
The Show or hide entire Group if specified condition is true check box enables you to control the appearance of all the nested groups and elements, by defining the condition and resulting action on the group node and its contents. Therefore, each individual output block produced by that output loop will be displayed or hidden in the actual output depending on the state of this option.
When a filter is applied, the group node icon in the Output pane is displayed as follows:
If this check box is selected and the Hide option is selected in the Action drop-down list, then the particular output block that satisfies the condition entered is omitted from being displayed in the output data.
When a group is hidden, the group icon in the Output pane is displayed as follows:
If the condition you enter is evaluated as true for an output loop and the Show option is selected from the Action drop-down list, then only that output block is displayed in the output. All other iterations of the group loop that do not match the condition you specified are suppressed from being displayed in the output data.
The condition you type must be in the following format:

For example:
Horses/Team/Years/Player/Goals == '30'
where:
Is the location of the node in your input document structure.
Is the desired alphanumeric value of that node. As the incoming document is processed by the Transformation Engine, if this condition is met in the particular data iteration, the action selected in the Action drop-down list is performed.
If you are using the Expression Builder to construct the condition,
click the ![]() icon
to specify a constant value.
icon
to specify a constant value.
The following table lists the possible arguments (operators) for the block condition.
= = | equal to |
!= | not equal to |
>= | greater than or equal to |
<= | less than or equal to |
> | greater than |
< | less than |
When you click on the ellipsis button next to the Condition field, the Expression Builder window is displayed to help you build a condition intuitively.
The following image shows the Unique Keys tab of the Properties dialog box.
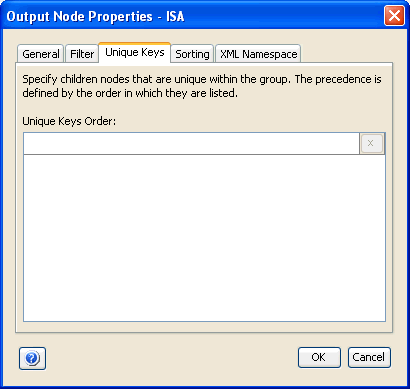
You can control the appearance of a group's output child nodes by defining nodes as unique in the Unique Keys tab. This will remove unnecessary data repetitions from your output group node. The child node you specify as the node will determine which loop repetitions will be suppressed. The output will display only the first unique occurrences of the key node. For example, assume that you generate the following non-unique XML output data:
<Product>
<ProductID>XR281</ProductID>
<Name>Green Rocket Vehicle</Name>
</Product>
<Product>
<ProductID>SR71</ProductID>
<Name>SR-71 Blackbird</Name>
</Product>
<Product>
<ProductID>XR281</ProductID>
<Name>Green Rocket Vehicle Again</Name>
</Product>If you choose to make the output group node Product unique by specifying the output child node, ProductID, in the Unique Keys parent property, then your final output is the following:
<Product>
<ProductID>SR71</ProductID>
<Name>SR-71 Blackbird</Name>
</Product>
<Product>
<ProductID>XR281</ProductID>
<Name>Green Rocket Vehicle</Name>
</Product>Note: You can specify multiple unique keys if required.
The second instance of the XR281 product was removed because it was not unique to the output item ProductID.
The following image shows the Sorting tab of the Properties dialog box.
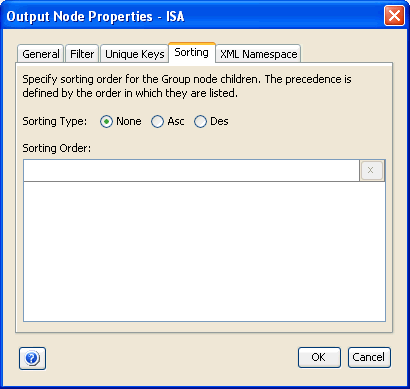
The Sorting tab provides you with the option to enable the sorting of the loop iterations in the blocks of data represented by the particular group node. You can choose a child node within the current group, by which to sort your output. The output can be sorted in ascending or descending alphanumeric order by the node or nodes you choose in the Sorting Order section. The Sorting Type option specifies how the output is sorted. Possible values are None, Asc (Ascending), or Des (Descending). Sorting Type defaults to None.
The following image shows the XML Namespace tab of the Properties dialog box. This tab provides options to specify XML namespaces for the individual group node. It is similar to the XML Namespaces category found in the Project Properties dialog box.
For more information on defining XML Namespaces, see Working With Namespaces or Working With Namespaces.
An element node is used to represent a basic data item in Transformer. Element nodes are typically found inside the group node. Sometimes it is referred to as a leaf of the output tree because it cannot have any other child nodes, such as the nested groups or elements within it, except for the attribute nodes (for XML data format only).
The set of element node properties is defined for an element output node. To view the properties of the element node in the Output pane, you must right-click an element node and then, select Properties. The Properties dialog box opens.
The following topics describe the tabs available from the Properties dialog box for the element node.
The following image shows the Properties dialog box for the element node, which provides the following tabs:
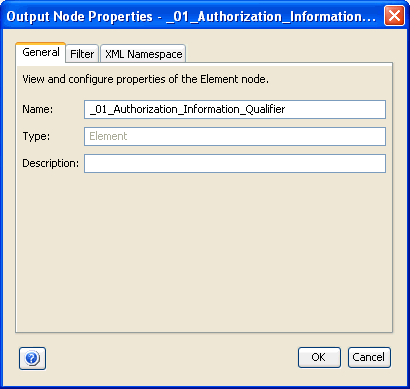
The Properties dialog box for the element node defaults to the General tab. Notice that the Type field contains a default value of Element, which indicates the type of mapping for which the properties are displayed.
You can also apply a filter to an element. The following image shows the Filter tab of the Properties dialog box for the element node.
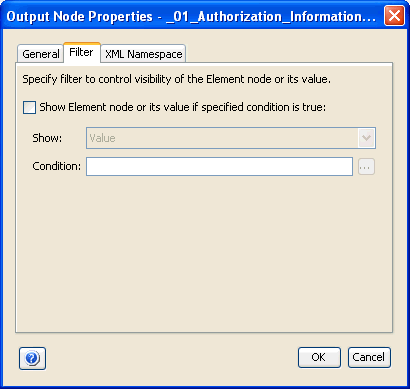
The Show Element node or its specified value if specific condition is true check box enables you to include all the element nodes or their values in the output, by defining the condition and resulting action on the child node.
The condition you type must be in the following format:
For example:
Horses/Team/Years/Player/Goals == '30'
where:
Is the location of the node in your input document structure.
Is the desired alphanumeric value of that node.
If you are using the Expression Builder to construct the condition,
click the ![]() icon
to specify a constant value.
icon
to specify a constant value.
The following table lists the possible arguments (operators) for the block condition.
= = | equal to |
!= | not equal to |
>= | greater than or equal to |
<= | less than or equal to |
> | greater than |
< | less than |
When a filter condition is applied to an element node, the element icon in the Output pane is displayed as follows:

The following image shows the XML Namespace tab of the Properties dialog box for the element node.
For more information on defining XML Namespaces, see Working With Namespaces or Working With Namespaces.
An attribute node contains a value associated with a specific group or element. It consists of a name, and an associated (textual) value. Attribute nodes are supported for XML format data only.
In the following example, name and type are attributes for the Company element:
<Company name="Video and Sound Card Express" type="Computer Parts">
The set of various attribute properties is available for an attribute output node. To view or modify the properties of the attribute in the Output pane of the Transformer’s workspace, you must right-click an attribute node and then, select Properties. The Properties dialog box opens.
The following topics describe the tabs available from the Properties dialog box for the attribute node.
The following image shows the Properties dialog box for the attribute node, which provides the following tabs:
The Properties dialog box for the attribute node defaults to the General tab. Notice that the Type field contains a default value of Attribute, which indicates the type of mapping for which the properties are displayed.
You can also apply a filter to an attribute. The following image shows the Filter tab of the Properties dialog box for the attribute node.
The Show Attribute node if specific condition is true check box enables you to alter the visibility of the attribute nodes or their values in the output, by defining the condition and resulting action on the child node. The condition you type must be in the following format:
For example:
Horses/Team/Years/Player/Goals == '30'
where:
Is the location of the node in your input document structure.
Is the desired alphanumeric value of that node.
If you are using the Expression Builder to construct the condition,
click the ![]() icon
to specify a constant value.
icon
to specify a constant value.
The following table lists the possible arguments (operators) for the block condition.
= = | equal to |
!= | not equal to |
>= | greater than or equal to |
<= | less than or equal to |
> | greater than |
< | less than |
When a filter condition is applied to an attribute node, the
attribute icon in the Output pane is displayed as follows:
The following image shows the XML Namespace tab of the Properties dialog box for the attribute node.
For more information on defining XML Namespaces, see Working With Namespaces.
A comment node can be used to embed comments into the output structure. Comment nodes are supported for XML output data only.
In the following example, the phrase This is an XML Output sample is a comment.
<?xml version="1.0" encoding="UTF-8"?> <!--This is an XML Output sample-->
A content node is associated with a group node in the output document. Some groups have no content, in which case they are called empty. The content of a group node may include text, and it may include a number of subelements, in which case the node is called the parent of those subelements. Content nodes are supported for XML output data only.
A CDATA node is used to indicate sections of data that you want the XML parser to ignore during validation. CDATA sections can include special characters that will not be parsed. CDATA nodes are supported for XML output data only.
In the following example, the CDATA tag (node) is wrapped around the compare(a,b) function, which contains special characters that are not allowed in XML syntax. As a result, these characters will not be parsed.
<![CDATA[
function compare(a,b)
{
if (a > b) then
{
return 1
}
}
}]]>
Additional key terms used to describe mapping relationships within the output document tree are:
A node A is the parent of a node B if node B is contained within the structure of node A, and belongs to the block of data that node A represents. The output has at least one parent group, which is referred to as the root group.
A node A is called the child of a node B if and only if B is the parent of A.
A node A is called a descendant of a node B, if either (1) A is a child of B, or (2) A is the child of some node C that is a descendant of B
A node A is called an ancestor of a node B, if and only if B is a descendant of A.
A node A is called a sibling of a node B, if and only if B and A share the same parent. Node A is a preceding sibling if it comes before B in the output document tree. Node B is a following sibling if it comes after A in the output document tree.
| iWay Software |


























