Cómo definir un grupo individual de campos
Algunos campos del origen de datos pueden tener una correspondencia de uno a uno. Por cada valor de un campo los otros campos tendrán exactamente un valor correspondiente. Por ejemplo, tomemos el origen de datos EMPLOYEE:
- Cada empleado tiene un número de identificación único.
- Por cada número de identificación existe un nombre y un apellido, una fecha de contratación, un departamento y un salario actual.
En el origen de datos, un campo representa cada una de estas características del empleado. El grupo de campos completo representa al empleado. En términos del archivo máster a este grupo se le denomina segmento.
xCómo funciona un segmento
El segmento es un grupo de campos con una correspondencia de uno a uno, que normalmente describe un grupo de características relacionadas. En los orígenes de datos relacionales, el segmento es el equivalente de la tabla. Los segmentos constituyen la base sobre la que se apoyan estructuras de datos más grandes. Puede relacionar segmentos diferentes entre sí y describir estructuras nuevas, como se explica en Cómo relacionar varios grupos de campos.
El siguiente diagrama explica el concepto de segmento.
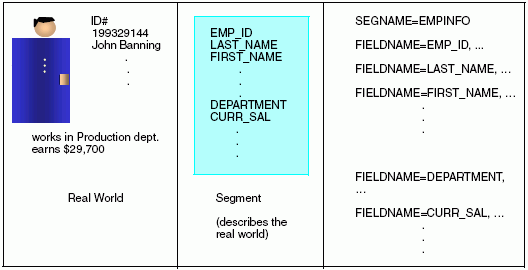
xCómo funcionan las instancias del segmento
Mientras que el segmento es una descripción abstracta de los datos, sus instancias correspondientes son los verdaderos datos. Cada instancia es un caso de los valores de segmento situados en el origen de datos. En los orígenes de datos relacionales, la instancia es el equivalente de una fila de la tabla. En los orígenes de datos con una sola instancia de segmento, la instancia del segmento es igual al registro.
La relación entre el segmento y sus instancias aparece reflejada en el siguiente diagrama.
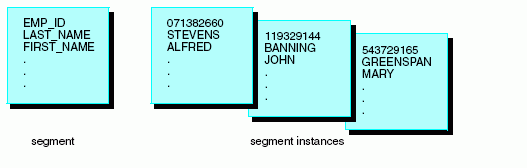
xCómo funciona una cadena de segmentos
A las instancias del segmento que sean descendientes de una sola instancia principal, se les denomina, de forma colectiva, cadena de segmentos. En el caso especial del segmento raíz, que no pertenece a un segmento principal, la cadena está compuesta por todas las instancias de la raíz. La relación de principal-secundario aparece tratada en Dependencia lógica: Relación principal-secundario.
El siguiente diagrama explica el concepto de cadena de segmentos.
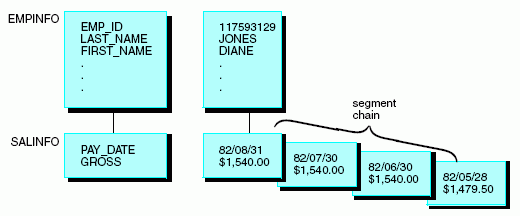
Describa un segmento utilizando los atributos SEGNAME and SEGTYPE, en el archivo máster. El atributo SEGNAME aparece descrito en Cómo identificar un segmento: SEGNAME.
xCómo identificar un campo clave
La mayoría de los segmentos también presentan campos clave, uno o varios campos que identifican el segmento de forma única. En el origen de datos EMPLOYEE el número de id. es la clave, ya que cada empleado tiene un número de id. único (exclusivo a cada empleado). El número de id. está representado por el campo EMP_ID, en el origen de datos.
Si origen de datos utiliza un archivo de acceso, puede que tenga que especificar los campos que actúan como claves, mediante su identificación en el archivo de acceso. Si, además, el origen de datos es de tipo relacional, los campos que constituyen la clave primaria, en el archivo máster, también deben ser los primeros en aparecer descritos para ese segmento, es decir que las declaraciones de los campos deben preceder a cualquier otra cosa en el segmento.
En los orígenes de datos FOCUS, identifique los campos clave y su orden de clasificación por medio del atributo SEGTYPE, en el archivo máster, como se explica en Cómo describir un origen de datos de FOCUS. Coloque los campos clave en primera posición dentro del segmento.
xCómo identificar un segmento: SEGNAME
El atributo SEGNAME identifica el segmento. Es el primer atributo que se especifica en la declaración de un segmento. Su alias es SEGMENT.
En los orígenes de datos de FOCUS, el nombre del segmento puede tener hasta ocho caracteres. Los nombres de los segmentos de un origen de datos de XFOCUS pueden tener hasta 64 caracteres. Si son compatibles con el DBMS, puede usar nombres de hasta 64 caracteres en orígenes de datos que no sean de FOCUS. Para que el archivo máster sea reconocible, establezca SEGNAME en algo que tenga cierto sentido para el usuario o el administrador de archivos nativos. Por ejemplo, si está describiendo una tabla de DB2, asigne el nombre de la tabla (o una abreviación de ella) a SEGNAME.
En los archivos máster, el nombre de cada segmento debe ser único. La única excepción a esta regla se da en los orígenes de datos de FOCUS o XFOCUS, donde los segmentos de referencia cruzada, en joins definidos por un archivo máster, pueden tener el mismo nombre que otro segmento de este tipo. Si los nombres son idénticos, puede hacer referencia a ellos de forma individualizada, mediante el atributo CRSEGNAME. Consulte Cómo definir un join en un archivo máster.
En los orígenes de datos de FOCUS o XFOCUS, no se puede cambiar el valor de SEGNAME después de haber introducido datos en el origen. En el resto de orígenes de datos, puede cambiar SEGNAME siempre que también modifique todas sus referencias. Por ejemplo, cualquier referencia que aparezca en el archivo máster y en el archivo de acceso.
Si su origen de datos emplea un archivo de acceso, además de un archivo máster, debe especificar el nombre del segmento en ambos.
x
Sintaxis: Cómo Identificar un segmento
{SEGNAME|SEGMENT} = segment_namedonde:
- segment_name
Es el nombre que identifica este segmento. En los orígenes de datos de FOCUS, puede tener un máximo de ocho caracteres de longitud. Los nombres de los segmentos de un origen de datos de XFOCUS pueden tener hasta 64 caracteres. Si son compatibles con el DBMS, puede usar nombres de hasta 64 caracteres en orígenes de datos que no sean de FOCUS.
El primer carácter debe ser una letra, mientras que el resto puede tratarse de cualquier combinación de letras, números y guiones bajos ( _ ). No se recomienda el uso de otros caracteres, ya que pueden causar problemas en algunos entornos operativos o a la hora de resolver expresiones.
Ejemplo: Cómo identificar un segmento
Si el segmento corresponde a una tabla relacional llamada TICKETS, y quiere nombrarlo de la misma forma, utilice el atributo SEGNAME del siguiente modo:
SEGNAME = TICKETS