Cómo describir un elemento individual
En las descripciones de los segmentos, puede describir los campos clave, el orden de clasificación o las relaciones de los segmentos. Los orígenes de datos de FOCUS no pueden tener más de 64 segmentos. Los orígenes de datos que no sean de FOCUS pueden incluir hasta 1024 segmentos. mientras que los orígenes de datos de FOCUS pueden participar en estructuras de join de hasta 1024 segmentos.
El uso de una vista indexada permite reducir el número máximo de segmentos en la estructura utilizada, más índices, a 191. Si AUTOINDEX está activado, puede que esté usando una vista indexada sin haberlo solicitado.
Puede codificar los segmentos de LOCATION, en un archivo máster, para ampliar el tamaño del archivo, apuntando hacia otra ubicación física de archivo.
También puede crear un campo que establezca marcas de hora en un segmento, por medio de AUTODATE.
La descripción de los tres atributos de segmento adicionales, que describen los joins entre los segmentos FOCUS, aparece en la sección Cómo definir un join en un archivo máster.
xCómo describir las claves, el orden de clasificación y las relaciones de los segmentos: SEGTYPE
Los orígenes de datos de FOCUS utilizan el atributo SEGTYPE para describir los campos clave de los segmentos y el orden de clasificación, además de la relación del segmento y su principal.
El atributo SEGTYPE también se usa con los orígenes de datos SUFFIX=FIX, para indicar una secuencia lógica de claves para el origen. SEGTYPE aparece descrito en Cómo describir un grupo de campos.
x
Sintaxis: Cómo Describir un segmento
Esta es la sintaxis del atributo SEGTYPE cuando se utiliza con un origen de datos FOCUS,
SEGTYPE = segtype
Los valores válidos son:
- SH[n]
Indica que los segmentos están clasificados de mayor a menor, según el valor de los n primeros campos del segmento. n puede ser cualquier número de 1 a 99. Si no lo especifica, se toma el valor por defecto, el 1.
- S[n]
Indica que los segmentos están clasificados de menor a mayor, según el valor de los n primeros campos del segmento. n puede ser cualquier número de 1 a 255. Si no lo especifica, se toma el valor por defecto, el 1.
- S0
Indica que el segmento no cuenta con un campo clave y que, por tanto, no está clasificado. Se añaden nuevos segmentos al final de la cadena. Cualquier búsqueda da comienzo por la posición actual.
Los segmentos S0 suelen usarse para almacenar texto de las aplicaciones, cuando éste debe ser recuperado según el orden en que se haya introducido y la aplicación no tenga que buscar segmentos específicos.
- (blank)
Indica que el segmento no cuenta con un campo clave y que, por tanto, no está clasificado. Se añaden nuevos segmentos al final de la cadena. Cualquier búsqueda da comienzo por el principio de la cadena.
Los segmentos con SEGTYPE = blank suelen usarse en situaciones en las que hay pocos segmentos y la información almacenada en el segmento no incluye un campo que actúa como clave.
Tenga en cuenta que los segmentos raíz no pueden ser de tipo SEGTYPE en blanco.
- U
Indica que el segmento es único, con una relación de uno a uno con su segmento principal. Tenga en cuenta que los segmentos únicos, descritos con SEGTYPE U no pueden tener secundarios.
- KM
Indica que éste es un segmento de referencia cruzada, unido al origen de datos mediante un join estático, definido en el archivo máster, con una relación de uno a varios al segmento host. Los joins definidos en el archivo máster aparecen descritos en Cómo definir un join en un archivo máster. El puntero principal-secundario se encuentra almacenado en el origen de datos.
- KU
Indica que éste es un segmento de referencia cruzada, unido al origen de datos mediante un join estático, definido en el archivo máster, con una relación de uno a uno con el segmento host (es decir, que es un segmento único). Los joins definidos en el archivo máster aparecen descritos en Cómo definir un join en un archivo máster. El puntero principal-secundario se encuentra almacenado en el origen de datos.
- DKM
Indica que éste es un segmento de referencia cruzada, unido al origen de datos mediante un join dinámico, definido en el archivo máster, con una relación de uno a varios con el segmento host. Los joins definidos en el archivo máster aparecen descritos en Cómo definir un join en un archivo máster. El puntero principal-secundario se resuelve a la hora de ejecutarse y, por tanto, permite añadir nuevos segmentos sin tener que realizar una reconstrucción.
- DKU
Indica que éste es un segmento de referencia cruzada, unido al origen de datos mediante un join dinámico, definido en el archivo máster, con una relación de uno a uno con el segmento host (es decir, que es un segmento único). Los joins definidos en el archivo máster aparecen descritos en Cómo definir un join en un archivo máster. El puntero principal-secundario se resuelve a la hora de ejecutarse y, por tanto, permite añadir nuevos segmentos sin tener que realizar una reconstrucción.
- KL
Indica que este segmento aparece descrito, en un join definido de archivo máster, como descendiente del segmento KM, KU, DKM o DKU de un origen de datos de referencia cruzada, y que tiene una relación de uno a varios con su principal.
- KLU
Indica que este segmento aparece descrito, en un join definido de archivo máster, como descendiente del segmento KM, KU, DKM o DKU de un origen de datos de referencia cruzada, y que tiene una relación de uno a uno con su principal (es decir, que es un segmento único).
x
Referencia: Notas de uso de SEGTYPE
Tenga en cuenta las siguientes reglas al usar el atributo SEGTYPE con un origen de datos FOCUS:
-
Alias. SEGTYPE no tiene alias.
-
Cambios. Puede cambiar un SEGTYPE de S[n] o SH[n] a S0 o b, o aumentar el número de campos clave. Para efectuar cualquier otro cambio en SEGTYPE debe usar el recurso REBUILD.
xCóm describir un campo clave
Utilice el atributo SEGTYPE para describir cuáles son los campos clave de un segmento. Los valores de estos determinan la secuencia de los segmentos. Las claves deben ser los primeros campos de un segmento. Puede especificar hasta 255 claves en un segmento que esté clasificado de menor a mayor (SEGTYPE = Sn), y un máximo de 99 en uno de mayor a menor (SEGTYPE = SHn). Para maximizar la eficiencia se recomienda especificar sólo las claves necesarias para que cada registro sea único. No es obligatorio hacer uso de las claves (SEGTYPE = S0 and SEGTYPE = blank).
Nota: Los campos de texto no pueden usarse como campos clave.
xCómo describir el orden de clasificación
En segmentos que no presenten claves, use el atributo SEGTYPE para describir el orden de clasificación del segmento. Puede clasificar un segmento de dos formas:
xCómo funciona el orden de clasificación
Supongamos que los siguientes campos de un segmento representan el código de un departamento y el apellido de un empleado:
|
06345
Jones
|
19887
Smith
|
19887
Frank
|
23455
Walsh
|
21334
Brown
|
Si establece SEGTYPE en S1, el código de departamento se convierte en el campo clave. (Observe que hay dos registros con valores de clave duplicados, que explican el uso de dos segmentos S2, más adelante. El uso de estos valores de clave duplicados no está recomendado con segmentos S1 y SH1.) Los segmentos están clasificados del siguiente modo:
|
06345
Jones
|
19887
Smith
|
19887
Frank
|
21334
Brown
|
23455
Walsh
|
Si cambia el orden de los campos para que el apellido aparezca antes del código de departamento y deja SEGTYPE como S1, el apellido pasa a ser la clave. Los segmentos están clasificados del siguiente modo:
|
Brown
21334
|
Frank
19887
|
Jones
06345
|
Smith
19887
|
Walsh
23455
|
Alternativamente, si deja el código de departamento como primer campo, pero establece SEGTYPE en S2, los segmentos se clasifican primero por el código de departamento y luego por el apellido:
|
06345
Jones
|
19887
Frank
|
19887
Smith
|
21334
Brown
|
23455
Walsh
|
xCómo describir las relaciones de los segmentos
El atributo SEGTYPE describe la relación entre un segmento y su segmento principal:
- Las relaciones físicas, de uno a uno suelen especificarse estableciendo SEGTYPE en U. Si uno de los segmentos aparece descrito como descendiente del segmento de referencia cruzada, en un join definido por un archivo máster, SEGTYPE se establece en KLU en la descripción del join.
- Las relaciones físicas, de uno a varios suelen especificarse estableciendo SEGTYPE en cualquier valor aceptable que empiece por S (como S0, SHn y Sn), en blanco o en KL, si el segmento aparece descrito como descendiente del segmento de referencia cruzada, en un join definido por un archivo máster.
- Los joins de uno a uno, definidos en un archivo máster, se especifican estableciendo SEGTYPE en KU o DKU, como se explica en Cómo definir un join en un archivo máster.
- Los joins de uno a varios, definidos en un archivo máster, se especifican estableciendo SEGTYPE en KM o DKM, como se explica en Cómo definir un join en un archivo máster.
xCómo almacenar un segmento en una ubicación distinta: LOCATION
Todos los segmentos de un origen de datos de FOCUS se almacenan por defecto en un solo archivo físico. Por ejemplo, todos los segmentos del origen de datos EMPLOYEE se almacenan en el origen de datos del mismo nombre.
Use el atributo LOCATION para especificar el almacenamiento de uno o varios segmentos en un archivo físico, independiente del archivo principal del origen de datos. El archivo LOCATION también se denomina división, o partición, horizontal. Puede usar un total de 64 archivos LOCATION por cada archivo máster (un atributo LOCATION por segmento, a excepción de la raíz). Esto resulta útil cuando se quiere crear un origen de datos que exceda el límite de FOCUS para un archivo de origen de datos individual, o cuando se necesita almacenar partes del origen de datos en distintas ubicaciones por razones de seguridad u otros motivos.
Existen al menos dos casos en que se debe utilizar el atributo LOCATION:
- Cada archivo físico está sujeto, de forma individual, al tamaño máximo de los archivos. Puede utilizar el atributo LOCATION para incrementar el tamaño de su origen de datos, mediante su división en varios archivos físicos, cada uno sujeto al límite de tamaño. (Consulte Cómo definir un join en un archivo máster para determinar si resulta más eficiente estructurar en varios orígenes de datos unidos.)
- También puede almacenar sus datos en archivos físicos, independientes, para aprovechar el hecho de que sólo deben estar presentes los segmentos necesarios para el informe. Los segmentos sin referencia, almacenados en orígenes de datos independientes, pueden mantenerse en distintos dispositivos para ahorrar espacio o implementar mecanismos de seguridad independientes. En algunos casos, la separación de los segmentos en orígenes de datos diferentes permite usar distintas unidades del disco.
Los orígenes de datos divididos requieren un mantenimiento de los archivos más cuidadoso. Tenga especial cuidado con los procedimientos efectuados por separado para dividir los orígenes de datos; por ejemplo, las copias de seguridad. Por ejemplo, si hace copias de seguridad de dos orígenes de datos relacionados, los martes y los jueves, y restaura la estructura FOCUS utilizando la copia del martes para una mitad, y la del jueves para la otra, no habrá ninguna forma de detectar esta discrepancia.
x
Sintaxis: Cómo Almacenar un segmento en una ubicación distinta
LOCATION = filename [,DATASET = physical_filename]
donde:
- filename
Es el ddname del archivo en que se va a almacenar el segmento.
- physical_filename
Es el nombre físico del origen de datos, en función de la plataforma.
Ejemplo: Cómo especificar la ubicación de un segmento
El ejemplo siguiente explica cómo utilizar el atributo LOCATION:
FILENAME = PEOPLE, SUFFIX = FOC, $
SEGNAME = SSNREC, SEGTYPE = S1, $
FIELD = SSN, ALIAS = SOCSEG, USAGE = I9, $
SEGNAME = NAMEREC, SEGTYPE = U, PARENT = SSNREC, $
FIELD = LNAME, ALIAS = LN, USAGE = A25, $
SEGNAME = HISTREC, SEGTYPE = S1, PARENT = SSNREC, LOCATION = HISTFILE, $
FIELD = DATE, ALIAS = DT, USAGE = YMD, $
SEGNAME = JOBREC, SEGTYPE = S1, PARENT = HISTREC,$
FIELD = JOBCODE, ALIAS = JC, USAGE = A3, $
SEGNAME = SKREC, SEGTYPE = S1, PARENT = SSNREC, $
FIELD = SCODE, ALIAS = SC, USAGE = A3, $
Esta descripción agrupa los cinco segmentos en dos archivos físicos, como se aprecia en el siguiente diagrama:
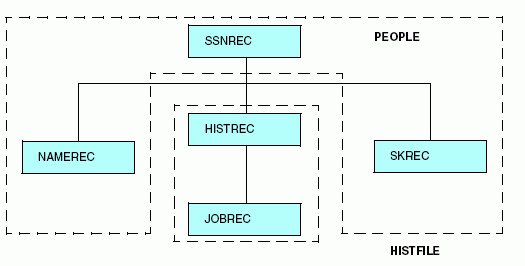
Tenga en cuenta que el segmento llamado SKREC, sin ningún atributo LOCATION, está almacenado en el origen de datos PEOPLE. Si no se ha especificado un atributo LOCATION para un segmento, queda colocado por defecto en el mismo archivo que su principal. En este ejemplo, puede asignar un segmento SKREC a un archivo distinto, especificando el atributo LOCATION en su declaración. Sin embargo, le recomendamos que sí especifique el atributo LOCATION; no deje que el sistema lo haga automáticamente.
xCómo separar campos de texto grandes
Los campos de texto se almacenan por defecto en un archivo físico, junto con campos que no lo son. Sin embargo, al igual que con los segmentos, los campos de texto pueden ocupar su propio archivo físico o puede combinar varios de ellos en uno o varios archivos. Para especificar que el campo de texto se almacene en un archivo independiente, utilice el atributo LOCATION en la definición del campo.
Por ejemplo, el texto de DESCRIPTION está almacenado en un archivo físico, independiente, llamado CRSEDESC:
FIELD = DESCRIPTION, ALIAS = CDESC, USAGE = TX50, LOCATION = CRSEDESC ,$
Si tiene más de un campo de texto, puede almacenar cada uno en su propio archivo; también puede guardar varios campos de este tipo en un solo archivo.
En el siguiente ejemplo, los campos de texto DESCRIPTION y TOPICS están almacenados en el CRSEDESC del archivo LOCATION. El campo de texto PREREQUISITE se encuentra en otro archivo, PREREQS.
FIELD = DESCRIPTION , ALIAS = CDESC, USAGE = TX50, LOCATION = CRSEDESC,$
FIELD = PREREQUISITE, ALIAS = PREEQ, USAGE = TX50, LOCATION = PREREQS ,$
FIELD = TOPICS, ALIAS = , USAGE = TX50, LOCATION = CRSEDESC,$
Al igual que con los segmentos, puede usar el atributo LOCATION en campos de texto largos. Sin embargo, a diferencia de LOCATION, los archivos LOCATION de los campos de texto deben estar presentes durante la solicitud, independientemente de que se haga o no referencia al campo de texto.
El atributo LOCATION puede usarse de forma independiente para los segmentos y los campos de texto. Puede usarlo en un campo de texto y no en un segmento. Además, puede utilizar el atributo LOCATION para ambos, el segmento y el campo de texto, en el mismo archivo máster.
Nota: Los nombres de los campos de texto están limitados a 12 caracteres, en los archivos máster de FOCUS. Los nombres de los campos de texto no están sujetos a esta limitación, en los archivos máster de XFOCUS. Sin embargo, en ambos tipos de origen de datos, los nombres de los alias de estos campos pueden tener hasta 66 caracteres.
xLímites de número de segmentos, archivos LOCATION, índices y campos de texto
El número máximo de segmentos para un archivo máster es de 64. Existe un límite para el número de segmentos de ubicación y archivos LOCATION de texto que se puede especificar. Este límite está basado en el número de entradas permitido en la Tabla de directorio de archivos (FDT en sus siglas en inglés), para los orígenes de datos FOCUS y XFOCUS. La FDT contiene los nombres de los segmentos del origen de datos, los de los campos indexados y los de los archivos LOCATION de los campos de texto.
x
Referencia: Entradas de FDT para un origen de datos FOCUS o XFOCUS
La FDT puede incluir hasta 189 entradas, de las cuales 64 pueden representar segmentos y archivos LOCATION. Cada archivo LOCATION único cuenta como una entrada de la FDT.
Determine el número máximo de archivos LOCATION que puede usar en un origen de datos, mediante la fórmula:
Available FDT entries = 189 - (Number of Segments + Number of Indexes)
Location files = min (64, Available FDT entries)
donde:
- Location files
Es el número máximo de segmentos LOCATION y archivos LOCATION de texto (hasta 64).
- Number of Segments
Es el número de segmentos del archivo máster.
- Number of Indexes
Es el número de campos indexados.
Por ejemplo, un origen de datos, de diez segmentos y 2 campos indexados, permite especificar hasta 52 segmentos LOCATION y archivos LOCATION para los campos de texto (189 - (10 + 2)). Utilizando la fórmula, el resultado es 177. Aunque el número máximo de archivos LOCATION nunca puede ser superior a 64.
Nota: Si especifica un campo de texto con un atributo LOCATION, el archivo principal se incluye en el recuento de archivos de ubicación de texto.
xCómo especificar un nombre de archivo físico para un segmento: DATASET
Además de especificar un atributo DATASET en el nivel de archivos de un archivo máster de FOCUS, puede especificar el atributo en el nivel de segmentos para definir el nombre del archivo físico de un segmento LOCATION, o de un segmento de referencia cruzada con nuevas definiciones de campos.
Para más información sobre cómo especificar el atributo DATASET en el nivel de archivos, consulte Cómo identificar un origen de datos.
Nota:
- Si emite un comando USE o una asignación explícita para el archivo, aparece una advertencia, indicando que se va a ignorar el atributo DATASET.
- No se pueden usar los atributos ACCESSFILE y DATASET en el mismo archivo máster.
El segmento con atributo DATASET debe ser de tipo SEGMENT o de referencia cruzada. Para segmentos de referencia cruzada:
- Si las declaraciones de campos están especificadas para los campos de referencia cruzada, el atributo DATASET constituye el único método de especificar un archivo físico, ya que no se lee el archivo máster y, por tanto, no puede recoger su atributo DATASET (si se ha especificado).
- Si las declaraciones de campos no están especificadas para los campos de referencia cruzada, se recomienda colocar el atributo DATASET en el nivel de archivos del archivo máster de referencia cruzada. En este caso, si especifica valores de DATASET diferentes en el nivel de segmentos del archivo máster host y en el nivel de archivos del archivo máster de referencia cruzada, se producirá un conflicto (mensaje FOC1998).
Si utiliza DATASET en un archivo máster cuyo origen de datos está administrado por el Servidor de bases de datos de FOCUS, se ignora el atributo DATASET del lado del servidor, ya que éste no puede leer los archivos máster de servicio de solicitudes de tablas.
El atributo DATASET del archivo máster tiene la prioridad más baja:
- Los atributos DATASET pueden ser anulados por una asignación explícita por parte del usuario.
- El comando USE de los orígenes de datos FOCUS anula los atributos DATASET y las asignaciones explícitas.
Nota: Si hay una asignación DATASET en vigor, emita un comando CHECK FILE para anularla mediante un comando de asignación explícita. El comando CHECK FILE retira la asignación creada por DATASET.
x
Sintaxis: Cómo Usar el atributo DATASET en el nivel de segmentos
Para un segmento LOCATION:
SEGNAME=segname, SEGTYPE=segtype, PARENT=parent, LOCATION=filename,
DATASET='physical_filename [ON sinkname]',$
Para un segmento de referencia cruzada:
SEGNAME=segname, SEGTYPE=segtype, PARENT=parent, [CRSEGNAME=crsegname,]
[CRKEY=crkey,] CRFILE=crfile, DATASET='filename1 [ON sinkname]',
FIELD=...
donde:
- filename
Es el nombre lógico del archivo LOCATION.
- physical_filename
Es el nombre físico dependiente de la plataforma del origen de datos.
- sinkname
Indica que el origen de datos está situado en el Servidor de bases de datos de FOCUS. Este atributo sólo es válido para los orígenes de datos de FOCUS.
La sintaxis en z/OS es:
{DATASET|DATA}='qualifier.qualifier ...'
o
{DATASET|DATA}='ddname ON sinkname'
En UNIX la sintaxis es:
{DATASET|DATA}='path/filename'
En Windows la sintaxis es:
{DATASET|DATA}='path\filename'
Ejemplo: Cómo asignar un segmento utilizando el atributo DATASET
En z/OS:
FILE = ...
SEGNAME=BODY,SEGTYPE=S1,PARENT=CARREC,LOCATION=BODYSEG,
DATASET='USER1.BODYSEG.FOCUS',
FIELDNAME=BODYTYPE,TYPE,A12,$
FIELDNAME=SEATS,SEAT,I3,$
FIELDNAME=DEALER_COST,DCOST,D7,$
FIELDNAME=RETAIL_COST,RCOST,D7,$
FIELDNAME=SALES,UNITS,I6,$
En z/OS con SU:
FILE = ...
SEGNAME=BODY,SEGTYPE=S1,PARENT=CARREC,LOCATION=BODYSEG,
DATASET='BODYSEG ON MYSU',
FIELDNAME=BODYTYPE,TYPE,A12,$
FIELDNAME=SEATS,SEAT,I3,$
FIELDNAME=DEALER_COST,DCOST,D7,$
FIELDNAME=RETAIL_COST,RCOST,D7,$
FIELDNAME=SALES,UNITS,I6,$
En UNIX/USS:
FILE = ...
SEGNAME=BDSEG,SEGTYPE=KU,CRSEGNAME=IDSEG,CRKEY=PRODMGR,
CRFILE=PERSFILE,DATASET='/u2/prod/user1/idseg.foc',
FIELD=NAME,ALIAS=FNAME,FORMAT=A12,INDEX=I, $
En Windows:
FILE = ...
SEGNAME=BDSEG,SEGTYPE=KU,CRSEGNAME=IDSEG,CRKEY=PRODMGR,
CRFILE=PERSFILE,DATASET='\u2\prod\user1\idseg.foc',
FIELD=NAME,ALIAS=FNAME,FORMAT=A12,INDEX=I, $
xMarcas de tiempo en segmentos FOCUS: AUTODATE
Cada segmento de un origen de datos de FOCUS puede incluir un campo de marca de tiempo, que registre la fecha y hora del último cambio efectuado en el segmento. El campo puede tener cualquier nombre, aunque su formato USAGE debe ser AUTODATE. El campo se rellena cada vez que se actualiza su segmento. La marca de tiempo se almacena con un formato HYYMDS, que puede manipularse para la generación de informes, mediante el uso de las funciones de fecha-hora.
Se puede definir un campo con USAGE = AUTODATE en cada segmento de un origen de datos de FOCUS. El campo AUTODATE no puede formar parte de un campo clave para el segmento. Por tanto, si SEGTYPE es S2, el campo AUTODATE no puede ser ni el primer ni el segundo campo definido en el segmento.
La especificación de formato de AUTODATE sólo es compatible con un campo real del archivo máster, no con los comandos DEFINE y COMPUTE de este archivo máster. Sin embargo, puede usar un comando DEFINE o COMPUTE para manipular o cambiar el formato del valor almacenado en el campo AUTODATE.
Después de añadir un campo AUTODATE a un segmento, debe efectuar un REBUILD del origen de datos. REBUILD no coloca una marca de tiempo en el campo. No tendrá un valor hasta que se inserte o actualice un segmento.
Si el campo AUTODATE queda actualizado por un procedimiento escrito por el usuario, se sobrescribe el valor especificado por éste al escribirse el segmento en el origen de datos. No se genera ningún mensaje para informar al usuario de que el valor se ha sobrescrito.
El campo AUTODATE es compatible con los índices. Sin embargo, es recomendable que se asegure de la necesidad del índice, debido a la carga utilizada para actualizar la fecha del índice cada vez que se modifica un segmento.
Si crea un archivo HOLD que contiene el campo AUTODATE, se propaga al archivo HOLD en forma de campo de fecha-hora, con el formato HYYMDS.
x
Sintaxis: Cómo Definir un campo AUTODATE para un segmento
FIELDNAME = fieldname, ALIAS = alias, {USAGE|FORMAT} = AUTODATE ,$donde:
- fieldname
Es cualquier nombre de campo válido.
- alias
Es cualquier alias válido.
Ejemplo: Cómo definir un campo AUTODATE
Cree el origen de datos EMPDATE efectuando un REBUILD DUMP del origen de datos EMPLOYEE y un REBUILD LOAD en el origen de datos EMPDATE. El archivo máster de EMPDATE es el mismo que el de EMPLOYEE, aunque se ha modificado FILENAME y se ha añadido el campo DATECHK:
FILENAME=EMPDATE, SUFFIX=FOC
SEGNAME=EMPINFO, SEGTYPE=S1
FIELDNAME=EMP_ID, ALIAS=EID, FORMAT=A9, $
FIELDNAME=DATECHK, ALIAS=DATE, USAGE=AUTODATE, $
FIELDNAME=LAST_NAME, ALIAS=LN, FORMAT=A15, $
.
.
.
Para añadir la información de marca de tiempo a EMPDATE, ejecute el siguiente procedimiento:
SET TESTDATE = 20010715
TABLE FILE EMPLOYEE
PRINT EMP_ID CURR_SAL
ON TABLE HOLD
END
MODIFY FILE EMPDATE
FIXFORM FROM HOLD
MATCH EMP_ID
ON MATCH COMPUTE CURR_SAL = CURR_SAL + 10;
ON MATCH UPDATE CURR_SAL
ON NOMATCH REJECT
DATA ON HOLD
END
A continuación, introduzca una referencia al campo AUTODATE en un comando DEFINE o COMPUTE, o muéstrelo mediante un comando de visualización. La siguiente solicitud calcula el número de días de diferencia entre la fecha 7/31/2001 y el campo DATECHK:
DEFINE FILE EMPLOYEE
DATE_NOW/HYYMD = DT(20010731);
DIFF_DAYS/D12.2 = HDIFF(DATE_NOW, DATECHK, 'DAY', 'D12.2');
END
TABLE FILE EMPDATE
PRINT DATECHK DIFF_DAYS
WHERE LAST_NAME EQ 'BANNING'
END
La salida es:
DATECHK DIFF_DAYS
------- ---------
2001/07/15 15:10:37 16.00
x
Referencia: Notas de uso de AUTODATE
- PRINT * y PRINT.SEG.fld imprime el campo AUTODATE.
- El Servidor de bases de datos de FOCUS actualiza el campo AUTODATE por segmento, utilizando la fecha y la hora del servidor.
- procesos de Maintain: campos AUTODATE en hora de COMMIT.
- DBA es compatible con el campo AUTODATE. Sin embargo, cuando se actualizan los campos no restringidos del segmento, el sistema también actualiza el campo AUTODATE.
- El campo AUTODATE no es compatible con los siguientes atributos: MISSING, ACCEPT y HELPMESSAGE.