The Adapter for IDMS/DB retrieves the necessary records
that fulfill a request. It uses information from the following sources
to choose the most appropriate and efficient retrieval method:
The server uses the Master File to select segments and retrieve
data from them.
Note: Sections pertaining to unique segments discuss rules
that apply regardless of whether the unique segment is the owner
of its parent or is related to its parent through a CALC field,
index, or LRF field.
x
To retrieve records for a request, the server first
constructs a smaller subtree structure from the structure defined
by the Master File. The subtree consists of segments that contain
fields named explicitly in the request and those named implicitly
by DBA DEFINE or COMPUTE statements. The subtree also includes any
segments needed to connect these segments.
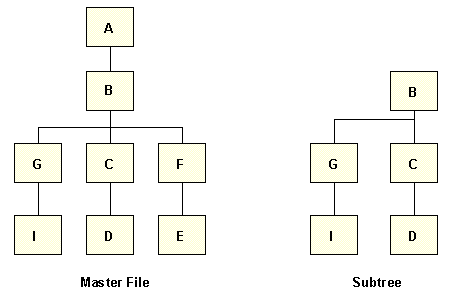
For example, if an SQL request needs fields from segments D,
G, and I, the server constructs the subtree diagram shown below.
Segments C and B do not contain fields needed for the request, but
they are included in the subtree to connect segment I with segments
D and G. Since the segments are descendants of segment B, the entry
or root segment of the subtree is segment B. The Master File root
segment A is not included, because its fields are not referenced;
the records corresponding to segment B can be obtained independently
of A. However, if segment B were an OCCURS segment, the IDMS/DB
calls would be issued for segment A to obtain information for B.
xRetrieval Sequence With Unique Segments
The retrieval sequence for subtrees containing unique
segments is still top-to-bottom, left-to-right, but the unique segments
are treated as extensions of their parents. Records in a unique
segment correspond one-to-one with the records in a parent. Records
in a non-unique segment have a one-to-many correspondence. In cases
where the parent segment has unique and non-unique descendants,
the unique descendants are always retrieved first regardless of
the left-to-right order.
A retrieval view shows which sort and WHERE clauses are valid.
For sort statements (BY or ACROSS), the segment containing the sortfield
must lie on the same path as the segments with all requested fields.
That is, the segment with the BY or ACROSS field must be an ancestor
or descendant of the segments containing the required fields.
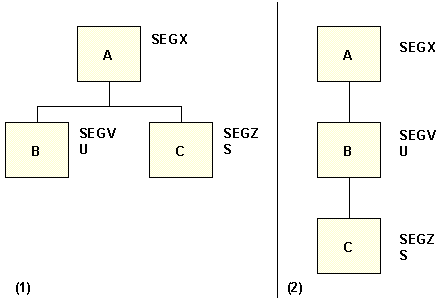
For instance, panel 1 of the following diagram shows two descendant
segments. The statement SELECT B ORDER BY C is invalid, because
the segments containing fields B and C do not lie on the same path.
However, if the segment containing B is a unique segment, the two
segments do lie on the same path. Panel 2 shows the retrieval view.
The statement SELECT B ORDER BY C is valid.
The retrieval sequence for unique segments may also affect the
results of an SQL statement that contains COUNT or SUM. If a segment
is the parent of a unique descendant, there is a one-to-one relationship.
A COUNT statement, such as COUNT A AND B, returns identical results
for each field, because the same record A is counted several times
for each record B. If the parent/descendant relationship is reversed
with a non-unique parent, the result for field A is a greater number
than the result for field B.
x
If a record in a segment fails a WHERE condition, the
server does not retrieve the corresponding records in descendant
segments. Suppose this request is entered against the structure
EMPSS01 (corresponding Master File is EMPFULL).
SELECT EMP_ID,OFF_CODE
FROM EMPFULL
WHERE DEPT_NAME = 'PERSONNEL'
ORDER BY OFF_CODE
Every time a record in segment DEPT has a value in the DEPT_NAME
field not equal to PERSONNEL, the server ignores the corresponding
records in descendant segments EMPLOYEE and OFFICE, and retrieves
the next record in segment DEPT. In addition, when a WHERE clause
on a lower segment fails, the row is removed from the server answer set.
To increase I/O efficiency, place the WHERE clauses at a higher
level in the file structure. This restricts the number of records
the server has to test. The example below shows the benefits of
two WHERE clauses versus one.
Assume a subtree has four segments:
- DEPT contains department IDs and information.
- EMPLOYEE contains employee names and IDs.
- EMPOSIT contains the positions that the employee has held.
- JOB contains a list of jobs offered by the company.
To list all employees who are programmer/analysts:
SELECT TITLE,DEPT,LAST_NAME,FIRST_NAME
FROM EMPFULL
WHERE TITLE = 'PROGRAMMER/ANALYST'
ORDER BY DEPT,LAST_NAME,FIRST_NAME
For this request with only one WHERE clause, the server retrieves
each DEPT record, each EMPLOYEE record for a given DEPT, each EMPOSIT
record for a given EMPLOYEE record, and the JOB record connected
to each EMPOSIT. After retrieval, the server determines whether
to include in the answer set the record from the value of the TITLE
field. To make retrieval more efficient, add another WHERE clause
on a segment higher in the structure. In this company, only the
Internal Software department has programmer/analysts working for
it:
SELECT TITLE,DEPT,LAST_NAME,FIRST_NAME
FROM EMPFULL
WHERE DEPT_NAME = 'INTERNAL SOFTWARE'
WHERE TITLE = 'PROGRAMMER/ANALYST'
Now the server retrieves and tests records only when the DEPT_NAME
field equals the value INTERNAL SOFTWARE.
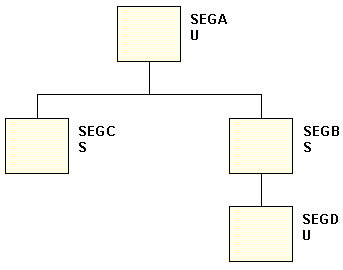
xScreening Conditions With Unique Segments
If a record in a unique segment fails a WHERE test,
the server rejects its parent and retrieves the next record of the
parent segment. For example, in the following diagram, if a record
in non-unique segment C fails a WHERE clause, the server retrieves
the next record in segment C. Only if all C records for a given
A fail the test is the A record rejected. When a record in unique
segment D fails a test, the server rejects the parent B record and
retrieves the next record in segment B. When a record in the entry
A segment fails a test, the server retrieves the next A record,
even if the entry segment is defined as unique.
x
When the server retrieves a record in a parent segment,
it retrieves the corresponding records in the descendant segment.
If descendant records do not exist, the processing of the parent
record and whether it is included in an answer set depends on whether
the descendant segment is unique or non-unique.
xShort Paths in Unique Descendants
For a unique descendant with a missing record, the server
creates a temporary record to replace the missing record. The temporary
record contains fields with default values: blanks for alphanumeric
fields and zeroes for numeric fields.
For example, an EMPLOYEE segment with the field EMP_NAME has
a unique descendant OFFICE segment with the field OFF_CITY. The
field OFF_CITY indicates the location of an employee office. Gary
Smith does not work out of an office location, so he has no OFFICE
record. In this situation, all requests that refer to OFF_CITY display
blank spaces for the entry GARY SMITH.
xShort Paths in Non-Unique Descendants
For a non-unique descendant segment with a missing record,
the server rejects the parent instance and retrieves the next parent instance.
x
Syntax: How to Specify Short Paths in Non-Unique Descendants
For
a non-unique descendant segment with a missing record, the results
depend on how the ALL parameter is set:
SET ALL = {ON|OFF}where:
- ON
The parent record is processed provided that there are no
screening conditions on fields in the descendant segment. Missing
data is usually indicated on the report by the default NODATA character
(.).
- OFF
The parent instance is rejected and the next parent instance
is retrieve. OFF is the default value.
Note: SET
ALL = PASS is not supported by the adapter.