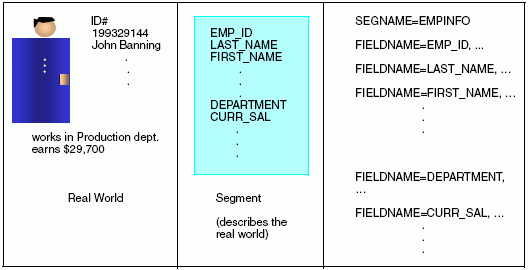
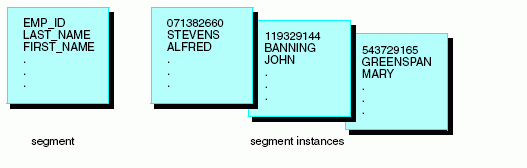
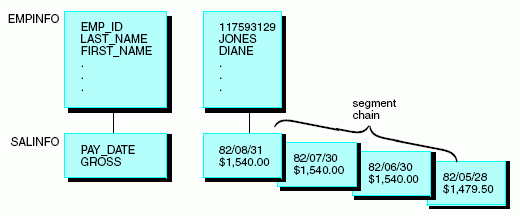
The SEGNAME attribute identifies the segment. It is the first
attribute you specify in a segment declaration. Its alias is SEGMENT.
For a FOCUS data source, the segment name may consist of up to
eight characters. Segment names for an XFOCUS data source may have
up to 64 characters. You can use segment names of up to 64 characters
for non-FOCUS data sources, if supported by the DBMS. To make the
Master File self-documenting, set SEGNAME to something meaningful to
the user or the native file manager. For example, if you are describing
a DB2 table, assign the table name (or an abbreviation) to SEGNAME.
In a Master File, each segment name must be unique. The only
exception to this rule is in a FOCUS or XFOCUS data source, where
cross-referenced segments in Master File-defined joins can have
the same name as other cross-referenced segments in Master File-defined
joins. If their names are identical, you can still refer to them
uniquely by using the CRSEGNAME attribute. See Defining a Join in a Master
File.
In a FOCUS or XFOCUS data source, you cannot change the value
of SEGNAME after data has been entered into the data source. For
all other types of data sources, you can change SEGNAME as long
as you also change all references to it. For example, any references
in the Master and Access File.
If your data source uses an Access File as well as a Master File,
you must specify the same segment name in both.