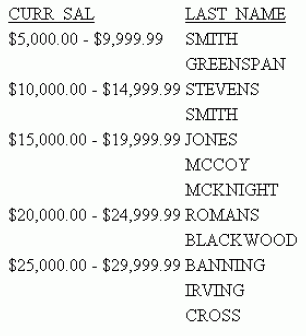
Dans les rapports tabulaires, vous pouvez regrouper les données numériques en divers quantiles (centiles, déciles, quartiles, etc.). Par exemple, vous pouvez regrouper en déciles les résultats d'examens d'un groupe d'étudiants afin de déterminer quels étudiants sont dans le 10 % supérieur de la classe, ou bien regrouper des données de ventes de manière semblable pour déterminer quels vendeurs sont dans la moitié supérieure de tous les vendeurs, en se basant sur la totalité des ventes.
Le groupement se fait en fonction des valeurs du champ vertical (BY) sélectionné et les données sont réparties aussi également que possible entre le nombre de groupes de quantiles spécifié.
x
Syntaxe : Grouper des données numériques en quantiles
BY [ {HIGHEST|LOWEST} [k] ] tilefield [AS 'head1']
IN-GROUPS-OF n TILES [TOP m] [AS 'head2'] où :
- HIGHEST
-
trie les données dans l'ordre décroissant de sorte que les plus grandes valeurs de données soient mises dans le premier quantile.
- LOWEST
-
trie les données dans l'ordre décroissant de sorte que les plus grandes valeurs de données soient mises dans le premier quantile. Ceci est l'ordre de tri par défaut.
- k
-
est un nombre entier positif qui représente le nombre de groupes de quantiles à afficher dans le rapport. Par exemple, BY HIGHEST 2 affiche les deux quantiles non vides qui ont les plus grandes valeurs de données.
- tilefield
-
Est le champ dont les valeurs sont utilisées pour assigner les nombres de quantile.
- head1
-
Est un en-tête de colonne affichant les valeurs du champ de tri de quantile.
- n
-
est un nombre entier positif qui ne dépasse pas 32 767, spécifiant le nombre de quantiles à utiliser pour regrouper les données. Par exemple, cent quantiles produisent des centiles, alors que dix quantiles produisent des déciles.
- m
-
est un nombre entier positif indiquant la plus grande valeur de quantile à afficher dans le rapport. Par exemple, TOP 3 n'affiche aucune ligne de données qui est attribuée à un nombre de quantile supérieur à 3.
- head2
-
Est un nouvel en-tête de colonne affichant les nombres de quantile.
Remarque :
- La syntaxe accepte des nombres qui ne sont pas des nombres entiers pour k, n, et m. Sur z/OS et VM, les valeurs décimales sont arrondies à des nombres entiers ; sur UNIX et Windows, elles sont tronquées. Si les nombres fournis sont négatifs ou zéro, un message d'erreur est généré.
- k et m limittent le nombre de rangées affichées dans chaque rupture de tri dans le rapport. Si vous en spécifiez les deux, la valeur la plus restrictive contrôle l'affichage. Si k et m sont tous les deux supérieurs à n (le nombre de mosaïques), alors n est utilisé.
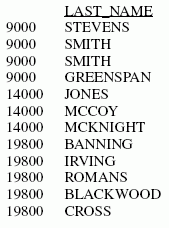
Exemple : Regrouper les données en cinq quantiles
L'exemple suivant illustre la façon de grouper des données en cinq quantiles.
TABLE FILE EMPLOYEE
PRINT LAST_NAME FIRST_NAME
BY DEPARTMENT
BY CURR_SAL IN-GROUPS-OF 5 TILES
END
La sortie est :
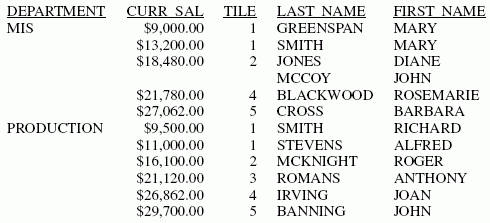
Notez que les quantiles sont attribués dans le critère de tri de niveau supérieur CATEGORY. Dans la catégorie ACTION, il n'y a pas de données attribuées au quantile 3. La catégorie PRODUCTION a cinq quantiles.
Exemple : Affichage des trois premiers groupes de quantile
Dans cet exemple, les employés avec les trois plus petits salaires sont groupés en cinq quantiles.
TABLE FILE EMPLOYEE
PRINT LAST_NAME FIRST_NAME
BY DEPARTMENT
BY LOWEST 3 CURR_SAL IN-GROUPS-OF 5 TILES
END
La sortie est :

Notez que la requête affiche trois groupes de quantiles dans chaque catégorie. Comme il n'y a pas de données attribuées au quantile 3 dans la catégorie ACTION, les quantiles 1, 2 et 4 s'affichent pour cette catégorie.
Exemple : Affichage de quantiles ayant une valeur égale ou inférieure à trois
Dans cet exemple, les employés avec les trois plus petits salaires sont listés et regroupés en cinq quantiles, mais seuls les quantiles qui se trouvent dans les trois premiers quantiles (quantiles 1, 2 ou 3) s'affichent dans le rapport. En outre, l'en-tête du champ TILES a été renommé (en utilisant la phrase AS) à DECILES.
TABLE FILE EMPLOYEE
PRINT LAST_NAME FIRST_NAME
BY DEPARTMENT
BY LOWEST 3 CURR_SAL IN-GROUPS-OF 5 TILES TOP 3 AS DECILES
END
La sortie est :

Comme aucunes données n'ont été assignées au quantile 3 dans la catégorie MIS, seulement les quantiles 1 et 2 s'affichent pour cette catégorie.