SEGNAME = segname, SEGTYPE = {KL|KLU}, PARENT = parentname, CRFILE = db_name, [CRSEGNAME = crsegname,] [DATASET = physical_filename,] $
donde:
- segname
Es el nombre asignado al segmento de referencia cruzada, en el origen de datos host.
- KL
Indica que este segmento es un descendiente en un origen de datos de referencia cruzada (visto desde la perspectiva del origen de datos host), con una relación de uno a varios con su segmento principal. KL significa con claves a través del enlace.
- KLU
Indica que este segmento es un descendiente en un origen de datos de referencia cruzada (visto desde la perspectiva del origen de datos host), con una relación de uno a uno con su segmento principal. KL significa único, con claves a través del enlace.
- parentname
El nombre del segmento principal en el origen de datos de referencia cruzada, visto desde la perspectiva del origen host.
- db_name
Es el nombre del origen de datos de referencia cruzada. Puede cambiar el nombre sin tener que reconstruir el origen de datos.
- crsegname
Es el nombre del segmento de referencia cruzada. Si no se especifica, se emplea el valor por defecto asignado a SEGNAME.
- physical_filename
Opcionalmente, es el nombre físico, dependiente de la plataforma, del origen de datos para CRFILE.
SEGNAME = SECSEG, SEGTYPE = KLU, PARENT = JOBSEG, CRFILE = JOBFILE, $ SEGNAME = SKILLSEG, SEGTYPE = KL, PARENT = JOBSEG, CRFILE = JOBFILE, $
Observe que el atributo CRKEY no se utiliza en la declaración de un segmento enlazado, puesto que el campo común del join (identificado por CRKEY) sólo debe especificarse para el segmento de referencia cruzada.
Tomemos el ejemplo de EMPLOYEE. JOBFILE e un origen de datos multisegmento:
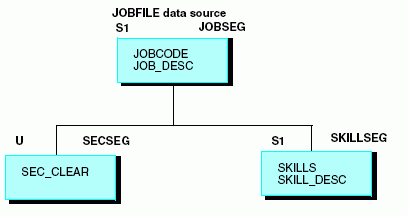
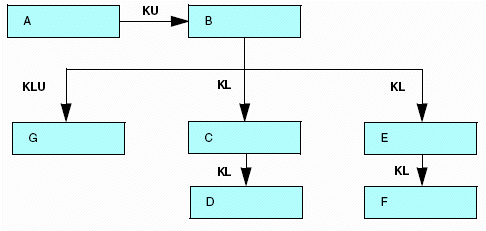
Desde su aplicación de origen de datos EMPLOYEE, puede que necesite la información de seguridad almacenada en el segmento SECSEG, y la relativa a los requisitos de puesto, almacenada en SKILLSEG. Después de crear un join, puede acceder a uno o a todos los demás segmentos del origen de datos de referencia cruzada, mediante el valor KL de SEGTYPE para una relación de uno a varios (vista desde el origen de datos host), y KLU para una relación de uno a uno (vista desde el origen de datos host). KL y KLU se usan para acceder a los segmentos descendientes en un origen de datos de referencia cruzada, para joins estáticos (KM) o dinámicos (DKM).
Al recuperar el valor JOBSEG desde JOBFILE, también se recuperan todos los elementos de JOBSEG que fuesen declarados con un SEGTYPE de KL o KLU, en el archivo máster EMPLOYEE:
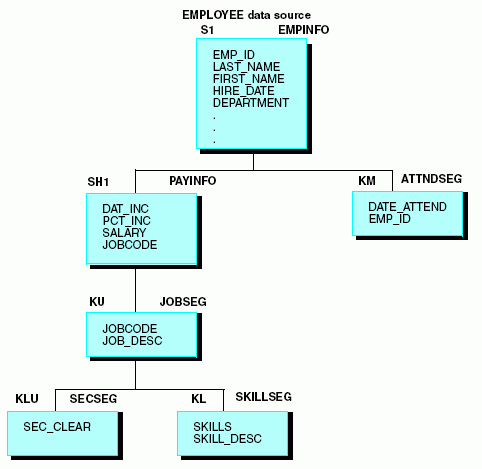
Recuerde que puede recuperar todos estos segmentos en un origen de datos de referencia cruzada, incluidos los descendientes y ancestros del segmento de referencia cruzada. Los segmentos ancestrales deben estar declarados en el archivo máster host, con un SEGTYPE de KLU, debido a que un segmento sólo puede tener un principal y la relación, por tanto, es de uno a uno, desde la perspectiva del origen de datos host.
Tomemos el origen de datos EDUCFILE utilizado en nuestro ejemplo. El segmento COURSEG es la raíz y describe cada curso. ATTNDSEG es un secundario e incluye la información de asistencia de los empleados:
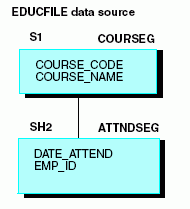
Al unir EMPINFO, de EMPLOYEE, a ATTNDSEG, de EDUCFILE, podrá acceder a las descripciones de los cursos de COURSEG, declarándolo como un segmento enlazado.
Desde esta perspectiva, COURSEG es un secundario de ATTNDSEG, como explica el siguiente diagrama.
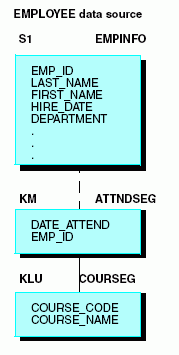
A continuación le mostramos las secciones del archivo máster EMPLOYEE, utilizadas en el ejemplo (los campos no esenciales y los segmentos no aparecen).
FILENAME = EMPLOYEE, SUFFIX = FOC, $ SEGNAME = EMPINFO, SEGTYPE = S1, $ FIELDNAME = EMP_ID, ALIAS = EID, FORMAT = A9, $ . . . SEGNAME = PAYINFO, SEGTYPE = SH1, PARENT = EMPINFO, $ FIELDNAME = JOBCODE, ALIAS = JBC, FORMAT = A3, $ . . . SEGNAME = JOBSEG, SEGTYPE = KU, PARENT = PAYINFO, CRFILE = JOBFILE, CRKEY = JOBCODE, $ SEGNAME = SECSEG, SEGTYPE = KLU,PARENT = JOBSEG, CRFILE = JOBFILE, $ SEGNAME = SKILLSEG, SEGTYPE = KL, PARENT = JOBSEG, CRFILE = JOBFILE, $ SEGNAME = ATTNDSEG, SEGTYPE = KM, PARENT = EMPINFO, CRFILE = EDUCFILE, CRKEY = EMP_ID, $ SEGNAME = COURSEG, SEGTYPE = KLU,PARENT = ATTNDSEG, CRFILE = EDUCFILE, $