Cómo: |
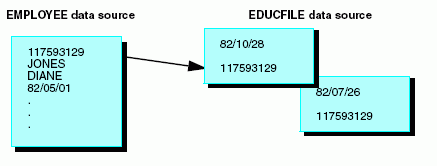
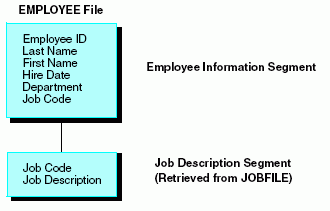
El segmento PAYINFO del origen de datos EMPLOYEE tiene un campo llamado JOBCODE. Este campo contiene un código que especifica el puesto del empleado.
La descripción completa del puesto y demás información relacionada, se almacena en un origen de datos diferente, llamado JOBFILE. Puede recuperar la descripción del puesto desde JOBFILE, localizando el registro cuyo JOBCODE coincida con el valor de JOBCODE en el origen de datos EMPLOYEE, como se aprecia en el siguiente diagrama:
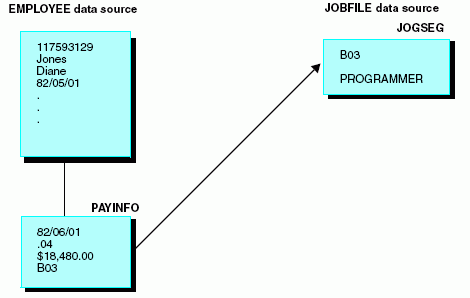
El uso de un join en esta situación evita tener que introducir y revisar la descripción del puesto, en cada registro del origen de datos EMPLOYEE. Basta con sólo mantener una lista de descripciones válidas de los puestos, en el origen de datos JOBFILE. Sólo tiene que hacer los cambios una vez, en JOBFILE, y aparecerán reflejados en todos los registros de los orígenes de de datos unidos, correspondientes a EMPLOYEE.
Para obtener el mayor grado de eficiencia, implemente el join de forma estática, puesto que la relación entre los códigos y las descripciones de puesto no suele cambiar.
Aunque los segmentos Información de empleado y Descripción de puesto se encuentran almacenados en orígenes de datos diferentes, en términos de generación de informes, el origen de datos EMPLOYEE se trata como si también contuviera el segmento Descripción de puesto, del origen de datos JOBFILE. La estructura actual del origen de datos JOBFILE no se ve afectada.
Para consultar el origen de datos EMPLOYEE:
SEGNAME = segname, SEGTYPE = KU, PARENT = parent, CRFILE = db_name, CRKEY = field, [CRSEGNAME = crsegname,] [DATASET = physical_filename,] $
donde:
- segname
Es el nombre con que se conoce el segmento de referencia cruzada, en el origen de datos host. Puede asignar cualquier nombres de segmento que sea válido, incluido el nombre original del segmento, en el origen de datos de referencia cruzada.
- parent
Es el nombre del segmento host.
- db_name
Es el nombre del origen de datos de referencia cruzada. Puede cambiar el nombre sin tener que reconstruir el origen de datos.
- field
Es el nombre común (nombre de campo o alias) del campo host y del campo de referencia cruzada. El nombre o alias debe ser el mismo para el campo host y el campo de referencia cruzada. Puede cambiar el nombre del campo sin tener que reconstruir el origen de datos, siempre que SEGTYPE permanezca igual.
Ambos campos deben tener el mismo tipo de formato y longitud.
El campo de referencia cruzada debe estar indexado (FIELDTYPE=I or INDEX=I).
- crsegname
Es el nombre del segmento de referencia cruzada. Si no se especifica, se emplea el valor por defecto asignado a SEGNAME. Una vez introducidos los datos en el origen de datos de referencia cruzada, no se puede cambiar el crsegname sin reconstruir el origen.
- physical_filename
Opcionalmente, es el nombre físico, dependiente de la plataforma, del origen de datos para CRFILE.
El valor KU de SEGTYPE indica que tiene claves y es único.
SEGNAME = JOBSEG, SEGTYPE = KU, PARENT = PAYINFO, CRFILE = JOBFILE, CRKEY = JOBCODE, $
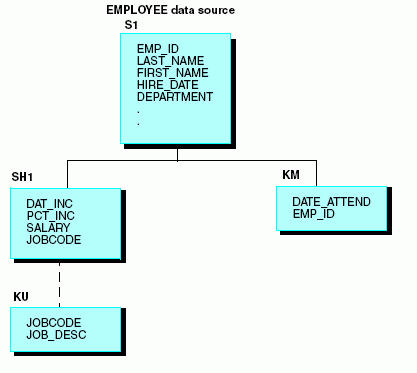
A continuación le mostramos las secciones relevantes del archivo máster EMPLOYEE (los campos no esenciales y los segmentos no aparecen):
FILENAME = EMPLOYEE, SUFFIX = FOC, $ SEGNAME = EMPINFO, SEGTYPE = S1, $ . . . SEGNAME = PAYINFO, SEGTYPE = SH1, PARENT = EMPINFO, $ FIELDNAME = JOBCODE, ALIAS = JBC, FORMAT = A3, $ . . . SEGNAME = JOBSEG, SEGTYPE = KU, PARENT = PAYINFO, CRFILE = JOBFILE, CRKEY = JOBCODE, $
Observe que sólo tiene que proporcionar el nombre del segmento de referencia cruzada. Los campos del segmento ya son conocidos, a través del archivo máster del origen de datos de referencia cruzada (en este ejemplo, JOBFILE). Observe que el atributo CRSEGNAME se ha omitido, debido a que, en el ejemplo, su nombre es idéntico al asignado al atributo SEGNAME.
El archivo máster del origen de datos de referencia cruzada, además del propio origen, deben ser accesibles cuando se está usando el origen de datos host. El origen de datos de referencia cruzada no tiene por qué tener datos.