Questa sezione fornisce descrizioni dettagliate di nuove funzioni per tutti gli adattatori SQL.
Un sinonimo per una tabella in una origine dati relazionale è in grado di contenere dichiarazioni nel file di accesso, specificando quali colonne dovrebbero avere indici.
Quando si emette un comando CREATE FILE per una tabella, si crea un indice in DBMS relazionale per la chiave principale e per ogni indice specificato nel file di accesso.
Se si desidera creare una tabella senza creare tutti gli indici in quel momento, è possibile omettere le dichiarazioni indice dal File Accesso ed emettere il comando CREATE FILE per creare solo la tabella e l'indice sulla chiave principale. Quindi, in seguito, è possibile aggiungere le dichiarazioni indice al file di accesso ed emettere il comando CREATE FILE con la frase INDEXESONLY. L'opzione di aggiungere indici in seguito rende il caricamento dati in una tabella relazionale più veloce.
CREATE FILE app/synonym INDEXESONLY
dove:
- app
La cartella dell'applicazione in cui si trova il sinonimo.
- sinonimo
Il sinonimo per la tabella esistente.
Il comando di unione WebFOCUS e il comando di unione condizionale presentano una opzione unione FULL OUTER.
Una unione esterna completa restituisce tutte le righe dall'origine dati e tutte le righe dall'origine dati target. Dove non esistono valori per le righe in nessuna delle origini dati, si restituiscono valori nulli. WebFOCUS sostituisce i valori predefiniti sull'emissione di prospetto (spazi vuoti per colonne alfanumeriche, il simbolo NODATA per colonne numeriche).
L'unione esterna completa è solo supportata per uso con quelle origini dati relazioni che supportano questo tipo di unione, nel quale caso si ottimizza la sintassi unione WebFOCUS (tradotta nella sintassi SQL unione esterna completa da RDBMS). L'uso di questa sintassi per qualsiasi origine dati non supporta una unione esterna completa, o il fallimento della richiesta da ottimizzare al motore produce un messaggio di errore.
La seguente sintassi genera una unione esterna completa a seconda dei campi reali:
JOIN FULL_OUTER hfld1 [AND hfld2 ...] IN table1 [TAG tag1] TO {UNIQUE|MULTIPLE} cfld [AND cfld2 ...] IN table2 [TAG tag2] [AS joinname] END
dove:
- hfld1
Il nome di un campo nella tabella host, contenente valori condivisi con un campo nella tabella di riferimento incrociato. Questo campo si chiama campo host.
- AND hfld2...
La frase che inizia con AND, si richiede quando si specificano più campi.
- Per adattatori relazionali che supportano multi-campi e unioni concatenate, è possibile specificare fino a 16 campi. Consultare la documentazione del proprio adattatore per informazioni specifiche sulle funzioni unione supportate.
- IN table1
È il nome della tabella host.
- TAG tag1
Un nome tag fino a 66 caratteri, (di solito il nome del file master), usato come identificatore univoco per campi e alias in tabelle host.
Il nome tag per la tabella host deve essere lo stesso in tutti i comandi JOIN di una struttura unita.
- TO [UNIQUE|MULTIPLE] crfld1
Il nome di un campo nella tabella di riferimento incrociato, contenente valori che corrispondono a quelli di hfld1 (o di campi host concatenati). Questo campo si chiama campo di riferimento incrociato.
Nota: UNIQUE restituisce solo una istanza e, se non è presente una istanza corrispondente nella tabella di riferimento incrociato, si restituiscono valori nulli.
Usare il parametro MULTIPLE quando crfld1 potrebbe avere multiple istanze in comune con un valore in hfld1. Notare che ALL è un sinonimo per MULTIPLE e, omettendo questo parametro completamente, risulta in un sinonimo per UNIQUE.
- AND crfld2...
Il nome di un campo nella tabella di riferimento incrociato con valori in comune con hfld2.
Nota: crfld2 potrebbe essere qualificato. Questo campo è solo disponibile per adattatori che supportano unioni multi-campi.
- IN crfile
È il nome della tabella con riferimento incrociato.
- TAG tag2
Un nome tag fino a 66 caratteri, (di solito il nome del file master), usato come identificatore univoco per campi e alias in tabelle di riferimento incrociato. In una struttura ad unione ricorsiva, se non si fornisce nessun nome tag, tutti i nomi dei campi e alias sono prefissati con i primi quattro caratteri del nome unione.
Il nome tag per la tabella host deve essere lo stesso in tutti i comandi JOIN di una struttura unita.
- AS joinname
Un nome opzionale fino a otto caratteri da poter assegnare alla struttura unione. È necessario assegnare un nome univoco ad una struttura unione se:
- È consigliabile assicurarsi che un comando JOIN successivo non lo sovrascrivi.
- È consigliabile deselezionarlo in seguito.
- La struttura è ricorsiva.
Nota: Se non si assegna un nome alla struttura unione con la frase AS, il nome si presuppone sia vuoto. Una unione senza un nome sovrascrive una unione esistente senza un nome.
- END
Richiesta quando il comando JOIN risulta più lungo di una riga. Termina il comando e deve essere su una riga da solo.
La seguente sintassi genera una unione esterna completa basata su DEFINE:
JOIN FULL_OUTER deffld WITH host_field ... IN table1 [TAG tag1] TO [UNIQUE|MULTIPLE] cr_field IN table2 [TAG tag2] [AS joinname] END
dove:
- deffld
Il nome del campo virtuale per il file host (il campo host). È possibile definire il campo virtuale nel file principale o con un comando DEFINE.
- WITH host_field
Il nome di qualsiasi campo reale nel segmento host con cui di desidera associare il campo virtuale. Questa associazione si richiede per localizzare il campo virtuale.
La frase WITH si richiede, a meno che il parametro KEEPDEFINES non sia impostato su ON e deffld non sia stato definito prima di emettere il comando JOIN.
Per determinare quale segmento contiene il campo virtuale, usare il ?
- IN table1
È il nome della tabella host.
- TAG tag1
Un nome tag fino a 66 caratteri, (di solito il nome del file master), usato come identificatore univoco per campi e alias in tabelle host.
Il nome tag per la tabella host deve essere lo stesso in tutti i comandi JOIN di una struttura unita.
- TO [UNIQUE|MULTIPLE] crfld1
Il nome di un campo reale nella tabella di riferimento incrociato, i quali valori corrispondono a quelli del campo virtuale. Questo deve essere un campo reale dichiarato nel file principale.
Nota: UNIQUE restituisce solo una istanza e, se non è presente una istanza corrispondente nella tabella di riferimento incrociato, si restituiscono valori nulli.
Usare il parametro MULTIPLE quando crfld1 potrebbe avere multiple istanze in comune con un valore in hfld1. Notare che ALL è un sinonimo per MULTIPLE e, omettendo questo parametro completamente, risulta in un sinonimo per UNIQUE.
- IN crfile
È il nome della tabella con riferimento incrociato.
- TAG tag2
Un nome tag fino a 66 caratteri, (di solito il nome del file master), usato come identificatore univoco per campi e alias in tabelle di riferimento incrociato. In una struttura ad unione ricorsiva, se non si fornisce nessun nome tag, tutti i nomi dei campi e alias sono prefissati con i primi quattro caratteri del nome unione.
Il nome tag per la tabella host deve essere lo stesso in tutti i comandi JOIN di una struttura unita.
- AS joinname
Un nome opzionale fino a otto caratteri da poter assegnare alla struttura unione. È necessario assegnare un nome univoco ad una struttura unione se:
- È consigliabile assicurarsi che un comando JOIN successivo non lo sovrascrivi.
- È consigliabile deselezionarlo in seguito.
- La struttura è ricorsiva e non si specificano nomi tag.
Se non si assegna un nome alla struttura unita con la frase AS, il nome si presuppone sia vuoto. Una unione senza un nome sovrascrive una unione esistente senza un nome.
- END
Richiesta quando il comando JOIN risulta più lungo di una riga. Termina il comando e deve essere su una riga da solo.
La seguente sintassi genera una unione condizionale esterna completa:
JOIN FULL_OUTER FILE table1 AT hfld1 [WITH hfld2] [TAG tag1] TO {UNIQUE|MULTIPLE} FILE table2 AT crfld [TAG tag2] [AS joinname] [WHERE expression1; [WHERE expression2; ...] END
dove:
- table1
Master File host.
- AT
Collega il segmento principale o host corretto al segmento secondario o di riferimento incrociato corretto. I valori campo usati come parametro AT non si usano per creare il collegamento. Si usano come riferimento segmento.
- hfld1
Il nome campo nel file principale, il quale segmento si unirà alla tabella di riferimento incrociato. Il nome campo deve essere al segmento di livello inferiore nella propria origine dati di riferimento.
- tag1
Nome del tag opzionale come qualificatore univoco per campi e alias nel file nella tabella host.
- hfld2
Una colonna di tabella con cui associare una JOIN condizionale basata su DEFINE. Per una unione condizionale basata su DEFINE, l'impostazione KEEPDEFINES deve essere ON ed è necessario creare i campi virtuali prima di emettere il comando JOIN.
- MULTIPLE
Specifica una relazione una-a-molte tra table1 e table2. Notare che ALL è un sinonimo per MULTIPLE
- UNIQUE
Specifica una relazione una-a-molte tra table1 e table2. Notare che ONE è un sinonimo per UNIQUE.
Nota: L'unione in UNIQUE restituirà solo una istanza della tabella di riferimento incrociato e se questa istanza non corrisponde in base alla valutazione dell'espressione WHERE, si restituiscono valori nulli.
- crfile
Master File di riferimento incrociato.
- crfld
Il nome campo unione nel file principale di riferimento incrociato.
- tag2
Nome del tag opzionale come qualificatore univoco per campi e alias nel file nella tabella di riferimento.
- joinname
Il nome associato con la struttura unita.
- expression1, expression2
Qualsiasi espressione accettabile in un comando DEFINE FILE. Tutti i campi usati nelle espressioni devono risidere su un solo percorso.
- END
Il comando END si richiede per terminare il comando e deve essere su una riga da solo.
Le seguenti richieste generano due tabelle Microsoft SQL Server da unire e quindi emetteno una richiesta rispetto all'unione. Le tabelle sono generate usando il campione wf_retail, da poter creare usando il tutorial WebFOCUS - Retail Demo, nella console web del server.
La seguente richiesta genera la tabella WF_SALES. Il campo ID_PRODUCT sarà usato nel comando unione esterna completa. La tabella generata conterrà i valori ID_PRODUCT da 2150 a 4000:
TABLE FILE WF_RETAIL_LITE SUM GROSS_PROFIT_US PRODUCT_CATEGORY PRODUCT_SUBCATEG BY ID_PRODUCT WHERE ID_PRODUCT FROM 2150 TO 4000 ON TABLE HOLD AS WF_SALES FORMAT SQLMSS END
La seguente richiesta genera la tabella WF_PRODUCT. Il campo ID_PRODUCT sarà usato nel comando unione esterna completa. La tabella generata conterrà i valori ID_PRODUCT da 3000 a 5000:
TABLE FILE WF_RETAIL_LITE SUM PRICE_DOLLARS PRODUCT_CATEGORY PRODUCT_SUBCATEG PRODUCT_NAME BY ID_PRODUCT WHERE ID_PRODUCT FROM 3000 TO 5000 ON TABLE HOLD AS WF_PRODUCT FORMAT SQLMSS END
La seguente richiesta emette il comando JOIN e visualizza valori dalle tabelle unite:
SET TRACEUSER=ON SET TRACESTAMP=OFF SET TRACEOFF=ALL SET TRACEON = STMTRACE//CLIENT JOIN FULL_OUTER ID_PRODUCT IN WF_PRODUCT TAG T1 TO ALL ID_PRODUCT IN WF_SALES TAG T2 TABLE FILE WF_PRODUCT PRINT T1.ID_PRODUCT AS 'Product ID' PRICE_DOLLARS AS Price T2.ID_PRODUCT AS 'Sales ID' GROSS_PROFIT_US BY T1.ID_PRODUCT NOPRINT ON TABLE SET PAGE NOPAGE END
La traccia mostra che l'unione esterna completa è stata ottimizzata (tradotta a SQL), quindi il Server SQL è in grado di elaborare l'unione:
SELECT T1."ID_PRODUCT", T1."PRICE_DOLLARS", T2."ID_PRODUCT", T2."GROSS_PROFIT_US" FROM ( WF_PRODUCT T1 FULL OUTER JOIN WF_SALES T2 ON T2."ID_PRODUCT" = T1."ID_PRODUCT" ) ORDER BY T1."ID_PRODUCT";
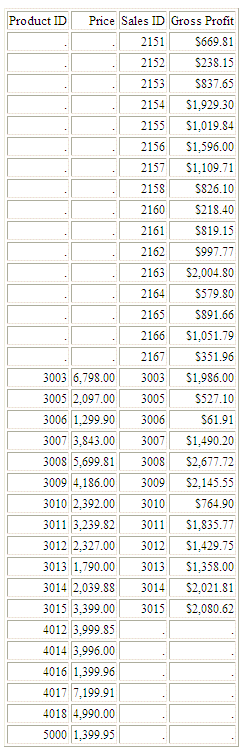
L'emissione ha una riga per ogni valore ID_PRODUCT, presente in una delle tabelle. Le righe con valori ID_PRODUCT da 2150 a 2167 sono solo nella tabella WF_SALES, quindi le colonne da WF_PRODUCT visualizzano il simbolo NODATA. Le righe con i valori ID_PRODUCT sopra a 4000 sono solo nella tabella WF_PRODUCT, quindi le colonne da WF_SALES visualizzano il simbolo NODATA. Le righe con valori ID_PRODUCT da 2000 a 4000 sono in entrambe le tabelle, quindi tutte le colonne presentano valori, come illustrato nella seguente immagine.
Il comando JOIN AS_ROOT aggiunge una nuova fact table come ulteriore radice ad un cluster basato su fatto esistente (schema a stella). Il file principale di origine ha un segmento fact principale e almeno un segmento dimensione secondario. Il comando JOIN AS_ROOT supporta una unione unica da un segmento dimensione secondario (a qualsiasi livello) ad un ulteriore segmento fact principale.
JOIN AS_ROOT sfld1 [AND sfld2 ...] IN [app1/]sfile TO UNIQUE tfld1 [AND tfld2 ...] IN [app2/]tfile AS jname END
dove:
- sfld1 [AND sfld2 ...]
I campi nel segmento secondario (dimensione) del file di origine che corrispondono ai valori dei campi nel file target.
- [app1/]sfile
File di origine.
- TO UNIQUE tfld1 [AND tfld2 ...]
I campi nel file target che corripondono ai valori dei campi nel segmento secondario del file di origine. L'unione deve essere unica.
- [app2/]tfile
File target.
- jname
Nome dell'unione.
- END
Richiesto per terminare il comando JOIN.
La seguente richiesta unisce i campi della categoria e sottocategoria prodotto nell'origine dati WebFOCUS Retail ad un file Excel chiamato PROJECTED.
Per generare l'origine dati WebFOCUS Retail nella cosole web, fare clic su Tutorial dal pagina di applicazione.
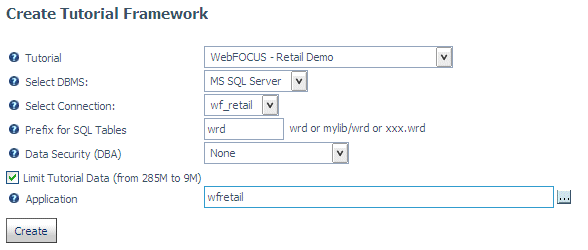
Selezionare WebFOCUS - Retail Demo. Selezionare il proprio adattatore relazionale configurato (o selezionare l'opzione flat file se non si ha un adattatore relazionale configurato), selezionare Limite Dati Tutorial e quindi fare clic su Crea.
Il file principale per il file Excel è:
FILENAME=PROJECTED, SUFFIX=DIREXCEL,
DATASET=app2/projected.xlsx, $
SEGMENT=PROJECTED, SEGTYPE=S0, $
FIELDNAME=PRODUCT_CATEGORY, ALIAS='Product Category', USAGE=A16V, ACTUAL=A16V,
MISSING=ON,
TITLE='Product Category',
WITHIN='*PRODUCT', $
FIELDNAME=PRODUCT_SUBCATEGORY, ALIAS='Product Subcategory', USAGE=A25V, ACTUAL=A25V,
MISSING=ON,
TITLE='Product Subcategory',
WITHIN=PRODUCT_CATEGORY, $
FIELDNAME=PROJECTED_COG, ALIAS=' Projected COG', USAGE=P15.2C, ACTUAL=A15,
MISSING=ON,
TITLE=' Projected COG', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
FIELDNAME=PROJECTED_SALE_UNITS, ALIAS=' Projected Sale Units', USAGE=I9, ACTUAL=A11,
MISSING=ON,
TITLE=' Projected Sale Units', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
MEASUREGROUP=PROJECTED, CAPTION='PROJECTED', $
DIMENSION=PRODUCT, CAPTION='Product', $
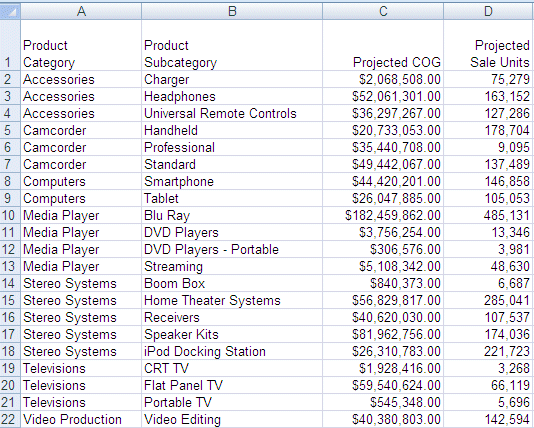
HIERARCHY=PRODUCT, CAPTION='Product', HRY_DIMENSION=PRODUCT, HRY_STRUCTURE=STANDARD, $La seguente immagine mostra i dati nel file Excel.
La seguente richiesta si unisce dal segmento wf_retail_product dell'origine dati wf_retail al file excel, come nuova radice ed esegue il reporting da entrambi i segmenti principali:
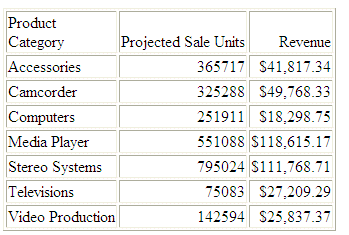
JOIN AS_ROOT PRODUCT_CATEGORY AND PRODUCT_SUBCATEG IN WF_RETAIL TO UNIQUE PRODUCT_CATEGORY AND PRODUCT_SUBCATEGORY IN PROJECTED AS J1. END TABLE FILE WF_RETAIL SUM PROJECTED_SALE_UNITS REVENUE_US BY PRODUCT_CATEGORY ON TABLE SET PAGE NOPAGE END
L'emissione è:
I sinonimi con più elementi principali sono ora supportati come origine per una unione in un singolo segmento, in un sinonimo target.
Una unione da un sinonimo con più elementi principali è soggetta alle seguenti condizioni:
- Le unioni condizionali non sono supportate (JOIN WHERE).
- L'unione deve essere unica. Ovvero, le frasi TO ALL o TO MUTLIPLE non sono supportate.
- Il target dell'unione non può essere un sinonimo con più elementi.
- Il target di JOIN deve essere un solo segmento, o un sinonimo con un solo segmento, o un segmento in un sinonimo con più elementi, ma con un solo elemento principale.
- Tutti i campo in JOIN devono essere FROM/TO un solo segmento. È possibile usare nell'unione qualsiasi segmento singolo nel sinonimo di origine.
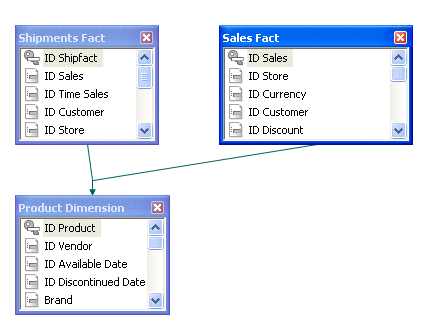
Il seguente file principale descrive una struttura con più elementi principali, basati su totorial WebFOCUS Retail. Le due fact table wf_retail_sales and wf_retail_shipments sono elementi principali della tabella dimensione wf_retail_product.
FILENAME=WF_RETAIL_MULTI_PARENT, $
SEGMENT=WF_RETAIL_SHIPMENTS, CRFILE=WFRETAIL/FACTS/WF_RETAIL_SHIPMENTS, CRINCLUDE=ALL,
DESCRIPTION='Shipments Fact', $
SEGMENT=WF_RETAIL_SALES, PARENT=., CRFILE=WFRETAIL/FACTS/WF_RETAIL_SALES, CRINCLUDE=ALL,
DESCRIPTION='Sales Fact', $
SEGMENT=WF_RETAIL_PRODUCT, CRFILE=WFRETAIL/DIMENSIONS/WF_RETAIL_PRODUCT, CRINCLUDE=ALL,
DESCRIPTION='Product Dimension', $
PARENT=WF_RETAIL_SHIPMENTS, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SHIPMENTS.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $
PARENT=WF_RETAIL_SALES, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SALES.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $La seguente immagine mostra le unioni tra queste tabelle nell'Editor di Sinonimo della console di gestione dati (DMC).
La seguente richiesta unisce il segmento di prodotto alla tabella dimensione wf_retail_vendor, a seconda dell'ID fornitore ed emette una richiesta rispetto alla struttura unita:
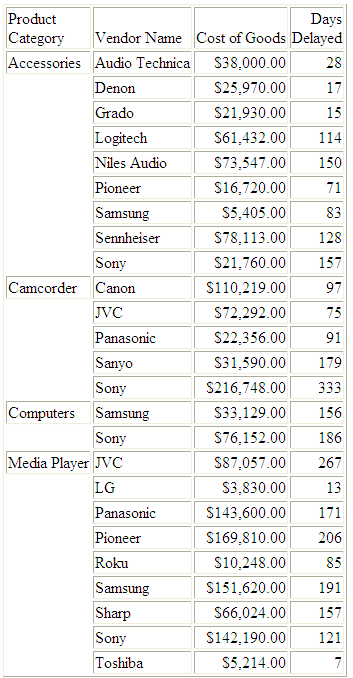
JOIN ID_VENDOR IN WF_RETAIL_MULTI_PARENT TO ID_VENDOR IN WF_RETAIL_VENDOR AS J1 TABLE FILE WF_RETAIL_MULTI_PARENT SUM COGS_US DAYSDELAYED BY PRODUCT_CATEGORY BY VENDOR_NAME WHERE PRODUCT_CATEGORY LT 'S' ON TABLE SET PAGE NOPAGE END
L'emissione è:
Quando uno schema a stella contiene un segmento con fact aggregati e un segmento di livello inferiore, con i fact con i relativi dettagli di livello, una richiesta che esegue l'aggregazione su entrambi i livelli e li restituisce ordinati per livello superiore potrebbe riscontrare l'effetto moltiplicativo. Questo significa che i valori fact che sono già aggregati potrebbero essere riaggregati e, quindi, restituire valori motliplicati.
Quando l'adattatore rileva l'effetto moltiplicativo, si disattiva l'ottimizzazione, per gestire l'elaborazione della richiesta e per aggirare l'effetto moltiplicativo. Tuttavia, la prestazione risulta danneggiata quando non si ottimizza una richiesta.
Un nuovo processo di analisi di contesto è stato introdotto in questo release che rileva l'effetto moltiplicativo e genera comandi script SQL, che recuperano i valori corretti per ogni contesto di segmento. Questi script sono quindi inoltrati a RDBMS come subquery in una dichiarazione SQL ottimizzata.
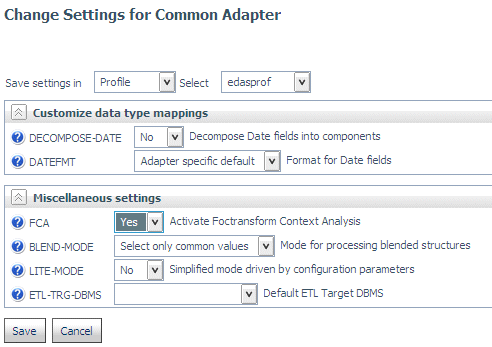
Per attivare la funzione analisi di contesto, fare clic su Modifica Impostazioni Adattatore Comune sulla pagina Adattatori della console web. Quindi, selezionare Sì per il parametro FCA nella sezione Impostazioni Varie e fare clic su Salva, come illustrato nella seguente immagine.
Nei release precedenti, i campi partecipanti nella chiave in una tabella dovevano essere descritti prima nel file principale. Il numero di campi chiave si identificava per l'attributo KEYS=n, nel file di accesso, dove n è il numero dei campi principali.
Anche se questo metodo è ancora supportato da adattatori relazionali, è ora obsoleto. Nella Versione 7 Release 7.06, è disponibile la nuova sintassi che non richiede nessun riordinamento dei campi nel file principale. Se si apre un file di accesso con la sintassi KEYS=n in Editor di Sinonimo, l'Editor di Sinonimo lo convertirà nella nuova sintassi.
Nel file di accesso, identificare i campi chiave con la seguente sintassi:
KEY=fld1/fld2/.../fldn
dove:
- fld1, fld2,...,fldn
I campi che partecipano nella chiave.
Il seguente è un file principale per una tabella Oracle:
FILENAME=BMKEY, SUFFIX=SQLORA , $
SEGMENT=BMKEY, SEGTYPE=S0, $
FIELDNAME=F1INT, ALIAS=F1INT, USAGE=I11, ACTUAL=I4, $
FIELDNAME=F2CHAR4, ALIAS=F2CHAR4, USAGE=A4, ACTUAL=A4,
MISSING=ON, $
FIELDNAME=F3INT, ALIAS=F3INT, USAGE=I11, ACTUAL=I4,
MISSING=ON, $
FIELDNAME=F4CHAR6, ALIAS=F4CHAR6, USAGE=A6, ACTUAL=A6,
MISSING=ON, $Il seguente file di accesso identifica F4CHAR6 e F1INT come campi chiave, con F4CHAR6 come porzione di ordine superiore della chiave, anche se non è la prima del file principale:
SEGNAME=BMDKEY_KEY_FLDLST,
TABLENAME=R729999D.BMDKEY,
CONNECTION=<local>,
KEY=F4CHAR6/F1INT, $
Le funzioni dei caratteri semplificati presentano elenchi parametro semplificati, simili a quelli utilizzati dalle funzioni SQL. Tali elementi sono ottimizzati rispetto ad una vasta gamma di origini dati relazionali. Le funzioni di carattere semplificate, introdotte in questo release, sono:
- SUBSTRING - Estrae una sottostringa da una stringa di caratteri d'origine.
- TOKEN - Estrae un token da una stringa.
- LTRIM - Rimuove tutti gli spazi dall'estremità sinistra della stringa di caratteri.
- RTRIM - Rimuove tutti gli spazi dall'estremità destra della stringa di caratteri.
- TRIM_ - Rimuove i caratteri iniziali, i caratteri finali o entrambi da una una stringa di caratteri.
- CHAR_LENGHT - Restituisce la lunghezza di caratteri di una stringa di origine
- LOWER - Restituisce la stringa di caratteri con tutte le lettere in caratteri minuscoli.
- UPPER - Restituisce la stringa di caratteri con tutte le lettere in caratteri maiuscoli.
- POSITION - Restituisce la posizione della pirma ricorrenza di una stringa campione specifica nella stringa d'origine.
Il Prospetto Ottimizzazione SQL fornisce informazioni di ottimizzazione per ogni funzione per adattatore.
Le funzioni data e data-ora semplificate presentano elenchi parametro semplificati, simili a quelli utilizzati dalle funzioni SQL. Tali elementi sono ottimizzati rispetto ad una vasta gamma di origini dati relazionali. Le funzioni data-ora e data semplificate, introdotte in questo release, sono:
- DTRUNC - Data una data o timestamp e un componente, DTRUNC restituisce la prima data all'interno del periodo specificato da quel componente.
- DTADD - Data una data in formato data standard o data-ora, DTADD restituisce una nuova data dopo aver aggiunto il numero specificato o un componente supportato. Il formato data restituito è l stesso del formato data d'immissione.
- DTPART - Data una data in formato data standard o data-ora ed un componente, DTPART restituisce il valore componente in formato intero.
- DTDIFF - Fornite due date in formati data standard e data-ora, DTDIFF restiutisce il numero dei confini del componente dato tra due date. Il valore restituito presenta formato intero per i componenti del calendario o formato punto mobile di precisione doppia per i componenti ora.
Il Prospetto Ottimizzazione SQL fornisce informazioni di ottimizzazione per ogni funzione per adattatore.
Le seguenti funzioni sono state ottimizzate per la maggior parte degli adattatori SQL, come riportato nel Prospetto Ottimizzazione SQL.
- TRIMV con le opzioni L o B (sinistra o destra)
- TRIM.
- POWER (fld ** exponent).
- ARGLEN.
Le seguenti funzioni sono ottimizzate come riflesso nel Prospetto Ottimizzazione SQL.
- DATEADD. Con parametri YEAR, MONTH e DAY.
- DATECVT. Ottimizzate per DB2 con formati data legacy a 6 cifre I6YMD, I6MDY, I6DMY, P6YMD, P6MDY, P6DMY, A6YMD, A6MDY e A6DMY.
- DATEDIFF. Con parametri YEAR, MONTH e DAY.
- DATEMOV. Con parametri BOW, EOW, BOM, EOM, BOQ, EOQ, BOY e EOY.
- DPART. Con parametri YEAR, MONTH, DAY, QUARTER, e WEEKDAY.
- HADD. Con parametri YEAR, MONTH, HOUR, MINUTE e SECOND.
- HDATE.
- HDIFF. Con parametri YEAR, MONTH, HOUR, MINUTE e SECOND.
- HDTTM. Con le seguenti combinazioni di parametro: "8,'HYYMDS'", "8,'HYYMDs'", e "10,'HYYMDm'".
- HGETC.
- HPART. Con parametri YEAR, MONTH, DAY, QUARTER, WEEKDAY, DAY-OF-YEAR, WEEK, HOUR, MINUTE, SECOND, MILLISECOND e MICROSECOND. La funzione HPART ottimizzata con il parametro WITH è compatibile con FOCUS, solo in presenza dell'impostazione WEEKFIRST=ISO2.
- TODAY.
Questa funzione si implementa come comando SET che genera file HOLD come file SQL_SCRIPT, dove non si specifica nessun formato sul comando ON TABLE HOLD.
Nota: Se l'adattatore non è in grado di generare richieste SQL per una richiesta TABLE complessa (a causa dell complessità di espressione o altri motivi), il sistema esegue automaticamente il downgrade dell'impostazione HOLDFORMAT, in BINARY, solo per quella richiesta. Da poter usare per conversioni applicazione in SQL_SCRIPT, come procedure generate da BCEE o MFACT.
La pagina di configurazione dell'adattatore della console web per adattatori basati su SQL presenta un pulsante che consente di verificare l'impostazioni del rilevamento delle maiuscole/minuscole del DBMS di destinazione.
Le variabili che hanno i valori delle impostazioni SQLTAG e ABORTREPORT sono disponibili.
-TYPE &engine SQLTAG -TYPE &engine ABORTREPORT
dove:
- ENGINE
La tag del motore adattatore. Per esempio, DB2 per DB2, ORA per Oracle, MSS per Microsoft SQL Server, DBC per Teradata, etc.
Quando si usa HOLD con un FORMAT motore SQL, una nuova opzione consente di usare una procedura di caricamento massa per caricare la tabella.
Le seguenti funzioni semplificate sono ottimizzate a SQL:
- SUBSTRING
- LTRIM
- RTRIM
- TRIM_
- CHAR_LENGTH
- LOWER
- Superiore
Il Prospetto Ottimizzazione SQL fornisce informazioni di ottimizzazione per ogni funzione per adattatore.
Nota: Le funzioni semplificate sono più facili da usare sono probabilmente ottimizzate in un intervallo più ampio di motori rispetto alle funzioni legacy.