The database management system enables you to create
sophisticated hierarchical data structures. The following sections
provide information to help you design an effective and efficient
FOCUS data source and tell you how you can change the design after
the data source has been created.
x
The primary consideration when designing a data source
is the set of relationships among the various fields. Before you
create the Master File, draw a diagram of these relationships. Is
a field related to any other fields? If so, is it a one-to-one or
a one-to-many relationship? If any of the data already exists in
another data source, can that data source be joined to this one?
In general, use the following guidelines:
- All information
that occurs once for a given record should be placed in the root segment
or a unique child segment.
- Any information
that can be retrieved from a joined data source should, in most cases,
be retrieved in this way, and not redundantly maintained in two
different data sources.
- Any information
that has a many-to-one relationship with the information in a given segment
should be stored in a descendant of that segment.
- Related data
in child segments should be stored in the same path. Unrelated data should
be placed in different paths.
The following illustration summarizes
the rules for data relationship considerations:
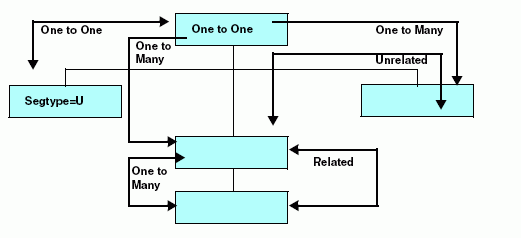
x
If you plan to join one segment to another, remember
that both the host and cross-referenced fields must have the same
format, and the cross-referenced field must be indexed using the
INDEX attribute. In addition, for a cross-reference in a Master
File, the host and cross-referenced fields must share the same name.
The name or alias of both fields must be identical, or else the
name of one field must be identical to the alias of the other.
xGeneral Efficiency Considerations
A FOCUS data source reads the root segment first, then
traverses the hierarchy to satisfy your query. The smaller you make
the root segment, the more root segment instances can be read at
one time, and the faster records can be selected to process a query.
You can also improve record substitution efficiency by setting
AUTOPATH. AUTOPATH is the automation of TABLE FILE ddname.fieldname syntax,
where the field name is not indexed, and physical retrieval starts
at the field name segment. AUTOPATH is described in the Developing Reporting Applications manual.
As with most information processing issues, there is a trade-off
when designing an efficient FOCUS data source: you must balance
the desire to speed up record retrieval, by reducing the size of
the root segment, against the need to speed up record selection,
by placing fields used in record selection tests as high in the
data structure as possible. The segment location of fields used
in WHERE or IF tests is significant to the processing efficiency
of a request. When a field fails a record selection test, there
is no additional processing to that segment instance or its descendants.
The higher the selection fields are in a data structure, the fewer
the number of segments that must be read to determine a record status.
After you have designed and created a data source, if you want
to select records based on fields that are low in the data structure,
you can rotate the data structure to place those fields temporarily
higher by using an alternate view. Alternate views are discussed
in Describing a Group of Fields.
For details on using alternate views in report requests, see the Creating Reports With WebFOCUS Language manual.
Use the following guidelines to help
you design an efficient data structure:
xChanging a FOCUS Data Source
After you have designed and created a FOCUS data source,
you can change some of its characteristics simply by editing the
corresponding attribute in the Master File. The documentation for
each attribute specifies whether it can be edited after the data source
has been created.
Some characteristics whose attributes cannot be edited can be
changed if you rebuild the data source using the REBUILD facility,
as described in Creating and Rebuilding a Data Source.
You can also use REBUILD to add new fields to a data source.