Migration Issues and Usage Considerations
This section describes migration issues and provides
usage considerations when migrating from an iSM 5.x release to 6.x.
x
The previous releases attempted to accommodate XML documents
that were pretty-printed. Extra whitespace between sub-elements
was eliminated. Unfortunately, this behavior is not compliant with
the XML 1.0 specification and makes many XML activities such as
XML Digital Signatures impossible to implement.
In 6.x, each listener now offers a new property called Whitespace
Normalization. The two choices are trim or preserve.
Trim selects the prior iWay behavior. Preserve returns every character
as it appeared in the original document.

New listeners created in 6.x will preserve whitespace by default
unless manually changed to trim. Older listeners that do not specify
a value for the property will continue to trim whitespaces.
One of the effects of preserving whitespaces is the increased
likelihood to produce mixed element content (text nodes alternating
with sub-elements). The most common form of mixed content is a pretty-printed
document. Some applications might see unexpected results in 6.x
if they attempt to pretty-print documents. For example, a document
can appear double-spaced because the parser preserved the input
indentation and the serializer added extra indentation later.
<root>
<sub>text</sub>
<sub>text</sub>
</root>An even more surprising result appears if the application attempts
to pretty-print the document by programmatically adding carriage
returns inside text values. To preserve these characters for digital
signatures, they must be converted to character entities (
) essentially
defeating the attempt to make the document look pretty.
<root>
<sub>text</sub>
<sub>text</sub>
</root>
Mixed content could be created even when trimming has been turned
on. This will happen every time non-whitespace text follows a sub-element.
The 5.x parser considered the last non-blank text node to be the
node value. In 6.x, every text node must be preserved and therefore
the node value is always the first text node before sub-elements.
<root><sub>text</sub>
This text is the node value in 5.x but not in 6.x
</root>
For compatibility with 5.x and non-mixed content aware agents,
the node value should appear first, before the sub-elements.
<root>
This text is the node value in 5.x and 6.x
<sub>text</sub>
</root>
Pretty-printing wastes processing time and consumes more memory.
It is best to avoid pretty-printed documents altogether.
<root>This text is the node value in 5.x and 6.x<sub>text</sub></root>
The 6.x release fully supports mixed content as required by XML
Digital Signatures. If mixed content could be processed by the application,
then the agents must be chosen carefully to make sure they are mixed
content aware. Most iWay agents are mixed content aware.
x
Previous releases of the server supported an xpath()
function that implemented a subset of the formal XPath specification
modified to better fit with the iWay requirements. Generally this
followed the Abbreviated Syntax described in subsection 2.5 of http://www.w3.org/TR/1999/REC-xpath-19991116.
This release adds the support of XML Namespaces while preserving
the stellar performance characteristics of the iWay implementation.
By default, the iWay XPath implementation is not namespace-aware
to preserve backwards compatibility. This means the colon is treated
as a regular character and the xmlns declarations have no special
meaning. For example, the expression _xpath(/ns:x) will match the
root element ns:x.
<ns:x xmlns:ns="http://testns">this will match</ns:x>
In general, it is not possible to predict which namespace prefix
will be used (if any). For example, the previous expression will
not match the semantically equivalent document using a default namespace.
<x xmlns="http://testns">this will NOT match</x>
What is required is a comparison of the local-name and the namespace-uri.
This can be done explicitly with a more complex expression _xpath(/*[namespace uri()="http://testns"
and local-name()="x"]).
<x xmlns="http://testns">this will match</x>
This approach works even if the element has a namespace prefix
because the local name does not include the prefix.
<ns:x xmlns:ns="http://testns">This will also match</ns:x>
This can become cumbersome if the xpath expression has many element
names to compare. The solution is to make the iWay XPath expression
namespace aware. This can be done by adding a second argument for
the name of the XML Namespace Map provider. This provider maintains
a mapping of namespace prefix to namespace URI. It can be declared
in the Server tab of the iWay Service Manager console by clicking
XML Namespace Map Provider in the left
pane. In the following image, the XML Namespace Map provider declares
the http://testns namespace.
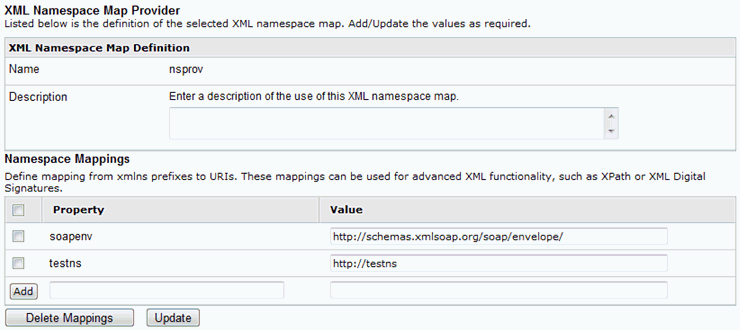
The name of the XML Namespace Map Provider is passed in the second
argument of the function: _xpath(/testns:x, nsprov). This instructs
XPath to resolve the prefix testns by finding the corresponding
URI in the nsprov provider. Notice this expression will match irrespective
of the actual namespace prefix used in the document. In particular,
it will match this document where the namespace prefix happens to
be ns:
<ns:x xmlns:ns="http://testns">This will match using a provider</ns:x>
Since the comparison is made directly with the namespace URI,
it does not matter if a namespace prefix is used or not. The latest
expression will also match if the element is in the default namespace:
<x xmlns="http://testns">This will also match using a provider</x>
Using XML Namespace Map Providers is the preferred approach when
matching against a namespace aware document.
x
Standard XPath 1.0 Function
By default, the iWay XPath function implements the abbreviated
syntax as described in section 2.5 of the XPath 1.0 specification.
This is adequate for most applications. For those that require strict
conformance, this release adds a full implementation of the XPath
1.0 specification as an optional feature. The iWay and the standard
XPath 1.0 implementations co-exist in the server at the same. The
choice of which one to use is determined by the need of the application
only.
In the iSM Administration Console, a new general setting called
XPATH 1.0 Functions is available in the Compatibility section of
the General Settings page, as shown in the following image.

The XPATH 1.0 Functions general setting determines the version
of the XPath language used in some iWay functions. Enable this general
setting to make the _xpath(), _xflat(), and _exists() functions
use the full XPath 1.0 language. By default, these functions use
the original iWay implementation. Since this general setting affects
the compilation of expressions, after it is selected, you must restart
the server to activate the setting.
New XPath functions were also added to work with a specific XPath
language irrespective of the XPATH 1.0 Functions general setting.
The _iwxpath(), _iwxflat(), and _iwexists() functions will always
select the original iWay implementation. The _xpath1(), _xflat1()
and, _exists1() functions will always select the standard XPath
1.0 implementation.
The following is an example of an XPath expression that uses
an explicit axis name, a feature only available in the XPath 1.0
implementation:
_xpath1(//elem/ancestor::*)
There are two implementations of the standard XPath 1.0 language
that are available. The default is to use the built-in iWay implementation.
This implementation is recommended because it is complete and very
fast. It is also possible to choose a third-party implementation
for those applications that require special extensions, such as
XSLT functions in Xalan’s XPath. This new general setting is called
Third-Party XPath 1.0 and is used to determine which XPath 1.0 implementation
is in use.

x
The iWay Functional Language (iFL) compiler in 5.x had
some syntax ambiguities that sometimes made it difficult to predict
the result of a parse. The compiler in 6.x implements the same language
but with more rigorous syntax rules. The net effect is a much more
predictable language. Unfortunately, some expressions that were
valid before are now rejected or given a new meaning. This section
discusses the changes in the iFL between 5.x and 6.x. Another section
in this chapter documents a tool to help detect problems and often
automatically make the change. The formal iFL syntax is provided
in Formal iFL Syntax.
iFL expressions are considered constants if they do not contain
at least one function call. In 5.x, the quotes in constant expressions
are evaluated. In 6.x, constant expressions are not interpreted
in any way.
The quoting rules in the 5.x iFL language are extremely difficult
to master. In 6.x, quoting is vastly improved as follows. Literals
can be quoted with single or double quotes. A quoted literal is
surrounded by a matching pair of quotes. Within a single-quoted
literal, you can type a double-quote without escaping it, and vice-versa.
The backslash is the escape character. The following escape sequences
are known: \r , \n, \f, \t, \', \", \xhh, \uhhhh where h is a hexadecimal
digit. The common trick in 5.x to type two consecutive single-quote
characters to obtain a unique single-quote no longer works. The
good news is that the equivalent construct \' will now work in all
quoted literals. Notice escape characters are not supported in bare
literals (not surrounded by quotes).
The rules for operators in the 5.x iFL language are also a cause
of issues. The compiler often needed extra whitespace surrounding
the operator to detect its presence. In general, the operators were
only detected at top level scope. The syntax now makes it clear
when an operator can be present. Whitespace surrounding an operator
is optional and if present, will be ignored.
Some 6.x functions introduce special scopes that have the effect
of turning off the detection of operators. This was done to increase
the compatibility with previous releases. Those functions are:
|
_and()
|
_isroot()
|
|
_atthdr()
|
_iwexists()
|
|
_atthdric()
|
_iwxpath()
|
|
_base64()
|
_or()
|
|
_concat()
|
_regex()
|
|
_cond()
|
_sql()
|
|
_decode64()
|
_sreg()
|
|
_encode64()
|
_xflat()
|
|
_exists()
|
_xflat1()
|
|
_exists1()
|
_xml()
|
|
_frombase64()
|
_xpath()
|
|
_fromhex()
|
_xpath1()
|
|
_hex()
|
|
Note:
- _cond() does not evaluate operators in its second parameter
only.
- _exists1(), _xflat1(), and _xpath1() do not evaluate operators
in the first and third parameters.
- Depending on the XPath 1.0 Functions general setting, _exists(),
_xflat(), and _xpath() behave like _iwexists(), _iwxflat(), and
_iwxpath(), or like _exists1(), _xflat1(), and _xpath1() respectively.
Due to their ability to introduce external syntax, these functions
turn off operators but now also turn off interpretation of quoting
characters:
- _sql()
- _xml()
- _xpath1() only in the first parameter
It is possible the scope of an infix operator might have changed
if one of the arguments is part of an implicit concatenation. When
in doubt, use explicit concatenation or surround the argument with
a pair of matching parentheses. For example, the expression sreg(a)1
+ 2 now concatenates the special register a to the sum of one and
two. In 5.x, the same expression concatenates the special register
a with one before adding two. To obtain the same result in 6.x,
you must use explicit concatenation, for example:
_concat(_sreg(a),1)+2
or add parentheses:
(sreg(a)1) + 2
The migration tools (testfuncs5 and migrate5) that are described
in this chapter can automatically make this transformation and many
more.
New functions to operate on long integers have been introduced:
_iadd(), _isub(), and _imul(). This is especially useful for date
arithmetic since the precision of a double-precision number is not
sufficient to represent a 64-bit integer. The semantics of the existing
_idiv() function has been changed to integer division to match the
other 3 functions. If the old semantics is desired, the call to _idiv(a,b) should
be replaced with _int(_div(a,b)).
x
The 6.x release consolidates the definition of resources
into named providers. Components using the resource simply name
the pre-defined provider to be used. This enables the server to
better control the resource for integrity and performance. Examples
of providers are keystores, LDAP connections and data base connections.
It is possible to define many providers of the same kind if they
have different names. For example, there can be any number of SSL
keystores rather than the single SSL keystore supported in 5.x.
Older agents or listeners that controlled their own resources
continue to be configured and function as before. For example, the
HTTP listener still requires the path to the SSL keystore. Many
components have been modified to use providers, either exclusively
or as an alternative to the specific configuration of the resource.
For example, the _ldap() function must either accept the default
LDAP provider or identify a specific named provider in a new, optional
parameter. In the future, all new components will use providers.
If your application is using a component that accesses a provider,
then the provider must be defined before the application can be
run. Providers are defined on the Server tab of the iWay Service
Manager console. To create an LDAP provider, click on Directory
Provider in the left menu. To create an SSL or an SMIME keystore,
click on the Security Provider in the left menu. To create a JDBC
data base connection, click on the Data Provider in the left menu.
For compatibility with older components, it is possible to declare
one keystore provider as the default SSL keystore. Similarly, you
can declare one keystore provider as the SMIME keystore. This can
be done on the Security Provider page by clicking the icon within
the Default SSL or the Default S/MIME column. The migrate5 tool
discussed below will convert a 5.x default keystore (or LDAP) provider
to a new 6.x provider marked as default.