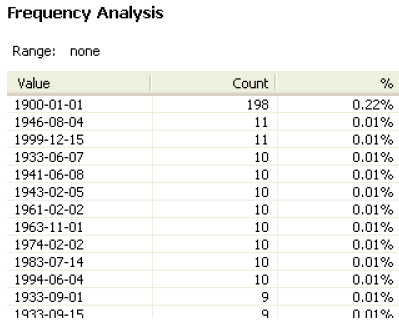
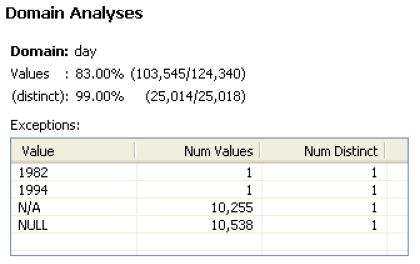
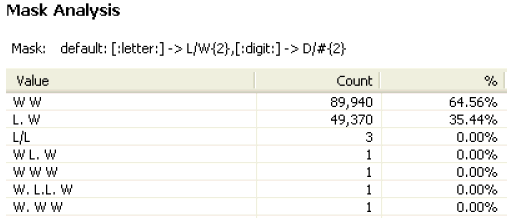
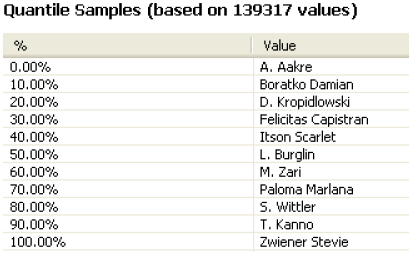
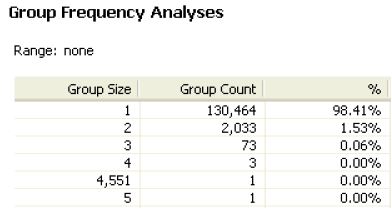
The Basic tab provides simple statistics about the data that has been profiled and shows a chart of duplicate and distinct data as a percentage of the whole.
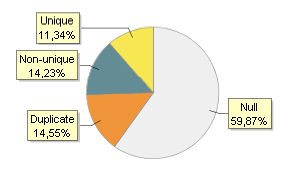
Some of this data is shown in the Basic tab of the Profile viewer.
The Counts table lists the following values:
- Null. This value refers to all data that is empty or have Null as their value.
- Non-null. This value refers to all data that is not empty or null (duplicate + distinct).
- Duplicate. This shows the number of values that are the same as other values in the list.
- Distinct. This refers to the number of non-null values that are different from each other (non-unique + unique).
- Non-unique. This is the number of values that have at least one duplicate in the list.
- Unique. This is the number of values that have no duplicates.
The following data table is an example that illustrates the meaning of the above values.
|
Record No. |
Value |
|---|---|
|
1 |
John Smith |
|
2 |
John Smith |
|
3 |
Rebecca Davis |
|
4 |
Paul Adams |
|
5 |
The following table shows the Counts for this data.
|
Type |
Count |
Records |
Explanation |
|---|---|---|---|
|
Null |
1 |
Record 5 |
The last record is empty. |
|
Non-null |
4 |
Records 1-4 |
The first four records contain data. |
|
Duplicate |
1 |
Record 2 |
There is one duplicate of the John Smith record. |
|
Distinct |
3 |
Records 1, 3, 4 | |
|
Non-unique |
1 |
Record 1 |
John Smith has a duplicate record, and is therefore not unique. |
|
Unique |
2 |
Records 3 and 4 |
Rebecca Davis and Paul Adams appear only once in the list. They have no duplicates. |