Calcul de tendances et prévision de valeurs avec FORECAST
La fonctionnalité de prévision FORECAST vous permet de calculer les tendances des données numériques et de prédire des valeurs au-delà de la plage de celles stockées dans une source de données. FORECAST peut être utilisée dans une requête de rapport ou de graphique.
Les calculs que vous pouvez effectuer pour identifier des tendances et prédire des valeurs sont :
-
Moyenne mobile simple (MOVAVE). Calcule une succession de moyennes arithmétiques à partir d'un nombre fixe de valeurs d'un champ. Pour plus de détails, consultez Utilisation d'une moyenne mobile simple.
-
Moyenne mobile exponentielle calcule une moyenne pondérée basée sur la valeur de la moyenne précédemment calculée et le point de données suivant. Il existe trois méthodes pour utiliser une moyenne mobile exponentielle :
-
Lissage exponentiel unique (EXPAVE). calcule une moyenne qui vous permet de choisir des poids à appliquer aux valeurs récentes et moins récentes. Pour plus de détails, consultez Utilisation du lissage exponentiel unique.
-
Lissage exponentiel double (DOUBLEXP). explique la tendance des données à augementer ou à diminuer au cours du temps sans se répéter. Pour plus de détails, consultez Utilisation du lissage exponentiel double.
-
Lissage exponentiel triple (saisonnier). explique la tendance des données de se répéter à intervalles au cours du temps. Pour plus de détails, consultez Utilisation du lissage exponentiel triple.
-
Analyses de régression linéaire (REGRESS).
Pour plus de détails, consultez Notes d'utilisation pour la création de champs virtuels.
En effectuant la prévision de valeurs ainsi que le calcul de tendances, FORECAST poursuit ses calculs au-delà des points de données, en utilisant les valeurs de tendances générées comme des nouveaux points de données. En ce qui concerne la technique de régression linéaire, l'équation de regression calculée sert à tirer des valeurs de tendance et de prévision.
FORECAST effectue les calculs selon les données fournies, mais c'est à l'utilisateur de prendre les décisions concernant leur utilisation et exactitude. Par conséquent, les prédictions FORECAST ne sont pas toujours fiables, et il y a nombreux facteurs qui déterminent leur exactitude.
x
L'invocation du traitement FORECAST se fait en incluant FORECAST dans une commande RECAP. Dans cette commande, il faut spécifier les paramètres nécessaires pour générer des valeurs évaluées, y compris le champ à utiliser dans les calculs, le type de calcul à utiliser et le nombre de prévisions à générer. Le champ RECAPcontenant le résultat de FORECAST peut être un nouveau champ (non récursif) ou le même champ utilisé dans les calculs FORECAST (récursifs) :
- Dans une FORECAST récursive, le champ RECAP contenant les résultats est aussi le champ utilisé pour générer les calculs FORECAST. Dans ce cas, le champ d'origine ne s'affiche pas, même s'il a été référencé dans la commande d'affichage, et la colonne RECAP contient les valeurs de champ d'origine suivies du nombre de valeurs de prédiction spécifié dans la syntaxe FORECAST. Aucunes valeurs de tendance ne s'affichent dans le rapport ; cependant, la colonne d'origine est triée dans un fichier de sortie, à moins que vous ne définissiez HOLDLIST à PRINTONLY.
- Dans une FORECAST non récursive, un nouveau champ contenant les résultats de FORECAST est aussi le champ utilisé pour générer les calculs Forecast. Le nouveau champ s'affiche dans le rapport ainsi que le champ original lorsqu'il est référencé dans la commande d'affichage. Le nouveau champ contient les valeurs de tendance et de prévision, lorsqu'elles sont spécifiées.
FORECAST s'effectue sur le dernier champ ACROSS de la requête. Si la requête ne contient pas de champs ACROSS, FORECAST s'effectue sur le dernier champ BY. Les calculs FORECAST recommencent lorsque le critère de tri du niveau supérieur change de valeur. Dans une requête avec des commandes d'affichage multiples, FORECAST s'effectue sur le dernier champ ACROSS (ou s'il n'y a pas de champs ACROSS, sur le dernier champ BY) de la dernière commande d'affichage.
Lorsqu'un champ ACROSS est utilisé avec FORECAST, la commande d'affichage doit être SUM ou COUNT.
Remarque : bien que vous faisiez passer des paramètres à FORECAST en utilisant une liste d'arguments entre parenthèses, FORECAST n'est pas une fonction. Il peut coexister avec une fonction du même nom, tant que la fonction n'est pas spécifiée dans une commande RECAP.
x
Syntaxe : Calculer des tendances et prédire des valeurs
Calcul MOVAVE
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'MOVAVE',npoint1)sendstyle
Calcul EXPAVE
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'EXPAVE',npoint1);
Calcul DOUBLEXP
ON sortfield RECAP fld1[/fmt] = FORECAST(infield,
interval, npredict, 'DOUBLEXP',npoint1, npoint2);
Calcul SEASONAL
ON sortfield RECAP fld1[/fmt] = FORECAST(infield,
interval, npredict, 'SEASONAL', nperiod, npoint1, npoint2, npoint3);
Calcul REGRESS
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'REGRESS');
où :
- sortfield
- est le dernier champ ACROSS dans la requête. Ce champ doit être au format numérique ou de date. Si la requête ne contient pas de champs ACROSS, FORECAST fonctionne par rapport au dernier champ BY.
- result_field
- Est le champ contenant le résultat de FORECAST. Il peut être un nouveau champ ou le même que infield. Ce champ doit être numérique et soit un champ réel, un champ virtuel ou un champ calculé.
Remarque :
le mot FORECAST et la parenthèse d'ouverture doivent être sur la même ligne que la syntaxe
sortfield=.
- FORMAT
- est le format d'affichage de result_field. Le format par défaut est D12.2. Si
result_field a été formaté auparavant avec une commande DEFINE ou COMPUTE, le format spécifié dans la commande RECAP est respecté.
- infield
- Est tout champ numérique. Il peut être le même champ que
result_field, ou bien un champ différent. Toutefois, il ne peut pas être un champ date-heure ou un champ numérique avec des options d'affichage de date.
- intervalle
- est l'incrément à ajouter à chaque valeur de
sortfield (après le dernier point de données) pour créer la prochaine valeur. Ceci doit être un nombre entier positif. Pour trier dans l'ordre décroissant, utilisez la phrase BY HIGHEST. Le résultat de l'addition de ce nombre aux valeurs de sortfield est converti au même format que sortfield.
Pour les champs de date, le composant minimal du format détermine la façon dont le nombre est interprété. Par exemple, si le format est AMJ, MJA ou JMA, la valeur intervalle 2 est interprétée comme signifiant deux jours ; si le format est YM, le 2 est interprété comme signifiant deux mois.
- npredict
- Est le nombre de prévisions que FORECAST doit calculer. Il doit être un nombre entier supérieur ou égal à zéro. Zéro indique que vous ne voulez aucune prévision, et n'est supporté qu'avec une prévision [FORECAST] non récursive. En ce qui concerne la méthode saisonnière [SEASONAL], npredict est le nombre de
périodes à calculer. Le nombre de points générés est :
nperiod * npredict
- nperiod
- Pour la méthode saisonnière [SEASONAL], est un nombre entier positif spécifiant le nombre de points de données dans une période.
- npoint1
- Est le nombre de valeurs pour lesquelles il faut faire la moyenne pour la méthode MOVAVE. Pour EXPAVE, DOUBLEXP et SEASONAL, ce nombre est utilisé pour calculer le poids de chaque composant dans la moyenne. Cette valeur doit être un nombre entier positif. Le poids, k, est calculé par la formule suivante :
k=2/(1+npoint1)
- npoint2
- Pour DOUBLEXP et SEASONAL, ce nombre entier positif est utilisé pour calculer le poids de chaque terme dans la tendance. Le poids, g, est calculé par la formule suivante :
g=2/(1+npoint2)
- npoint3
- Pour SEASONAL, ce nombre entier positif est utilisé pour calculer le poids de chaque terme dans la modification saisonnière. Le poids, p, est calculé par la formule suivante :
p=2/(1+npoint3)
x
Référence : Notes d'utilisation pour FORECAST
- Le champ de tri utilisé pour FORECAST doit être au format numérique ou de date.
- Lors de l'utilisation des méthodes de moyenne mobile simple et de moyenne mobile exponentielle, les valeurs de données doivent être espacées régulièrement afin d'obtenir des résultats significatifs.
- Lorsque vous utilisez la commande RECAP avec FORECAST, la commande ne peut contenir que la syntaxe FORECAST. FORECAST Pour spécifier des options telles que AS et IN :
- dans une requête non-récursive FORECAST, utilisez une commande COMPUTE vide avant RECAP.
- dans une requête FORECAST récursive, spécifiez les options lors de la première référence du champ dans la requête de rapport.
- L'utilisation d'une notation de colonne n'est pas prise en charge dans une requête qui comprend FORECAST. Le processus de génération des valeurs de FORECAST créent des colonnes supplémentaires n'étant pas imprimées dans la sortie de rapport. Le nombre de ces colonnes et leur placement dans le rapport peut varier d'une requête à l'autre.
- Une requête peut contenir jusqu'à sept non-FORECAST
commandes RECAP et jusqu'à sept commandes FORECAST RECAP supplémentaires.
- Le côté gauche d'une commande RECAP utilisée pour FORECAST prend en charge l'attribut CURR pour la création d'un champ dénommé par une devise.
- Lorsque la commande d'affichage est SUM, ADD, ou WRITE, les requêtes contenant à la fois des REGRESS récursifs et non récursifs ne sont pas supportées.
- Les valeurs manquantes ne sont pas supportées avec REGRESS.
-
Si vous utilisez le paramètre ESTRECORDS pour permette au tri externe de mieux évaluer la quantité d'espace de travail de tri nécessaire, vous devez prendre en compte que l'utilisation de FORECAST avec des prévisions crée des enregistrements supplémentaires dans la sortie.
-
Dans un rapport contenant un style, vous pouvez attribuer des attributs particuliers aux valeurs de prédiction par FORECAST à l'aide de l'attribut de feuille de style WHEN=FORECAST. Par exemple, pour afficher les valeurs prévues en rouge, utilisez la syntaxe suivante dans la requête TABLE :
ON TABLE SET STYLE *TYPE=DATA,COLUMN=MYFORECASTSORTFIELD,WHEN=FORECAST,COLOR=RED,
$ENDSTYLE
x
Référence :
Limites de FORECAST
Les choses suivantes ne sont pas supportées avec une commande RECAP utilisant FORECAST :
- La commande BY TOTAL.
- Les phrases MORE, MATCH, FOR, et OVER.
- SUMMARIZE et RECOMPUTE ne sont pas supportées pour le même champ de tri utilisé pour FORECAST.
- attribut MISSING.
xUtilisation d'une moyenne mobile simple
Une moyenne mobile simple est une série de moyennes arithmétiques calculées à partir d'un nombre fixe de valeurs d'un certain champ. Chucune des moyennes de la série est calculée en supprimant la première valeur du calcul précédent et en ajoutant la valeur de données suivante au calcul.
Les moyennes mobiles simples servent parfois dans l'analyse des tendances des prix des actions au cours du temps. Dans un tel scénario, la moyenne est calculée à partir d'un nombre fixe de périodes de prix d'actions. L'inconvenient, c'est que comme l'indicateur supprime les valeurs les moins récentes du calcul au cours du temps, il perd de mémoire peu à peu. En plus, les valeurs de moyenne sont déformées en raison des niveaux élévés et bas extrêmes, car cette méthode apporte du poids égal à chaque point.
Les valeurs prévues au-delà de la plage des valeurs de données sont calculées en utilisant une moyenne mobile qui traite les valeurs de tendance calculées comme des nouveaux points.
La première moyenne mobile complète se présente au point de données n
énième car le calcul requiert
n valeurs. C'est ce qu'on appelle le décalage. Les valeurs de la moyenne mobile pour les lignes de décalage sont calculées de la façon suivante : la première valeur de la colonne de la moyenne mobile est égale à la première valeur de données, la deuxième valeur de la colonne de la moyenne mobile est la moyenne des deux premières valeurs de données, et ainsi de suite jusqu'à la dernière ligne n
énième, auquel point il y a assez de valeurs pour pouvoir calculer la moyenne mobile avec le nombre de valeurs spécifiées.
Exemple : Calcul d'une nouvelle colonne de moyenne mobile unique
Cette requête définit une valeur de nombre entier appelée PERIOD, à utiliser comme variable indépendante pour la moyenne mobile. Elle prédit trois périodes de valeurs au-delà de la plage des données récupérées.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP MOVAVE/D10.1= FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La sortie est :
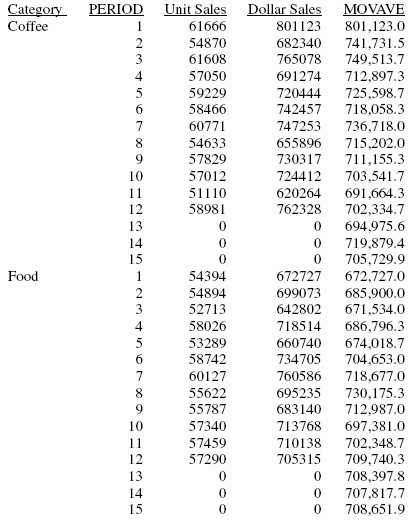
Dans le rapport, le nombre de valeurs à utiliser pour calculer la moyenne est 3 et aucune valeur QUANTITY ou LINE_COGS n'existe pour les valeurs PERIOD générées.
Chaque moyenne (valeur MOVAVE) est calculée en utilisant les valeurs de DOLLARS, où elles existent. Le calcul de la moyenne mobile commence de la façon suivante :
- La première valeur de MOVAVE (801,123.0) est égale à la première valeur de DOLLARS.
- La deuxième valeur de MOVAVE (741,731.5) est la moyenne des valeurs 1 et 2 de DOLLARS : (801,123 + 682,340) /2.
- La troisième valeur de MOVAVE (749,513.7) est la moyenne des valeurs 1 à 3 de DOLLARS : (801,123 + 682,340 + 765078) / 3.
- La quatrième valeur de MOVAVE (712,897.3) est la moyenne des valeurs 2 à 4 de DOLLARS : (682,340 + 765,078 + 691274) /3.
Pour obtenir des valeurs de prévision au-delà des valeurs fournies, les valeurs calculées de MOVAVE sont utilisées en tant que nouveaux points de données pour poursuivre le calcul de la moyenne mobile. Les valeurs de MOVAVE prévues (à partir de 694,975.6 pour PERIOD 13) sont calculées en utilisant les valeurs précédentes de MOVAVE en tant que nouveaux points de données. Par exemple, la première valeur prévue (694,975.6) est la moyenne des points de données des périodes 11 et 12 (620,264 et 762,328) et la moyenne mobile de la période 12 (702,334.7). Le calcul est : 694,975 = (620,264 + 762,328 + 702,334.7)/3.
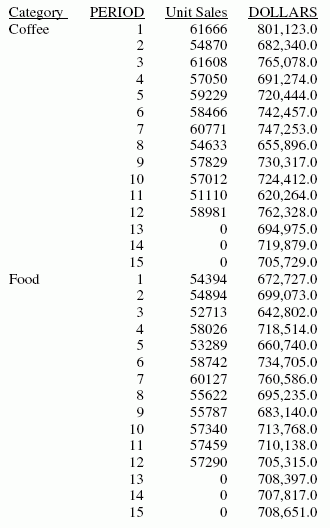
Exemple : Utilisation d'un champ existant comme colonne de moyenne mobile unique
Cette requête définit une valeur de nombre entier appelée PERIOD, à utiliser comme variable indépendante pour la moyenne mobile. Elle prédit trois périodes de valeurs au-delà de la plage des données récupérées. La requête emploie le nom du champ RECAP comme le premier argument dans la liste de paramètres FORECAST. Les valeurs de tendance ne s'affichent pas dans le rapport. Les valeurs de données réelles de DOLLARS sont suivies des valeurs prévues dans la colonne de rapport.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP DOLLARS/D10.1 = FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La sortie est :
xUtilisation du lissage exponentiel unique
La méthode de lissage exponentiel unique calcule une moyenne qui vous permet de choisir des poids à appliquer à des valeurs récentes et moins récentes.
La formule suivante permet de déterminer le poids assigné à la valeur la plus récente.
k = 2/(1+n)
où :
- k
- Est la valeur la plus récente.
- n
- Est un nombre entier supérieur à 1. L'augmentation de n a pour effet d'augmenter le poids assigné aux observations (ou aux instances de données) les plus anciennes par rapport à celles les plus récentes.
Le calcul suivant de la valeur de la moyenne mobile exponentielle (EMA) est tiré selon la formule suivante :
EMA = (EMA * (1-k)) + (datavalue * k)
Cela signifie que la valeur la plus récente de la source de données est multipliée par le facteur
k et que la moyenne mobile actuelle est multipliée par le facteur (1-k). Ces quantiés sont alors totalisées pour obtenir la nouvelle EMA.
Remarque : lorsque les valeurs de données sont épuisées, la dernière valeur de données dans le groupe de tri est utilisée comme la prochaine valeur de données.
Exemple : Calcul d'une colonne de lissage exponentiel unique
Cette requête définit une valeur de nombre entier appelée PERIOD, à utiliser comme variable indépendante pour la moyenne mobile. Elle prédit trois périodes de valeurs au-delà de la plage des données récupérées.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP EXPAVE/D10.1= FORECAST(DOLLARS,1,3,'EXPAVE',3);
END
La sortie est :
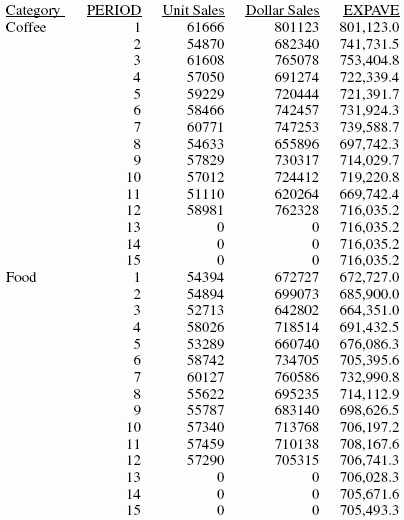
Dans ce rapport, trois valeurs prévues de EXPAVE sont calculées dans chaque valeur de CATEGORY. Pour les valeurs au-delà de la plage des données, des nouvelles valeurs de PERIOD sont générées en additionnant la valeur du nombre entier (1) à la valeur de PERIOD précédente.
Chaque moyenne (valeur de EXPAVE) est calculée en utilisant les valeurs de DOLLARS, où elles existent. Le calcul de la moyenne mobile commence de la façon suivante :
- La première valeur de EXPAVE (801,123.0) est la même que la première valeur de DOLLARS.
- La deuxième valeur de EXPAVE (741,731.5) est calculée de la façon suivante. Notez qu'en raison de l'arrondissement et du nombre de décimales utilisées, la valeur résultant de cet exemple de calcul peut varier légèrement de celle qui s'affiche dans la sortie de rapport :
n=3 (number used to calculate weights)
k = 2/(1+n) = 2/4 = 0.5
EXPAVE = (EXPAVE*(1-k))+(new-DOLLARS*k) = (801123*0.5) + (682340*0.50) = 400561.5 + 341170 = 741731.5
- La troisième valeur de EXPAVE (753,404.8) est calculée de la façon suivante :
EXPAVE = (EXPAVE*(1-k))+(new-DOLLARS*k) = (741731.5*0.5)+(765078*0.50) = 370865.75 + 382539 = 753404.75
Pour les valeur prévues au-delà de celles fournies, la dernière valeur de EXPAVE est utilisée comme le nouveau point de données dans le calcul de lissage exponentiel. Les valeurs de EXPAVE prévues (à partir de 706,741.6) sont calculées en utilisant la moyenne précédente et le nouveau point de données. Comme la moyenne précédente sert aussi de nouveau point de données, les valeurs de prédiction sont toujours égales à la dernière valeur de tendance. Par exemple, la moyenne précédente de la période 13 est 706,741.6, ce qui est aussi utilisée comme le nouveau point de données ; par conséquent, la moyenne est calculée de la façon suivante : (706,741.6 * 0.5) + (706,741.6 * 0.5) = 706,741.6
EXPAVE = (EXPAVE * (1-k)) + (new-DOLLARS * k) = (706741.6*0.5) +
(706741.6*0.50) = 353370.8 + 353370.8 = 706741.6
xUtilisation du lissage exponentiel double
Le lissage exponentiel double produit une moyenne mobile exponentielle qui explique la tendance des données à augmenter ou à diminuer au cours du temps sans se répéter. Il faut deux équations avec deux constantes pour réaliser cette opération.
Ces deux équations sont résolues pour tirer la moyenne glissante. La première moyenne glissante est mise à la première valeur de données. Le premier composant de tendance est mis à zéro. Pour choisir les deux constantes, les meilleurs résultats sont obtenus en minimisant l'erreur quadratique moyenne (MSE) entre les valeurs de données et les moyennes calculées. Il peut être nécessaire d'utiliser des techniques d'optimisation non linéaires pour trouver les constantes optimales.
L'équation utilisée pour prévoir au-delà des points de données avec le lissage exponentiel double est :
forecast(t+m) = DOUBLEXP(t) + m * b(t)
où :
- m
- Est le nombre de périodes en avance pour la prévision.
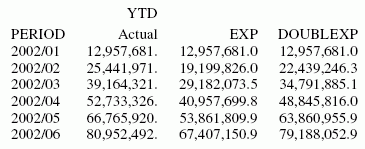
Exemple : Calcul d'une colonne de lissage exponentiel double
Cette requête définit une valeur de nombre entier appelée PERIOD, à utiliser comme variable indépendante pour la moyenne mobile. La méthode de lissage exponentiel double estime la tendance dans les points de données mieux qu'une méthode de lissage unique :
SET HISTOGRAM = OFF
TABLE FILE CENTSTMT
SUM ACTUAL_YTD
BY PERIOD
ON PERIOD RECAP EXP/D15.1 = FORECAST(ACTUAL_YTD,1,0,'EXPAVE',3);
ON PERIOD RECAP DOUBLEXP/D15.1 = FORECAST(ACTUAL_YTD,1,0,
'DOUBLEXP',3,3);
WHERE GL_ACCOUNT LIKE '3%%%'
ENDLa sortie est :
xUtilisation du lissage exponentiel triple
Le lissage exponentiel triple produit une moyenne mobile exponentielle qui explique la tendance des données à se répéter à intervalles au cours du temps. Par exemple, les données de ventes croissantes et dans lesquelles 25 % des ventes se font au mois de décembre contiennent de la tendance et de la saisonnalité. Le lissage exponentiel triple explique la tendance et la saisonnalité en utilisant trois équations avec trois constantes.
Le lissage exponentiel triple exige une connaissance du nombre de points de données dans chaque période (désigné comme L dans les équations suivantes). Pour tenir compte de la saisonnalité, un index saisonnier est calculé. Les données sont divisées par l'index de la saison précédente puis utilisées pour calculer la moyenne glissante.
- La première équation représente la période actuelle, et c'est une moyenne pondérée de la valeur de données actuelle divisée par le facteur saisonnier et la moyenne précédente adaptée en fonction de la tendance de la période précédente. La constante de poids est k :
SEASONAL(t) = k * (datavalue(t)/I(t-L)) + (1-k) * (SEASONAL(t-1) + b(t-1))
- La deuxième équation est la valeur de tendance calculée, et c'est une moyenne pondérée de la différence entre la moyenne actuelle et précédente et la tendance de la période précédente. b(t) représente la tendance moyenne. La constante de poids est g :
b(t) = g * (SEASONAL(t)-SEASONAL(t-1)) + (1-g) * (b(t-1))
- La troisième équation est l'index saisonnier calculé, et c'est une moyenne pondérée de la valeur de données actuelle divisée par la moyenne actuelle et l'index saisonier de la saison précédente. I(t) représente le coefficient saisonnier moyen. La constante de poids est p :
I(t) = p * (datavalue(t)/SEASONAL(t)) + (1 - p) * I(t-L)
Ces équations sont résolues pour tirer la moyenne glissante triple. La première moyenne glissante est mise à la première valeur de données. Les premières valeurs des facteurs de saisonnalité sont calculées selon le nombre maximal de périodes complètes de données dans la source de données, tandis que la première tendance est calculée selon deux périodes de données. Ces valeurs sont calculées de la façon suivante :
- Le premier facteur de tendance est calculé par la formule suivante :
b(0) = (1/L) ((y(L+1)-y(1))/L + (y(L+2)-y(2))/L + ... + (y(2L) -
y(L))/L )
- Le calcul du premier facteur de saisonnalité est basé sur la moyenne des valeurs de données de chaque période, A(j) (1<=j<=N) :
A(j) = ( y((j-1)L+1) + y((j-1)L+2) + ... + y(jL) ) / L
- Ensuite, le premier facteur de périodicité est donné par la formule suivante, où N est le nombre de périodes complètes disponibles dans les données, L est le nombre de points par période et n est un point dans la période (1<= n <= L) :
I(n) = ( y(n)/A(1) + y(L+n)/A(2) + ... + y((N-1)L+n)/A(N) ) / N
Il faut choisir les trois constantes soigneusement. Les meilleurs résultats sont généralement obtenus en minimisant l'erreur quadratique moyenne (MSE) entre les valeurs de données et les moyennes calculées. Si vous variez les valeurs pour npoint1 et npoint2, cela peut modifier les résultats, et certaines valeurs peuvent produire une meilleure approximation. Pour rechercher une meilleure approximation, vous pouvez rechercher des valeurs qui minimisent la MSE.
L'équation utilisée pour prévoir au-delà du point de données avec le lissage exponentiel triple est :
forecast(t+m) = (SEASONAL(t) + m * b(t)) / I(t-L+MOD(m/L))
où :
- m
- Est le nombre de périodes en avance pour la prévision.
Exemple : Calcul d'une colonne de lissage exponentiel triple
Dans la requête suivante, les données ont de la saisonnalité mais pas de tendance. Toutefois, npoint2 est défini à la hausse (1000) pour rendre le facteur de la tendance négligeable lors du calcul :
SET HISTOGRAM = OFF
TABLE FILE VIDEOTRK
SUM TRANSTOT
BY TRANSDATE
ON TRANSDATE RECAP SEASONAL/D10.1 = FORECAST(TRANSTOT,1,3,'SEASONAL',
3,3,1000,1);
WHERE TRANSDATE NE '19910617'
END
Dans la sortie, npredict est 3. Par conséquent, trois périodes, (neuf points,
nperiod* npredict) sont générées.

xUtilisation d'une équation de régression linéaire
L'équation de régression linéaire estime des valeurs en supposant que la variable dépendante (les nouvelles valeurs calculées) et la variable indépendante (les valeurs des champs de tri) sont liées par une fonction représentant une ligne droite :
y = mx + b
où :
- y
- Est la variable dépendante.
- x
- Est la variable indépendante.
- m
- Est la pente de la ligne.
- b
- Est le segment sur l'axe y.
REGRESS emploie une technique appelée « moindres carrés ordinaires » pour calculer des valeurs pour m et b qui minimisent la somme des différences carrées entre les données et la ligne résultante.
Les formules suivantes montrent la façon dont
m et b sont calculés.


où :
- n
- Est le nombre de points de données.
- y
- Sont les valeurs de données (variables dépendantes).
- x
- Sont les valeurs de critères de tri (variables indépendantes).
Les valeurs de tendance ainsi que les valeurs de prédiction sont calculés à partir de l'équation de régression linéaire.
Exemple : Calcul d'un nouveau champ de régression linéaire
TABLE FILE CAR
PRINT MPG
BY DEALER_COST
WHERE MPG NE 0.0
ON DEALER_COST RECAP FORMPG=FORECAST(MPG,1000,3,'REGRESS');
END
La sortie est :
DEALER_COST MPG FORMPG
2,886 27 25.51
4,292 25 23.65
4,631 21 23.20
4,915 21 22.82
5,063 23 22.63
5,660 21 21.83
21 21.83
5,800 24 21.65
6,000 24 21.38
7,427 16 19.49
8,300 18 18.33
8,400 18 18.20
10,000 18 16.08
11,000 18 14.75
11,194 9 14.50
14,940 11 9.53
15,940 0 8.21
16,940 0 6.88
17,940 0 5.55Remarque :
- Trois valeurs prévues de FORMPG sont calculées. Pour les valeurs au-delà de la plage des données, des nouvelles valeurs de DEALER_COST sont générées en additionnant la valeur intervalle (1,000) à la valeur de DEALER_COST précédente.
- Il n'y a pas de valeurs MPG pour les valeurs de DEALER_COST générées.
- Chaque valeur de FORMPG est calculée en utilisant une ligne de régression, ce qui est calculée en utilisant toutes les valeurs de données réelles de MPG.
DEALER_COST est la variable indépendante (x) et MPG est la variable dépendante (y). L'équation est utilisée pour calculer la tendance et les valeurs prévues de MPGFORECAST.
Dans ce cas, l'équation est à peu près la suivante :
FORMPG = (-0.001323 * DEALER_COST) + 29.32
Les valeurs de prédiction sont (en raison de l'arrondissement, les valeurs ne sont pas exactement celles calculées par FORECAST, mais elles démontrent le processus de calcul) :
DEALER_COST | Calcul | FORMPG |
|---|
15,940 | (-0.001323 * 15,940) + 29.32 | 8.23 |
16,940 | (-0.001323 * 16,940) + 29.32 | 6.91 |
17,940 | (-0.001323 * 17,940) + 29.32 | 5.59 |
xTechniques de génération de rapports FORECAST
Vous pouvez utiliser FORECAST plusieurs fois dans une requête. Cependant, les requêtes FORECASTPrévision doivent toutes spécifier les mêmes champ de tri, intervalle et nombre de prédictions. Les seules choses pouvant changer sont le champ RECAP, la méthode, le champ utilisé pour calculer les valeurs de FORECAST et le nombre de points servant à faire la moyenne. Les nouveaux paramètres ne seront pas reconnus si vous changez n'importe lequel des autres paramètres.
Pour déplacer une colonne FORECASTPrévision dans la sortie de rapport, utilisez une commande COMPUTE vide comme paramètre substituable pour le champ FORECAST. Le type de données (I, F, P, D) doit être le même dans la commande COMPUTE et la commande RECAP.
Pour faciliter l'interprétation des résultats de la procédure de reporting, vous pouvez créer un champ indiquant si la valeur de FORECAST de chaque ligne est une valeur de prévision ou non. Pour ce faire, définissez un champ virtuel dont la valeur est toujours une constante autre que zéro. Les lignes dans la sortie de la procédure de rapport qui représentent des enregistrements réels dans la source de données s'affichent avec cette constante. Les lignes représentant des valeurs de prévison affichent un zéro. Vous avez également la possibilité de transmettre ce champ par propagation vers un fichier HOLD.
Exemple :
Génération de plusieurs colonnes FORECAST dans une requête
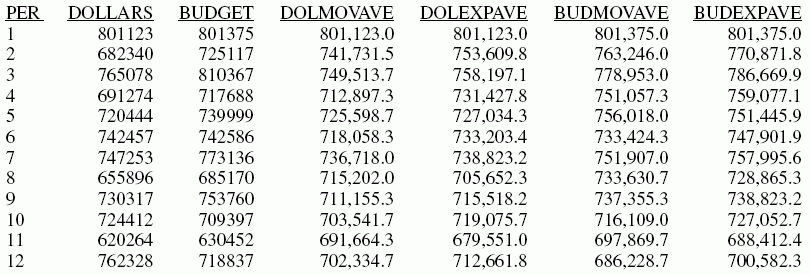
Dans cet exemple, des moyennes mobiles et exponentielles sont calculées pour les champs DOLLARS et BUDDOLLARS de la source de données GGSALES. Le champ de tri, l'intervalle et le nombre de prévisions sont les mêmes pour tous ces calculs.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM DOLLARS AS 'DOLLARS' BUDDOLLARS AS 'BUDGET'
BY CATEGORY NOPRINT BY PERIOD AS 'PER'
WHERE SYEAR EQ 97 AND CATEGORY EQ 'Coffee'
ON PERIOD RECAP DOLMOVAVE/D10.1= FORECAST(DOLLARS,1,0,'MOVAVE',3);
ON PERIOD RECAP DOLEXPAVE/D10.1= FORECAST(DOLLARS,1,0,'EXPAVE',4);
ON PERIOD RECAP BUDMOVAVE/D10.1 = FORECAST(BUDDOLLARS,1,0,'MOVAVE',3);
ON PERIOD RECAP BUDEXPAVE/D10.1 = FORECAST(BUDDOLLARS,1,0,'EXPAVE',4);
END
La sortie est montrée ci-dessous.
Exemple : Déplacer la colonne FORECAST
Dans l'exemple suivant, une commande COMPUTE vide est utilisée comme paramètre substituable pour placer le champ DOLLARS après le champ MOVAVE. Bien que les commandes COMPUTE et RECAP spécifient les deux le format de MOVAVE (du même type de données), c'est le format de la commande RECAP qui s'impose.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS
COMPUTE MOVAVE/D10.2 = ;
DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY EQ 'Coffee'
ON PERIOD RECAP MOVAVE/D10.1= FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La sortie est montrée ci-dessous.
Category PERIOD Unit
Sales MOVAVE Dollar
SalesCoffee 1 61666 801,123.0 801123
2 54870 741,731.5 682340
3 61608 749,513.7 765078
4 57050 712,897.3 691274
5 59229 725,598.7 720444
6 58466 718,058.3 742457
7 60771 736,718.0 747253
8 54633 715,202.0 655896
9 57829 711,155.3 730317
10 57012 703,541.7 724412
11 51110 691,664.3 620264
12 58981 702,334.7 762328
13 0 694,975.6 0
14 0 719,879.4 0
15 0 705,729.9 0
Exemple : Distinction entre les lignes de données et les lignes de prédiction
Dans l'exemple suivant, le champ virtuel DATA_ROW a la valeur 1 pour chaque ligne de la source de données. Pour les lignes prévues, il a la valeur 0. Le champ PREDICT est calculé avec la valeur YES pour les lignes prévues et avec la valeur NO pour les lignes contenant des données.
DEFINE FILE CAR
DATA_ROW/I1 = 1;
END
TABLE FILE CAR
PRINT DATA_ROW
COMPUTE PREDICT/A3 = IF DATA_ROW EQ 1 THEN 'NO' ELSE 'YES' ;
MPG
BY DEALER_COST
WHERE MPG GE 20
ON DEALER_COST RECAP FORMPG/D12.2=FORECAST(MPG,1000,3,'REGRESS');
ON DEALER_COST RECAP MPG =FORECAST(MPG,1000,3,'REGRESS');
END
La sortie est :
DEALER_COST DATA_ROW PREDICT MPG FORMPG
2,886 1 NO 27.00 25.65
4,292 1 NO 25.00 23.91
4,631 1 NO 21.00 23.49
4,915 1 NO 21.00 23.14
5,063 1 NO 23.00 22.95
5,660 1 NO 21.00 22.21
1 NO 21.00 22.21
5,800 1 NO 24.20 22.04
6,000 1 NO 24.20 21.79
7,000 0 YES 20.56 20.56
8,000 0 YES 19.32 19.32
9,000 0 YES 18.08 18.08