Working With the New Data Model
As of PMF 5.3.2, the model where each individual measure needs
to be loaded as a separate, schedulable entity is no longer applicable.
Instead, PMF now allows you to group (and to schedule loads for)
your loadable data by its source.
You can specify how that data should be harvested from individual
physical data sources. You can:
- Harvest field values
directly, aggregating the values you acquire by dimensionality.
You can either aggregate all matching values or filter only particular
sets of values.
- Count occurrences
of particular flags on one or more fields per record in your source.
These counts are automatically kept at the dimensional levels, as
indicated on the loadable source.
- Distinctly count
occurrences of particular flags on one or more fields per record
in your source. These counts are automatically kept at the dimensional
levels, as indicated on the loadable source. Additionally, a distinct
count is applied on the field you indicate.
- Create custom formulas
to describe how data should be harvested, for more complex harvesting
techniques.
You can also specify that some datapoints are acquired from end
users. Typically, you do this if you do not already have a physical
source for this data, but want PMF to become the system of record
for the data and to track it as it is captured.
PMF provides user-input features that allow it to capture, update,
validate, and store the data in datapoints for use downstream.
When setting up user-entered sources, specify the level of dimensionality
common to all datapoints in a single source group. At capture time,
end users can input all datapoints at the same time, increasing
the speed and convenience for end users.
Once data has been harvested from physical sources or data has
been entered by the user, PMF can regularly recalculate any derived
datapoints. Recalculation is performed in lineage order. This means
that PMF itself determines which derived datapoints have dependencies,
and waits to perform recalculation on any datapoint until all of
its precursor dependencies have been resolved.
After all datapoints are reloaded, and derived datapoints are
fully recalculated, PMF checks for measure dependencies of these
datapoints. It then copies the data, as you designed it, to the
measures.
x
The new metrics model in PMF allows you to think differently
about measure loads than in previous versions of PMF:
- You can now time
a single source load to harvest all values needed from any particular
external RDBMS system. You no longer have to think about timing
multiple separate measure loads to events in external systems. PMF
determines the timing for you, harvesting the data at the time you
set, and then pushing the data downstream to derivations and then
to each dependent measure in the system.
- PMF now knows the
lineage of each calculation and the order in which each dependency
must be calculated, so you do not have to determine dependency order
for calculated fields.
- PMF can now mix user-input
data with loadable data. You do not have to create special interim
data tables and user interface schemas to accept user input that
needs to be combined on measures or subcalculations (either as separate
measure components or as dependent components in complex calculations).
- PMF can now synthesize
data at will, using rules that allow you to determine dimensional
depth and method of generation. This means that creating demonstrations of
new metric models does not require spending time generating data
in Excel and figuring out how to load that data into PMF.
- Determining dimensional
dependencies is now more automatic. Since dimensional dependencies
are attributes of sources and datapoints, just connecting datapoints
to a measure automatically determines the dimensions and levels
that will be available to that measure.
xMigrating to the New Architecture
PMF allows you to automatically migrate legacy measure load scripts
that were created prior to PMF Release 5.3.2 to the new architecture.
x
If you were a user of PMF prior to release 5.3.2, you
used legacy measures and set up loads directly on them. There were
no sources or datapoints. Automated Migration enables PMF to automatically
migrate all old measure components to use the new architecture.
- The migrator attempts to find common data sources for your
measures, examines the dimensional intersections these use, and
binds the ones that have common data sources and common dimensional
intersections into sources.
- When creating Sources during migration, the migrator names the
created sources sequentially. You can rename these sources at any
time after the migration completes.
- Naming of datapoints is based on the option you choose:
- You can choose to have PMF name the datapoints tied to these sequential
sources based on the source name.
- You can choose to name the datapoints after their linked measures.
Note: You can rename the created datapoints at any time
after migration is completed.
x
Should I Upgrade Legacy Measures?
Before upgrading legacy measures, take the following
into consideration:
- If you plan to use the new architecture features, immediately
migrate your data mart to use the new architecture. The PMF migrator
requires that you take an either/or approach. Once you begin creating
new-style measures, PMF will not be able to both preserve them and
to migrate your legacy measures for you.
- You should always run a snapshot before attempting migration.
This will enable you to quickly revert back to using legacy measures
and retrying migration with other options if the result is not what
you expected.
- If you want to continue to use legacy measures unchanged, note
that migration to the new architecture is currently an optional
step. PMF Release 5.3.2 supports legacy measures, as well as new
measures. It is strongly recommended that you upgrade to the new
model as the legacy measures are deprecated. The new model will
be required in a future release.
- Automated migration to the new architecture is not required
to upgrade the PMF data mart version. That operation is done when
you first start log in to PMF as an administrator after upgrading.
x
Procedure: How to Perform a Migration
Before
performing a migration, note the following:
- You should
always run a snapshot before attempting migration. This will enable
you to quickly revert back to using legacy measures and attempting
another migration, with other options, if the results of the initial
migration are not what you expected.
- It is recommended that you use migration using the default options
and then examine the results. If the results are now what you expected,
restore your backup snapshot and perform the migration again after
tweaking the options.
- If you were using PMF prior to release 5.3.2, it is not recommended
that you add any new sources, datapoints, or measures to PMF until
you complete the legacy migration. If there are already existing
sources, datapoints, or new measures, the migration operation will
quit. You can delete these components before performing the migration
using the option available, but this is not advised if you spent
a lot of time in the new architecture.
To perform a
migration to the new architecture:
-
From the Manage tab, click the Data Mart subtab.
-
Click Migrate Legacy Measures.
The Migrate Legacy Measures to New panel opens, as shown in the
following image.
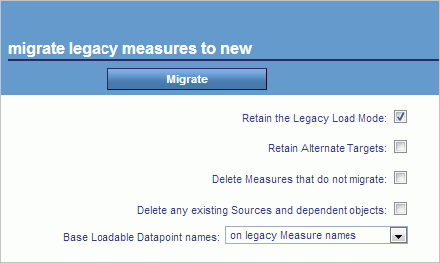
The
following options are available:
-
Retain the Legacy Load Mode
-
Enable this option to transfer the deletion option used by
the migrated measures into its equivalent default Wipe setting on
the sources to be created. This setting is enabled by default.
-
Retain Alternate Targets
-
If you are using Alternate Targets (for example, Benchmark,
Stretch, Budget, and Forecast targets), enable this option to make
sure that they are migrated.
If you are not using Alternate
Targets, it is recommended that you leave this option disabled.
This is the default setting.
-
Delete Measures that do not migrate
-
If enabled, the migrator will delete any measures that do
not migrate. It is recommended that you select this option after
doing a test migration and determining that it is safe to do so.
This option is disabled by default.
Note: Generally,
legacy measures that are incomplete will not be migrated, since
PMF does not have any way to map these into the new architecture. You
can always choose not to delete these, manually set them up as new
measures, and then delete the unconverted legacy measures.
-
Delete any existing Sources and dependent objects
-
If enabled, the migrator will delete any existing sources
and datapoints that were created using the new architecture. This
will delete any new sources, datapoints, and measures in your system.
If
you have this option disabled, and you have new measures, existing
sources and existing datapoints, the migrator will produce an error.
This is to prevent the overwriting of any new components. This option
is disabled by default.
-
Base Loadable Datapoint names
-
The following options are available:
-
on legacy Measure names. This
option names loadable datapoints created in each source using the
names of the measures to which the migrator links them.
-
on new Loadable Source names. This option names loadable datapoints
created in each source using the source name, so that the names contain
the Master File information.
-
Click Migrate.
PMF will perform the migration. This operation can take
a few minutes and it is important to wait until it is complete before
performing another operation. Once done, a status message will confirm
that migration is completed.
-
Once the migration is done, return to the Manage tab
and review the results.
x
Data lineage refers to the entire path of data through the PMF
load architecture.
Step 1
For PMF, data lineage starts at the source. Datapoints that are
linked to a source are left-side endpoints in the lineage. This
means they are harvested directly from:
- Physical database
tables or views, or various flat file formats.
- User entry of data,
in situations where there is no physical representation of the data.
- Generated data (in
the exception where no data exists, and is being created for various
demonstration purposes).
Example 1: In the case of a manufacturing company, there
might be sources defined to harvest data from systems in Warehousing,
Production Line, Quality Control, Shipping and Logistics, Supply
Chain/Purchasing, Prospect Management, and Wholesale Sales. PMF
harvests data as follows:
-
Warehousing. Average
cost of storage per item, per warehouse.
-
Production Line. Average
cost of labor per item, per plant.
-
Quality Control. Average
cost of testing, per item, per plant.
-
Shipping and Logistics. Cost
to ship, per item, per plant, per customer.
-
Supply Chain/Purchasing. Cost
of supply, per item, per plant.
-
Prospect Management. Average
Cost of Customer Acquisition, averaged per item, per customer.
-
Wholesale Sales. Sale
Amount, per item, per customer.
Step 2
Lineage then proceeds through each generation of derived datapoints.
There is no limit to the number of phases possible.
Example 2: Continuing from Example 1, you can derive the
following datapoints from those you loaded:
- Total Product Cost
= Average cost of storage per item + Average cost of labor per item
+ Average cost of testing, per item
- Total Sale Cost =
Average Cost of Customer Acquisition + Shipping Cost
- Net COGS = Total
Product Cost + Total Sale Cost
- Profit = Total Sale
– Net COGS
- Margin = Profit/Total
Sale (as a %)
These datapoints need to be calculated in the following order:
- Total Product Cost,
Total Sale Cost
- Net COGS
- Profit
- Margin
Step 3
Lineage then ends at measures.
xLoad, Recalculate, and Copy (LRC) Loads
To load measures, the PMF load architecture puts data through
three phases:
-
Load. All
sources indicated for Load are loaded and data is fed into the datapoints
for each source.
-
Volitional load. The
Load button is clicked on any source. In this case, the only source
that will be loaded is the one you indicated for load.
-
Scheduled direct load. A
source load is scheduled to run at that time.
-
Scheduled optional cascaded load. If
any of the dimensions that are linked to the source are reloaded,
a source load could be forced (cascaded) depending on how the dimension
Cascade Load settings are configured.
-
Scheduled forced cascaded load. If
any of the dimensions that are linked to the source are reorganized,
a source load will always be forced (cascaded), regardless of how
the dimension Cascade Load settings are configured.
Note: During
schedule processing, if more than one source has to be loaded during
the scheduled run, all scheduled sources would be loaded before
the next step runs. This prevents inefficiently repeating the recalculation.
-
Recalculate. PMF
looks at all the sources that were reloaded, and analyzes all derived
datapoints with dependencies on the sources that were loaded. PMF
then analyzes the lineage of all derived datapoints to determine
the correct order to recalculate them, respecting their dependencies.
Finally, PMF performs the recalculation step, in phases, with the
number of phases determined by the generations of lineage of the
derived datapoints.
-
Copy. PMF
analyzes all measures that use the datapoints that were recalculated
in Step 2. It then copies the data for the linked datapoints into
the measures cube, making the data ready for reporting and dashboard publication.
x
Reference: Checking the Administrative Log Reports
PMF
logs all activity that involves load, recalculation, or copy actions.
Logged data is stored as peer data in the PMF Data Mart.
PMF captures the following data in its
source load logs:
- Earliest and latest
effective dates for the source data.
- What dimensions were
processed on the load.
- Status of the load:
- Running: The load
is currently running.
- Success: The load
completed successfully.
- Error: The load operation
completed with an error thrown.
- How many source records
were retrieved to process the load.
- How many datapoint
records were inserted, updated, and deleted.
- How many dimensional
linkage mismatches were processed.
- Gaps in dimensional
intersections.
- Datapoint sparsity
count (how much of the potential total Cartesian cross product was
not loaded).
- LRC load type:
- Load a source.
- Load a datapoint.
- Recalculate.
- Copy to measure.
- Owner ID under which
the load ran.
- Start and end time
of the load.
- Messages that were
returned from the server during the load.
- Compare mode that
was flagged for the load:
- NO_DATA: There is
no incoming/parent data ready to process.
- NEW: All ready parent
data is new (outside the range of the target data), and all parent
data is in the lineage for all incoming datapoints for at least
one common time period.
- NEW_W_MISSING: All
ready parent data is new (outside the range of the target data),
but data is missing for at least one required parent data point
in the lineage.
- POSS_UPD: All incoming
ready data falls within the range of current data, but there is
no ready data for at least one incoming data point. There is no
possibility of new rows being generated.
- For Copy to Measure,
there are possible updates.
- For Recalculation,
there are also possible updates if there is available data for all
other parents (this has not yet been coded).
- It is possible that
there is some ready data that is new for some parents, but not for
all parents. Since we are lacking new data for at least one parent,
there can be no new processing.
- POSS_UPD_NEW: Similar
to POSS_UPD, except that there is ready data for all parents in
the lineage, so it is possible that there is some new data.
The
most likely scenario for this would be that you source loaded EAST
for 2012/01 and then separately source loaded WEST for 2012/01.
In order to process the POSS_UPD_NEW mode, you need to split out
those incoming or parent rows that match the dimensionality existing/child
rows versus those that are new. For those that are new, you have
to check for gaps.
- MIXED: Similar to
NEW, except there is also some ready parent data which overlaps
existing data. For incoming data that falls within the range of
existing data, it is possible that:
- The data will not
be in the current child data, in which case, the data will be New
provided that there is already data in all required parents.
or
- It may be that the
child data already exists, in which case, we can do C2M update processing
OR recalc updates (if there is available data for all other parents).