Dans cette section : Référence : |
Lors de la jointure de deux sources de données, il se peut que des enregistrements dans un des fichiers manquent des enregistrements correspondants dans l'autre fichier. Lorsqu'un rapport omet des enregistrements qui ne se trouvent pas dans les deux fichiers, la jointure s'appelle une jointure interne. Lorsqu'un rapport affiche tous les enregistrements correspondants, en plus de tous les enregistrements du fichier hôte qui manquent d'enregistrements de référence correspondants, la jointure s'appelle une jointure externe gauche.
La commande SET ALL détermine la façon dont toutes les jointures sont implémentées. Si vous lancez la commande SET ALL=ON, toutes les jointures sont traitées comme des jointures externes. Où SET ALL=OFF, le paramètre par défaut, toutes les jointures sont traitées comme des jointures internes.
Toute commande JOIN peut spécifier explicitement le type de jointure à effectuer en remplaçant localement la définition globale. Cette syntaxe est supportée pour FOCUS, XFOCUS, Relational, VSAM, IMS et Adabas. Si vous ne spécifiez pas de type de jointure dans la commande JOIN, la définition du paramètre ALL détermine le type de jointure à réaliser.
Vous pouvez aussi joindre des sources de données en utilisant une des deux techniques pour déterminer la façon de faire correspondre des enregistrements à partir des différentes sources de données. La première technique s'appelle une équijonction et la deuxième s'appelle une jointure conditionnelle. Avant de choisir une technique de jointure, il est important de savoir que lorsqu'il y a une condtion d'égalité entre deux sources de données, il est plus efficace d'utiliser une équijonction qu'une jointure conditionnelle.
Vous pouvez utiliser une structure d'équijonction lorsque vous joignez deux sources de données ou plus ayant deux champs, dont un dans chaque source de données, avec des formats (caractères, numérique ou date) et des valeurs en commun. Un exemple d'une équijonction se voit dans la jointure d'un champ de code de produit dans une source de données de vente (le fichier hôte) au champ de code de produit dans une source de données de produit (le fichier de référence). Pour plus d'informations à propos de l'utilisation d'équijonctions, consultez Création d'une équijonction.
La jointure conditionnelle emploie la syntaxe basée sur WHERE pour spécifier des jointures basées sur des critères WHERE, et non seulement sur l'égalité entre champs. De plus, les champs de jointure hôte et de référence ne doivent pas être au même format. Supposez qu'une source de données liste des employés en fonction de leurs numéros d'identifiant (le fichier hôte), et une autre source de données liste des cours de formation et les employés qui y sont assistés (le fichier de référence). A l'aide d'une jointure conditionnelle, vous pouvez joindre un identifiant employé dans le fichier hôte à un identifiant employé dans le fichier de référence afin de déterminer quels employés ont assisté aux cours de formation à une période comprise entre deux dates (la condition WHERE). Pour plus d'informations à propos des jointures conditionnelles, consultez Utilisation d'une jointure conditionnelle.
Les jointures peuvent aussi être uniques ou non uniques. Une structure de jointures unique ou une à une fait correspondre une valeur dans la source de données hôte à une valeur dans la source de données de référence. Un exemple d'une structure d'équijonction est la jointure d'un identifiant employé dans une source de données d'employés à un identifiant employé dans une source de données de salaires.
Une structure de jointure non unique ou une à une fait correspondre une valeur dans la source de données hôte aux valeurs multiples dans le champ de référence. Joindre un identifiant employé dans une source de données d'employés d'une société à un identifiant employé dans une source de données qui liste tous les cours de formation proposés par cette société a pour résultat une liste de tous les cours auxquels chaque employé a assisté, ou une jointure de la seule instance de chaque identifiant dans le fichier hôte aux instances multiples de cet identifiant dans le fichier de référence.
Pour plus d'informations à propos des jointures uniques et non uniques, consultez Structures jointes uniques et non uniques.
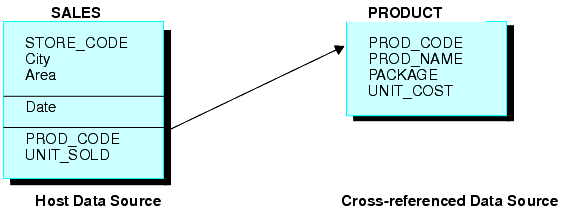
Considérez les sources de données SALES et PRODUCT. Chaque enregistrement dans SALES peut contenir de nombreuses instances du champ PROD_CODE. Comme il serait redondant de stocker les informations de produit associées à chaque instance du code de produit, PROD_CODE dans la source de données SALES est joint à PROD_CODE dans la source de données PRODUCT. PRODUCT comprend une seule instance de chaque code de produit ainsi que des informations de produit associées, économisant donc de l'espace et le rendant plus facile à maintenir les informations de produit. Voici une illustraction de la structure jointe, qui est un exemple d'une équijonction :
L'utilisation des sources de données en tant que fichiers hôte et fichiers de référence dans des structures jointes dépend des types de sources de données que vous joignez :
SET PASS = pswd1 IN file1, pswd2 IN file2
Les informations DBA individuelles sont toujours applicables à chaque fichier dans la jointure. Pour plus de détails sur l'attribut DBAFILE, reportez-vous au manuel Description de données en langage WebFOCUS .
Comment : |
Dans une structure jointe unique, une valeur dans le fichier hôte correspond à une valeur dans le champ de référence. Dans une structure jointe non unique, une valeur dans le champ d'hôte correspond aux valeurs multiples dans le champ de référence.
Le paramètre ALL dans une commande JOIN indique que la structure jointe est non unique.
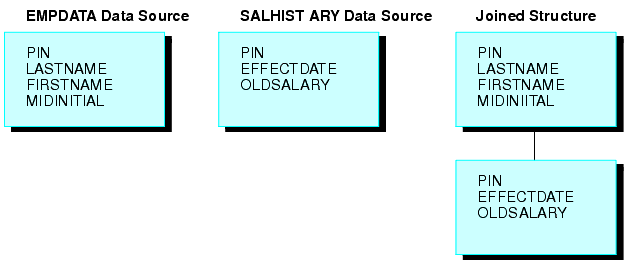
L'exemple suivant illustre une structure jointe unique. Deux sources de données FOCUS sont jointes : une source de données EMPDATA et une source de données SALHIST. Les deux sources de données sont organisées en fonction de PIN, et elles sont jointes sur un champ PIN dans les segments racines des deux fichiers. Chaque PIN comprend une instance de segments dans la source de données EMPDATA, et une instance dans la source de données SALHIST. Pour joindre ces deux sources de données, lancez la commande JOIN suivante :
JOIN PIN IN EMPDATA TO PIN IN SALHIST
Si une valeur de champ dans le fichier hôte peut se trouver dans plusieurs instances de segments dans le fichier de référence, vous devez inclure la phrase ALL dans la syntaxe JOIN. Cette structure s'appelle une structure jointe non unique.
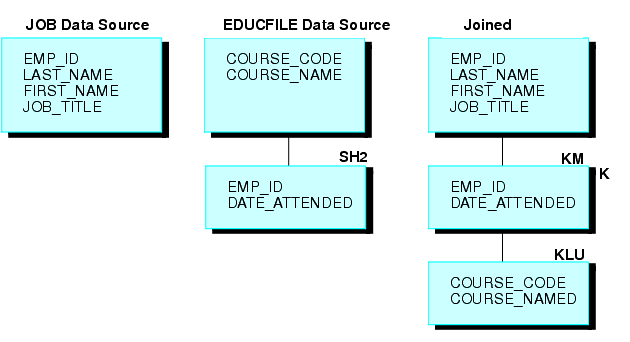
Par exemple, supposez que deux sources de données FOCUS sont jointes : la source de données JOB et une source de données EDUCFILE qui enregistre la présence des employés à des cours de formation internes. La structure jointe s'affiche dans le diagramme suivant.
La source de données JOB est organisée par employé, mais la source de donnes EDUCFILE est organisée par cours. Les sources de données sont jointes sur le champ EMP_ID. Comme un employé a un seul poste mais qu'il peut assister à plusieurs cours, l'employé a une seule instance de segments dans la source de données JOB mais autant d'instances dans la source de données EDUCFILE que le nombre de cours auxquels il a assisté.
Pour joindre ces deux sources de données, lancez la commande JOIN suivante, en utilisant la phrase ALL :
JOIN EMP_ID IN JOB TO ALL EMP_ID IN EDUCFILE
Si un segment parent contient deux ou plusieurs segments enfant qui contiennent eux-mêmes plusieurs enfants, il se peut que le rapport affiche à tort une valeur manquante. Cela a pour effet que les autres valeurs enfant sont mal alignées dans le rapport. Les valeurs mal alignées s'appellent des valeurs décalées. Le paramètre JOINOPT assure l'alignement correct de la sortie en faisant des corrections sur les valeurs décalées.
SET JOINOPT={NEW|OLD}où :
Remarque : le paramètre JOINOPT permet également des jointures entre différents types de données numériques. Pour plus de détails, reportez-vous à Jointure de champs avec différents types de données numériques.
L'exemple suivant présente un scénario hypothétique dans lequel vous utilisez le paramètre JOIN pour corriger les instances de valeurs décalées. Les valeurs décalées affichent les valeurs manquantes de sorte que chaque valeur est décalée par une ligne.
Un fichier hôte à segment unique (ROUTES) est joint à deux fichiers (ORIGIN et DEST), dont chacun contient deux segments. Les fichiers sont joints pour créer un rapport présentant tous les numéros de train et la ville qui correspond à chaque gare.
La requête suivante imprime la ville de départ (OR_CITY) et celle d'arrivée (DE_CITY). Notez que les données manquantes sont produites, ayant pour résultat que les données correspondant aux gares et aux villes sont décalées, c'est-à-dire mal placées par une ligne.
TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
La sortie est :
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL . 202 BOS BOSTON BLT ATLANTA 303 DET DETROIT BOS BALTIMORE 404 CHI CHICAGO DET BOSTON 505 BOS BOSTON STL DETROIT 505 BOS . STL ST. LOUIS
Si vous lancez la commande SET JOINOPT=NEW, cela permet de récupérer les segments dans l'ordre attendu (de gauche à droite et de haut et bas), sans données manquantes.
SET JOINOPT=NEW TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
Le rapport correct ne comprend que 5 lignes, non pas 6, et les données correspondant aux gares et aux villes sont alignées correctement. La sortie est :
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL ATLANTA 202 BOS BOSTON BLT BALTIMORE 303 DET DETROIT BOS BOSTON 404 CHI CHICAGO DET DETROIT 505 BOS BOSTON STL ST. LOUIS
Référence : |
Vous pouvez joindre une source de données FOCUS ou IMS à elle-même, créant ainsi une structure récurrente. Dans le type de structure récurrente le plus commun, un segment parent est joint à un segment descendant, de sorte que le segment parent devienne l'enfant du descendant. Cette technique (utile pour stocker des nomenclatures, par exemple) vous permet de faire un rapport à partir des sources de données comme si elles ont plus de niveaux de segments qu'il y en a réellement.
Par exemple, la source de données suivante, GENERIC, consiste des segments A et B.
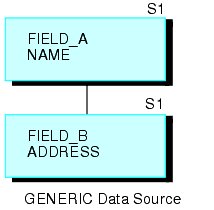
La requête suivante crée une structure récurrente :
JOIN FIELD_B IN GENERIC TAG G1 TO FIELD_A IN GENERIC TAG G2 AS RECURSIV
Cela a pour résultat la structure jointe suivante.
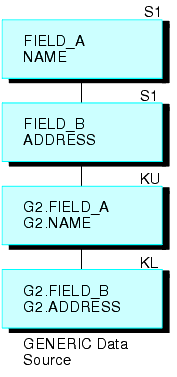
Notez que les deux segments sont répétés en bas. Pour faire référence aux champs dans les segments répétés (autre que le champ auquel vous effectuez une jointure), préfixez les noms de balise aux noms de champs et aux alias et séparez-les avec un point, ou ajoutez les quatre premiers caractères du nom JOIN aux noms de champ et aux alias. Dans l'exemple ci-dessus, le nom JOIN est récurrent (RECURSIV). Vous devez faire référence au champ FIELD_B du segment en bas comme G2.FIELD_B (ou RECUFIELD_B). Pour plus d'informations, consultez Notes d'utilisation pour les structures jointes récurrentes.
Cet exemple explique la façon d'utiliser des jointures récurrentes afin de stocker et faire un rapport sur une nomenclature. Supposez que vous concevez une source de données appelée AIRCRAFT, qui contient la nomenclature de l'avion d'une société. La source de données enregistre des données relatives à trois niveaux de matériaux d'avion : structures de jointure récursives:
La source de données doit enregistrer chaque pièce, la description de la pièce et les sous-pièces qui composent la pièce. Certaines pièces, telles que les écroux et les boulons, se trouvent partout dans l'avion. Si vous concevez une structure à trois segments, dont un segment pour chaque niveau de pièces, les descriptions des pièces courantes se répètent à chaque endroit où ces dernières sont utilisées.
Pour réduire cette répétition, concevez une source de données qui n'a que deux segments, comme le montre le diagramme ci-après. Le segment supérieur décrit chaque pièce de l'avion, Le segment inférieur liste les pièces sans descriptions.
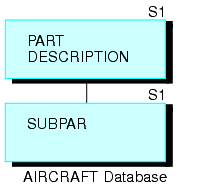
Toute pièce (à part les grandes divisions) s'affiche dans le segment supérieur, où elle est décrite, et dans le segment inférieur, où elle est listée comme un des composants d'une plus grande pièce. (Les pièces les plus petites, telles que les écroux et les boulons, s'affichent dans le segment inférieur sans instance enfant dans le segment inférieur). Notez que chaque pièce, peu importe combien elle est utilisée dans l'avion, n'est décrite qu'une fois.
Si vous joignez le segment inférieur au segment supérieur, les descriptions des pièces dans le segment inférieur peuvent être récupérées. Les divisions principales du premier niveau peuvent aussi être associées aux sous-pièces du troisième niveau, en passant du premier niveau au deuxième niveau au troisième niveau. Ainsi, la structure se comporte comme une source de données du troisième niveau, bien qu'elle soit réellement une source de données du deuxième niveau plus efficace.
Par exemple, CABIN est une division du premier niveau qui s'affiche dans le segment supérieur. Elle liste SEATS comme un composant dans le segment inférieur. SEATS s'affiche aussi dans le segment supérieur. Il liste BOLTS comme composant dans le segment inférieur. Si vous joignez le segment inférieur au segment supérieur, vous pouvez basculer de CABIN à SEATS et de SEATS à BOLTS.

Joignez le segment inférieur au segment supérieur avec cette commande JOIN :
JOIN SUBPART IN AIRCRAFT TO PART IN AIRCRAFT AS SUB
Cela a pour résultat la structure récurrente suivante.
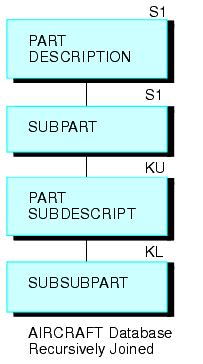
Vous pouvez par la suite créer un rapport aux trois niveaux de données avec cette commande TABLE (le champ SUBDESCRIPT décrit le contenu du champ SUBPART) :
TABLE FILE AIRCRAFT PRINT SUBPART BY PART BY SUBPART BY SUBDESCRIPT END
| WebFOCUS |