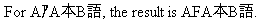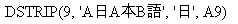The JPTRANS function converts Japanese specific characters.
x
Syntax: How to Convert Japanese Specific Characters
JPTRANS ('type_of_conversion', length, source_string, 'output_format')where:
- type_of_conversion
Is one of the following options indicating
the type of conversion you want to apply to Japanese specific characters.
These are the single component input types:
Conversion Type | Description |
|---|
'UPCASE' | Converts Zenkaku (Fullwidth) alphabets to
Zenkaku uppercase. |
'LOCASE' | Converts Zenkaku alphabets to Zenkaku lowercase. |
'HNZNALPHA' | Converts alphanumerics from Hankaku (Halfwidth)
to Zenkaku. |
'HNZNSIGN' | Converts ASCII symbols from Hankaku to Zenkaku. |
'HNZNKANA' | Converts Katakana from Hankaku to Zenkaku. |
'HNZNSPACE' | Converts space (blank) from Hankaku to Zenkaku. |
'ZNHNALPHA' | Converts alphanumerics from Zenkaku to Hankaku. |
'ZNHNSIGN' | Converts ASCII symbols from Zenkaku to Hankaku. |
'ZNHNKANA' | Converts Katakana from Zenkaku to Hankaku. |
'ZNHNSPACE' | Converts space from Zenkaku to Hankaku. |
'HIRAKATA' | Converts Hiragana to Zenkaku Katakana. |
'KATAHIRA' | Converts Zenkaku Katakana to Hiragana. |
'930TO939' | Converts codepage from 930 to 939. |
'939TO930' | Converts codepage from 939 to 930. |
- length
Integer
Is the number of characters
in the source_string.
- source_string
Alphanumeric
Is the string
to convert.
- output_format
Alphanumeric
Is the name of
the field that contains the output, or the format enclosed in single quotation
marks.
Example: Using the JPTRANS Function
JPTRANS('UPCASE', 20, Alpha_DBCS_Field, 'A20')
JPTRANS('LOCASE', 20, Alpha_DBCS_Field, 'A20')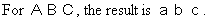
JPTRANS('HNZNALPHA', 20, Alpha_SBCS_Field, 'A20')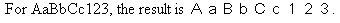
JPTRANS('HNZNSIGN', 20, Symbol_SBCS_Field, 'A20')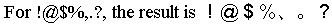
JPTRANS('HNZNKANA', 20, Hankaku_Katakana_Field, 'A20')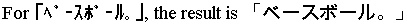
JPTRANS('HNZNSPACE', 20, Hankaku_Katakana_Field, 'A20')
JPTRANS('ZNHNALPHA', 20, Alpha_DBCS_Field, 'A20')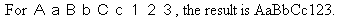
JPTRANS('ZNHNSIGN', 20, Symbol_DBCS_Field, 'A20')
JPTRANS('ZNHNKANA', 20, Zenkaku_Katakana_Field, 'A20')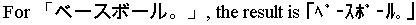
JPTRANS('ZNHNSPACE', 20, Zenkaku_Katakana_Field, 'A20')
JPTRANS('HIRAKATA', 20, Hiragana_Field, 'A20')
JPTRANS('KATAHIRA', 20, Zenkaku_Katakana_Field, 'A20')
In the following, codepoints 0x62 0x63
0x64 are converted to 0x81 0x82 0x83, respectively:
JPTRANS('930TO939', 20, CP930_Field, 'A20')In the following, codepoints 0x59 0x62
0x63 are converted to 0x81 0x82 0x83, respectively:
JPTRANS('939TO930', 20, CP939_Field, 'A20')