Document functions access information pertaining to
the current document being processed.
x
_docinfo(): Information About the Current Document
The _docinfo() function returns information about the
current document (message) that is passing through the process flow.
Some document information can also be obtained using other functions,
such as _iserror(). The _docinfo() function uses the following format:
_docinfo(type)
type | String | Determines what information is required
from the document. The following types are supported: - encoding. Returns the current encoding that is being
used for the message. If the document arrived with a declared encoding,
then that encoding is returned. Otherwise, the default encoding
of the channel is returned.
- xmlversion. The XML version of the document, which is
applicable to XML only. Returns 1.0 or 1.1.
|
In the following example, the message being received in an arbitrary
encoding is to be converted to Base64 encoding:
_base64(_docinfo('encoding'))
x
_isroot(): Tests Element Root
The _isroot() function returns true if the root of the
current document matches the parameter. It uses the following format:
_isroot(name)
name | string | Name to be compared to the root element |
The _isroot() function is often used to drive a routing decision,
such as _root('a') or _root('b') to cause the route to be selected
for any document with a root of 'a' or 'b'.
x
_root(): Returns the Root Element Name
The _root() function returns the root element name of
the current document. It uses the following format:
_root()
This is equivalent to the _xpath function _xpath(/*/name()).
It might be used in a routing decision, such as _cond(_root(),eqc,'a')
which selects the route for documents with roots of 'a' or 'A'.
x
The current document can hold either XML or non-XML
information. The _isxml function returns true if the current document
holds XML. If the document has no contents, this function returns
false. It uses the following format:
_isxml()
x
_isflat(): Test for Non-XML
The current document can hold either XML or non-XML
information. The _isflat function returns true if the current document
holds non-XML. If the document has no contents, this function returns
false. It uses the following format:
_isflat()
x
_iserror(): Is the Document in Error State?
The current document can have errors posted to it by
the system, or can be set into an error state by the actions of
an application process. If the document is in error state, default
replies are delivered to the configured error addresses, otherwise
they are delivered to the configured reply addresses. The _iserror()
function returns true if the document is in error state. It uses
the following format:
_iserror()
x
_hasruleerr(): Test for Rule Violations
As the document passes through its execution route,
a supplied rules-based validation system can be employed. Often
the rules relate to eBusiness documents such as SWIFT or EDI. If
the rules system has posted a validation error to this document, the
_hasruleerr() returns true. It uses the following format:
_hasruleerr()
x
_hasschemaerr(): Test for Schema Rule Violations
Certain rules and services can detect schema violations
during the life of a document in the system. Whether such a violation
has been detected can be tested with this function. A common use
of this function is in a process flow test object. This function uses
the following format:
_hasschemaerr()
x
_iswellformed(): Test for XML
The current document can hold either XML or non-XML
information. This function returns true if the current document
holds XML or holds flat information that can be parsed into XML.
If it has not been parsed, a true response from this function assures that
the message can be parsed into XML. It uses the following format:
_iswellformed()
x
_iseos(): Is Document at End of Stream
Streamable input is used for handling large documents
or documents for which the application desires to split the input
into sections under the same transaction. Following the completion
of the input stream handling, a final pass is made with a special document
containing batch information:
<batch count='n'/>
The end of stream can also be tested with the _iseos() function.
A common use of this function is in a process flow test object.
This function uses the following format:
_iseos()
Creating a Process Flow to Test for an End of Stream Document
Splitting and streaming or splitting preparsers generate a special
control document at the end of a batch to indicate that this batch
was completely processed. This End of Stream document is a non-data
XML document that is passed into a channel after all data documents.
The _iseos() function will return as true if the current document
contains an End of Stream message, else it will return as false.
The End of Stream document may also contain additional statistics
about the splitting process, such as how many iWay documents were
generated from the batch.
To create a process flow using iWay Designer to test for an End
of Stream document:
- Create a process
flow and add a new Test object.
- Configure
the parameters for this Test object, as shown in the following image.
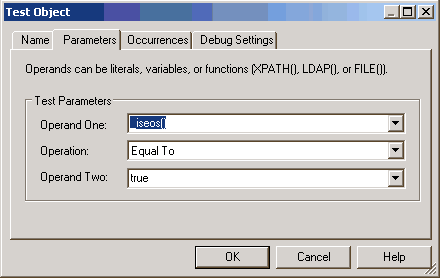
- Add a new
Service object to the process flow that uses the QAAgent.
- Configure
the parameters for this Service object, as shown in the following
image.
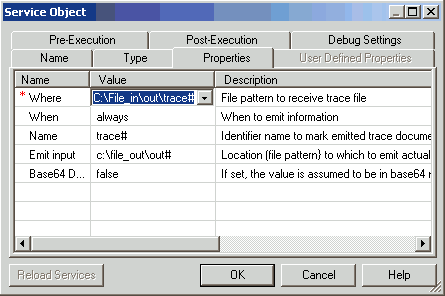
- Connect the
Service object to the True edge of the Test object.
The new process
flow should have a structure that resembles the example in the following
image.
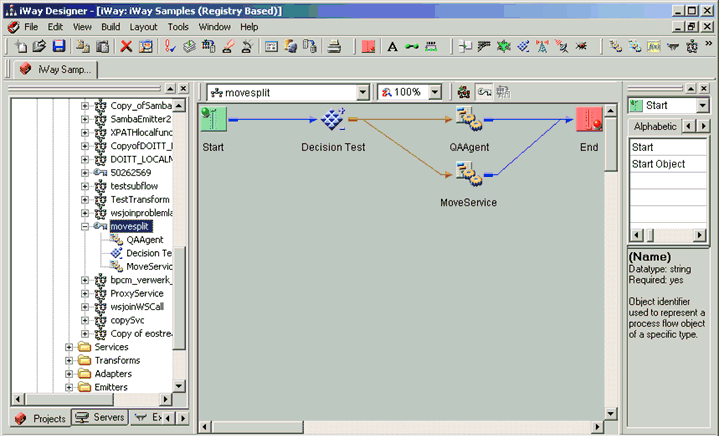
- Using the
iWay Service Manager Administration Console, create a channel that consists
of an XMLSplitpreparser as an inlet, which would return an End of
Stream document when the last pass is reached.
- Add a route
to the channel that consists of the process flow, which was created using
iWay Designer.
- Add an outlet
to the channel.
The new channel should have a structure that resembles
the example in the following image.
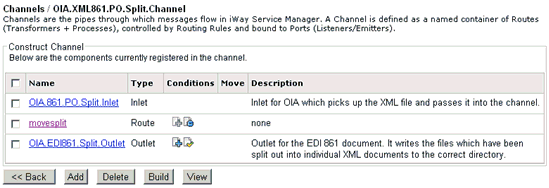
- Use the following
input document to test your channel with /a/b as the level string:
<a>
<b name="b1">
<c>value of input element a/b@name=b1/c is 1</c>
<c>value of input element a/b@name=b1/c is 2</c>
</b>
<b name="b2">
<c>value of input element a/b@name=b2/c is 3</c>
<c>value of input element a/b@name=b2/c is 4</c>
</b>
</a>The _iseos() functions returns as true
at the third (last) pass and a trace file is created which displays
the End of Stream document.
x
_xpath: Execute an XPATH Expression
The xpath() function is always an alias for one of the
supported xpath functions: xpath1() or _iwxpath(). By default, xpath()
is an alias for _iwxpath() but through compatibility flags, it can
be made to alias xpath1().
The _xpath() function uses the following format:
_xpath(expression [,nsmap [,object]])
x
_xpath1: Execute an XPATH Expression
The document is evaluated by the provided xpath expression.
The start is always considered to be the root, so all expressions
are assumed to begin with '/'.
The purpose of the xpath in the context of functions is to extract
values from an input document to be used as configuration parameters.
This use of xpath is not intended for general XML tree manipulation.
In some servers, xpath is a full xpath version 0 as specified
by XML Xpath Language http://www.w3.org/TR/1999/REC-xpath-19991116,
while others support only the portion of xpath specified in section
2.5, Abbreviated Syntax.
The _xpath1() function uses the following format:
_xpath1(expression [,nsmap [,object]])
expression | string | Expression in xpath language. |
nsmap | string | Name of a namespace map from
a provider. If omitted, no namespace map is applied. |
object | document | A document to which xpath is applied. If
omitted, the current document is evaluated. |
x
_xflat: Generate a Subtree
The _xflat() function is always an alias for one of
the supported _xflat() functions:
By default, xflat() is an alias for _iwxflat(). However, by using
compatibility flags, it can be made to alias xflat1().
x
_xflat1: Generate a Subtree
The _xflat1() function uses the following format:
_xflat1(expression [,nsmap [,object]])
expression | string | An XPATH expression. |
nsmap | string | The name of a namespace map from a provider.
If omitted, no namespace map is applied. |
object | document | A document to which XPATH is applied. If
omitted, the current document is evaluated. |
The current document is evaluated by the provided XPATH expression.
As with XPATH, the root of the current document is the starting
point. The subtree addressed by this expression is returned in a
flattened form that is suitable for reparsing.
The specific parameters are discussed under _xpath: Execute an XPATH Expression. The _xflat1() function is often
used to provide document segments in the constant value service
leading into a join. For example:
<a>
<top>
<b>one</b>
<b>two</b>
<x>
<xroot>
<xchild>rootchildvalue</xchild>
</xroot>
</x>
</top>The expression _xflat1(//xroot) yields the subdocument:
<xroot>
<xchild>rootchildvalue</xchild>
</xroot>
x
_iwxflat: Generate a Subtree
The _iwxflat() function uses the following format:
_iwxflat(expression [,nsmap [,object]])
expression | string | An XPATH expression. |
nsmap | string | The name of a namespace map from a provider.
If omitted, no namespace map is applied. |
object | document | A document to which XPATH is applied. If
omitted, the current document is evaluated. |
The current document is evaluated by the provided XPATH expression.
As with XPATH, the root of the current document is the starting
point. The subtree addressed by this expression is returned in a
flattened form that is suitable for reparsing.
The specific parameters are discussed under _xpath: Execute an XPATH Expression. As is the case with _xpath(),
this function is faster but not as fast as the standard _xflat1()
function. The _iwxflat() function is often used to provide document segments
in the constant value service leading into a join. For example:
<a>
<top>
<b>one</b>
<b>two</b>
<x>
<xroot>
<xchild>rootchildvalue</xchild>
</xroot>
</x>
</top>The expression _iwxflat(//xroot) yields the subdocument:
<xroot>
<xchild>rootchildvalue</xchild>
</xroot>
x
_flatof: Flatten the tree
The current document is flattened. If the current document
is XML, the decl parameter determines whether an XML declaration
will be included in the flattened output. The default is true. The
_flatof() function uses the following format:
_flatof([decl])
decl | boolean | Is an XML declaration desired? |
x
_attcnt: Index Attachments
Documents can hold attachments. This function has two
forms. When used with no parameters, it returns the number of attachments
associated with the document. When used with two parameters, it
returns the index of the first attachment having the named header
equal to the specified value. The _attcnt() function uses the following
format:
_attcnt([name,value [,notfound]])
name | string | Name of an attachment header |
value | string | Value of the named header |
notfound | string | What to return if the named attachment header
is not found |
x
_atthdr: Attachment Header Value
The _atthdr() function returns the value of a specific
header in the attachment. The IC (independent case) form tests the
attachment header names in a case independent fashion. Number 0
is the first attachment. The _atthdr() function uses the following
format:
_atthdr(index, name, default)
_atthdric(index, name, default)
index | integer | Index of the attachment, base
0 |
name | string | Name of the header desired |
default | string | Default if header not found |
When the _atthdr() function is used in a conditional expression
in comparison against a string value, the default value must be
specified.
For example, the following conditional expression would not compile,
since it requires a default value in the expression:
COND(_atthdr(1,'mysample'),eq,'a')
Instead, the expression must be specified as follows:
COND(_atthdr(1,'mysample','defaultval'),eq,'a')
For example, to return the first header in the attachment, _atthdr(0,'mysample') could
be used.
x
_srcname: Source Name from Subflow
The _srcname() function returns the name of the terminate
(end node) of the subflow through which the document reached the
calling process flow. This allows the subflow to communicate information
back to the parent flow.
Imagine a subflow that performs some operation that results in
one of three possible situations:
- Success.
- Failure by a security violation.
- Connection error.
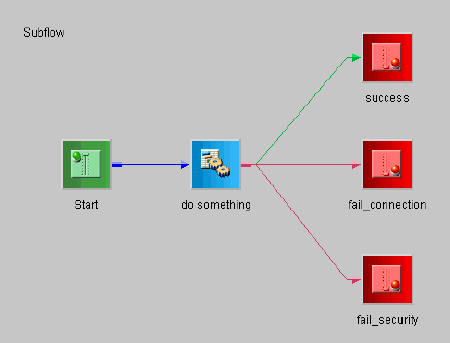
The parent flow calls the subflow, and wishes to deal with the
result from that flow. Within the subflow, the document that is
produced is returned through a terminate or end node, as shown below.
The name of that terminate node becomes the edge name followed by
the returned document. As this example shows in the image below,
there are three activities (called do_<something>) in the
outer flow, each of which handles the result returned from the inner
subflow.
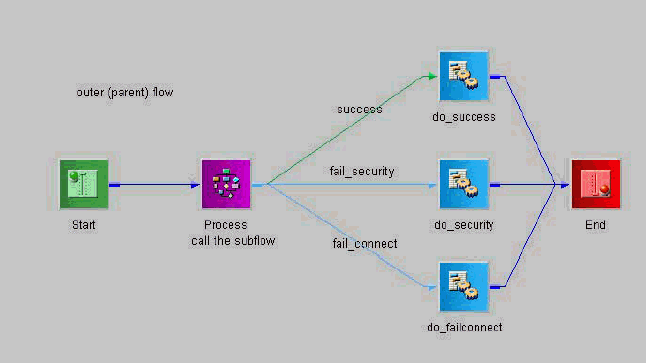
If the subflow returns multiple documents, each follows the edge
of its own name. If more than one of any name is returned, the documents
are associated as siblings, and can be split later using the sibling
iterator. The source name can be used in a switch statement for
more detailed routing.
x
_iwxpath: Execute an XPATH Expression
_iwxpath(expression)
expression | string | Expression in xpath language |
The current document is evaluated by the
provided xpath expression. The start is always considered to be
the root, so all expressions are assumed to begin with forward slash
(/).
The purpose of the xpath in the context of functions
is to extract values from an input document to be used as configuration
parameters. This use of xpath is not intended for general XML tree
manipulation.
The xpath language supported is specified in
XML Xpath Language http://www.w3.org/TR/1999/REC-xpath-19991116,
section 2.5, Abbreviated Syntax.
In those servers not providing
full xpath support, both xpath and _iwxpath are identical. In other
servers, it can be expected at _iwxpath should operate faster than
full xpath. iWay recommends use of full xpath if _iwxpath does not
provide the required services or results.
x
_xpath1: Execute an XPATH Expression
_xpath1(expression [,nsmap [,object]])
expression | string | Expression in xpath language |
nsmap | string | Name of a namespace map from
a provider. If omitted, no namespace map is applied. |
object | document | A document to which xpath is applied. If
omitted, the current document is evaluated. |
The purpose of the xpath in the context
of functions is to extract values from an input document to be used
as configuration parameters. This use of xpath is not intended for general
XML tree manipulation.
The nsmap is the name of a namespace
provider. Namespace providers relate the namespace portion of the
xpath expression to the URI to which it relates. The xpath execution
engine will map the URI to the namespace tokens used in the document
being evaluated.
If the object parameter is omitted, the xpath
is applied against the current document. Otherwise, this must be
the name of a special register holding a document or a register
itself holding a document.
In some servers, xpath is a full
xpath version 1 as specified by XML Xpath Language http://www.w3.org/TR/1999/REC-xpath-19991116,
while others support only the portion of xpath specified in section
2.5, Abbreviated Syntax. iSM Version 7.0 supports full XPATH per
the specification.
In some cases, XPATH syntax can be confusing.
Consider a document in a default namespace:
<root xmlns='http://someuri.com'>
<child name='whoami'/>
</root>A request for the child name would appear
to be //child/@name, and if there were no default namespace, this
would work as expected. For the anonymous namespace, a solution
is one.
The default namespace throws in a twist. The XPath
specification states the following:
A node test that is
a QName is true if and only if the type of the node (see [5 Data Model])
is the principal node type and has an expanded-name equal to the
expanded-name specified by the QName.
This means that
an XPath processor does not deal with plain element names, except those
element names for which no namespace has been declared. If there
is any namespace declaration at all, including one for the default
(unprefixed) namespace, the processor uses the expanded-name.
//*[namespace-uri()="http://someuri.com" and local-name()="child"]/@name
Alternatively,
create a namespace provider name, for example, empty1. Add a specification
for a namespace, such as:
Then use an _xpath statement, such as the following:
_xpath(/none:root/none:child/@none:name,empty1)
The
processor will map the none namespace to the URI in the statement
and select the proper nodes from the document.
x
XPATH Language support is an important feature of iWay
and is used in a number of areas within the server. XPATH is a non-procedural
language used to access and manipulate sections of an XML document.
The XPATH expression gathers information from the document, as if
the XML document is a self-contained hierarchical database. The
XPATH expression specifies levels (segments or fields), filter predicates,
and functions on the XML document data. The result of the XPATH
can be one or more values, a set of XML nodes, or a particular location
in the XML structure. Using these XPATH results, iWay Service Manager can
control the behavior of service agents, conditional routing, and
decision-making inside of process flows. iWay Service Manager implements
a subset of the XPATH location steps, predicates, and functions,
which are expressed using abbreviated syntax. The fully proposed XPATH
Language specification and information on the abbreviated syntax
can be found at:
http://www.w3.org/TR/xpath.html
x
Navigating XML With Location Steps
In iWay Service Manager, the node context from which
location steps begin is always the root of the document. Furthermore,
only the child axis is implemented and is implicit in all iWay XPATH
location steps.
x
Reference: Location Steps
|
Expression (phrase)
|
Action
|
|---|
|
/name
|
Locate down one level, selecting children
of the specified name.
|
|
//name
|
Locate down, selecting children of the specified
name regardless of the depth.
|
|
/*
|
Locate down, selecting all children.
|
|
//*
|
Locate down, selecting all children.
|
|
/.
|
Locate all nodes that are already selected.
|
|
/..
|
Locate upward one level, selecting the parent
of each node in the node-set.
|
The
result of the location step phrase can be a set of XML document
nodes consisting of zero, one, or many nodes. This set of nodes
is referred to as a node-set. This node-set is provisional and may
not be the final node-set returned by the XPATH expression, depending
on subsequent predicates.
x
iWay supports two XPATH processors with different characteristics. Selecting
the right one for any specific situation can greatly improve the
performance of an application.
_iwxpath(). This is an XPATH processor provided by iWay.
It supports a limited subset of the XPATH language. If your document
and query are appropriate to using _iwxpath, you can expect to
achieve significant performance improvements. However, the limitations
of this process are:
-
Very limited function
support.
-
No advanced XPATH
features such as math.
-
Surrounding functions
such as count() are not supported.
-
Conjunctions
(such as OR and AND) and complex tests are not supported.
-
Namespaces are
not supported.
Note: For most applications, these omitted features are
not used. If _iwxpath() does not return the results you desire,
use _xpath1().
_xpath1(). This is the full XPATH. It may be slower for
certain operations, but it does provide the complete language support
of XPATH version 1.
_xpath(). This is the default xpath call. Whether it
calls _iwxpath() or _xpath1() depends on a configuration setting
on the iSM console.
In general, it is best practice to write your xpath expressions
as simply as possible. Avoid expressions that may return multiple
results when you are not expecting them. Selecting any (*) can slow
down any XPATH processor, as well as the //. Use these language
constructs if they are needed, but understand that there may be
a penalty in performance.
x
Predicates are written after the location step, and
are enclosed in square brackets. There can be one or more predicates
in a step, each of which is applied left to right to control the
membership of the node-set.
A predicate filters the node-set implied by a location step,
to produce a new node-set. For each node in the node-set to be filtered,
the predicates are evaluated with that node. If predicate expression
evaluates to true for that node, the node is included in the new
node-set. Otherwise, it is not included.
Multiple predicates are written as sequential predicate terms
and are applied left to right, behaving as if connected by a logical
AND:
/Book[Author='Smith'][Price<10]
Each predicate term consists of a single integer, a filter function,
or a relation of the form.
<left-value> operator <right-value>
A predicate can hold any number of terms, logically connected
by AND and OR. The specification calls for left to right precedence,
with AND taking higher precedence than OR. Terms may be grouped
by parenthesis to force a particular order of evaluation. For example, the
predicate [a=b OR c=d AND e=f] is evaluated as [a=b OR (c=d AND
e=f)].
Integer predicates of the form /Tag[2] imply a numeric index
into the current node-set (in this case, selecting the second node).
x
Reference: Comparison and Logical Operators
|
Symbol
|
Description
|
Example
|
|---|
|
=
|
Equal
|
//*[local-name(CustomerRecord/RecordDate)='OrderRecord']
|
|
!=
|
Not Equal
|
//*[local-name(CustomerRecord/RecordDate)!='OrderRecord']
|
|
<
|
Less than
|
/OrderRecord/LineItems[position() < 5]
|
|
<=
|
Less than or equal
|
/OrderRecord/LineItems[position() <=
5]
|
|
>
|
Greater than
|
/OrderRecord/LineItems[position() > 5]
|
|
>=
|
Greater than or equal
|
/OrderRecord/LineItems[position() >=
5]
|
|
Or
|
Logical Or
|
OrderRecord[salesman = 'Jones' or salesman='Scott]
|
|
And
|
Logical And
|
OrderRecord[salesman = 'Jones' and salesman='Scott]
|
|
Not
|
Logical Not
|
/a//*[not(starts-with(name(),'d'))]
|
x
Reference: Predicate (filter) Functions
|
Expression
|
Description
|
|---|
|
starts-with(string1, string2)
|
Returns true if the first string starts
with the second string, otherwise returns false.
|
|
ends-with(string1, string2)
|
Returns true if the first string ends with
the second string, otherwise returns false.
|
|
contains(string1, string2)
|
Returns true if the first string is contained
within the second string, otherwise returns false.
|
In
each of the preceding filter functions, string1 may be name(), @attribute,
@* (all attributes) or the name of the child node.
x
A collection of functions is provided to operate on
nodes and node-sets. A function operates on the current context
(for example, the current node) or on characteristics of the current
node-set, and returns a single value.
x
|
Function
|
Description
|
|---|
|
count(<node-set>)
|
Returns the number of nodes in the specified
node-set.
|
|
last()
|
Returns the position number of the last
node in the context node-set.
|
|
position()
|
The position of a node in the node-set relative
to its parent.
|
|
count()
|
The number of children of each node in the
node-set.
|
|
text()
|
Returns the value of each node in the node-set.
Also used to return the value of CDATA.
|
|
name()
|
Returns the name of the nodes in the selected
node-set. Example //sql/*/name() returns the names of the grandchildren
of each sql node.
|
|
local-name
|
Returns the local name of each node in the
node-set.
|
|
sreg(name[,default])
|
The value of a named special register (iWay
extension to XPATH).
|
|
@attrib, @*
|
Returns the values of the specified attribute,
* returns the set of all attribute values.
|
|
concat(string1, string2)
|
Returns the concatenation of all its arguments.
Two or more strings may be concatenated.
|
|
Substring(string, position, length)
|
Returns the substring of the first argument
starting at the position specified in the second argument with length specified
in the third argument.
|
|
Substring-before(string1, string2)
|
Returns the substring of string1 that precedes
the first occurrence of string2 in string1, or the empty string
if string1 does not contain string2.
|
|
Substring-after(string1, string2)
|
Returns the substring of string1 that follows
the first occurrence of string2 in string1, or the empty string
if string1 does not contain string2.
|
|
namespace-uri()
|
Returns the namespace URI of each node in
the node-set.
|