Cómo describir un campo recurrente en un origen de datos de formato libre, VSAM o ISAM
Los orígenes de datos secuenciales, VSAM e ISAM pueden contener campos repetidos. Examine la siguiente estructura de datos:
Los campos C1 y C2 se repiten dentro de este registro de datos. C1 tiene un valor inicial, al igual que C2. A continuación, C1 proporciona un segundo valor para el campo, al igual que C2. Esto resulta en dos valores para los campos C1 y C2 por cada valor de los campos A y B.
El número de veces en que ocurren C1 y C2 no tiene por qué ser fijo. Puede depender del valor de un campo contador. Imagínese que B es el campo contador. En el caso mostrado más arriba, el valor del campo B es 2, ya que C1 y C2 ocurren dos veces. El valor del campo B en el registro siguiente puede ser de 7, 1, 0 o cualquier número que elija; los campos C1 y C2 ocurrirán ese mismo número de veces.
El número de veces en que ocurren C1 y C2 también puede variar. En este caso, todo lo que venga después de los campos A y B se trata como si fuera una serie de C1 y C2, alternándose hasta el final del registro.
Para describir estos campos recurrentes, colóquelos en un segmento independiente. Los campos A y B quedan colocados en el segmento raíz. Los campos C1 y C2, que son recurrentes en relación a A y B, se colocan en un segmento descendiente. Puede usar un atributo de segmento adicional, OCCURS, para indicar que estos segmentos representan campos recurrentes. En ciertos casos, puede que también necesite un segundo atributo llamado POSITION.
xCómo usar el atributo OCCURS
El atributo OCCURS es un atributo de segmento opcional utilizado para describir los registros que contienen campos o grupos de campos repetidos. Para definir estos registros, debe describir los campos que sólo ocurren una vez en un segmento, y los recurrentes en un segmento descendiente. El atributo OCCURS aparece en la declaración del segmento descendiente.
Su estructura de datos puede tener varios conjuntos de campos repetidos. Describa cada conjunto como un segmento independiente en su descripción del origen de datos. Los conjuntos de campos repetidos pueden dividirse en dos tipos básicos: paralelos o anidados.
x
Sintaxis: Cómo Especificar un campo repetido
OCCURS = occurstype
Los valores posibles de occurstype son:
- n
Un valor de número entero que muestra el número de casos (de 1 a 4095).
- fieldname
El nombre de un campo del segmento principal o de un campo virtual en un segmento anterior, cuyo valor de número entero contiene el número de casos en que aparece el segmento descendiente. Tenga en cuenta que, si emplea un campo virtual como valor de OCCURS, no podrá redefinirlo dentro ni fuera del archivo máster.
- VARIABLE
Indica que el número de casos varía de un registro a otro. El número de casos se calcula a partir de la longitud del registro (por ejemplo, si las longitudes de los campos del segmento suman 40 y se leen 120 caracteres, quiere decir que existen 3 casos).
Coloque el atributo OCCURS detrás del atributo PARENT, en su declaración de segmento.
Cuando combina distintos tipos de registros en un origen de datos, cada tipo sólo puede incluir un segmento definido como OCCURS=VARIABLE. Puede incluir descendientes de OCCURS (si contiene un grupo anidado), pero no puede estar seguido de cualquier otro segmento que pertenezca al principal. No puede haber segmentos a su derecha, dentro de la estructura jerárquica de datos. Esta restricción es necesaria para garantizar que los datos del registro se interpreten sin ambigüedades.
Ejemplo: Cómo usar el atributo OCCURS
Examine la siguiente estructura de datos simple:
Los campos C1 y C2 aparecen dos veces por cada aparición de los campos A y B. Por tanto, para describir este origen de datos debe colocar A y B en el segmento raíz y los campos C1 y C2 en el segmento descendiente, como se explica aquí:
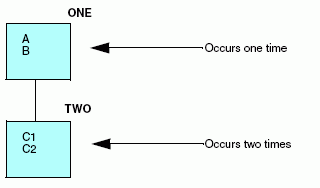
Describa este origen de datos del siguiente modo:
FILENAME = EXAMPLE1, SUFFIX = FIX, $
SEGNAME = ONE, SEGTYPE=S0, $
FIELDNAME = A, ALIAS=, USAGE = A2, ACTUAL = A2, $
FIELDNAME = B, ALIAS=, USAGE = A1, ACTUAL = A1, $
SEGNAME = TWO, PARENT = ONE, OCCURS = 2, SEGTYPE=S0, $
FIELDNAME = C1, ALIAS=, USAGE = I4, ACTUAL = I2, $
FIELDNAME = C2, ALIAS=, USAGE = I4, ACTUAL = I2, $
xCómo describir un conjunto paralelo de campos repetidos
Los conjuntos paralelos de campos repetidos son aquellos que no guardan ninguna relación entre ellos (es decir, no tienen una relación lógica ni de principal-secundario). Examine la siguiente estructura de datos:
A1 |
A2 |
B1 |
B2 |
B1 |
B2 |
C1 |
C2 |
C1 |
C2 |
C1 |
C2 |
En este ejemplo, los campos B1, B2, C1 y C2 aparecen repetidos en el registro. El número de veces en que aparecen B1 y B2 no tienen nada que ver con las repeticiones de C1 y C2. Los campos B1, B2, C1 y C2 son conjuntos paralelos de campos repetidos. Deben estar descritos en la descripción del origen de datos como secundarios del mismo elemento principal, el segmento que contiene los campos A1 y A2.
La estructura de datos mostrada más abajo refleja su relación:
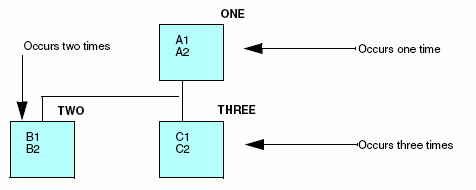
xCómo describir un conjunto anidado de campos repetidos
Los conjuntos anidados de campos repetidos son aquellos cuya recurrencia está relacionada de algún modo. Examine la siguiente estructura de datos:
A1 |
A2 |
B1 |
B2 |
C1 |
C1 |
B1 |
B2 |
C1 |
C1 |
C1 |
En este ejemplo, el campo C1 sólo tiene lugar cuando hay un caso de los campos B1 y C2. Ocurre en varias ocasiones, registradas por el campo contador, B2. No existe ningún conjunto de casos de C2 que no esté precedido por un caso de los campos B1 y B2. Los campos B1, B2 y C1 son conjuntos anidados de campos repetidos.
Estos campos repetidos se pueden representar mediante la siguiente estructura de datos:
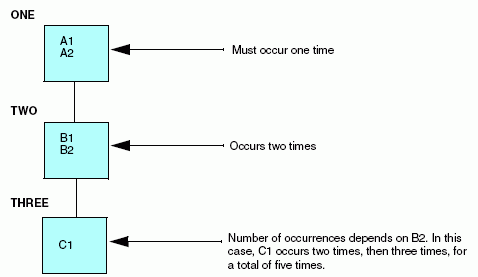
Puesto que el campo C1 se repite en relación a los campos B1 y B2, que a su vez se repiten con respecto a A1 y A2, C1 aparece descrito como un segmento independiente, descendiente del segmento TWO, un descendiente del segmento ONE.
Ejemplo: Cómo describir campos repetidos paralelos y anidados
La siguiente estructura de datos contiene conjuntos de campos repetidos anidados y paralelos.
A
1 |
A
2 |
B
1 |
B
2 |
C
1 |
C
1 |
C
1 |
B
1 |
B
2 |
C
1 |
C
1 |
C
1 |
C
1 |
D
1 |
D
1 |
E
1 |
E
1 |
E
1 |
E
1 |
Produce la siguiente estructura de datos:
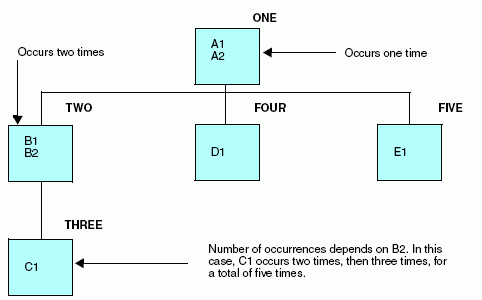
Describa este origen de datos del siguiente modo. Observe que la asignación de atributos PARENT muestra el modo en que se encuentran anidadas las recurrencias.
FILENAME = EXAMPLE3, SUFFIX = FIX,$
SEGNAME = ONE, SEGTYPE=S0,$
FIELDNAME = A1 ,ALIAS= ,ACTUAL = A1 ,USAGE = A1 ,$
FIELDNAME = A2 ,ALIAS= ,ACTUAL = I1 ,USAGE = I1 ,$
SEGNAME = TWO, SEGTYPE=S0, PARENT = ONE, OCCURS = 2 ,$
FIELDNAME = B1 ,ALIAS= ,ACTUAL = A15 ,USAGE = A15 ,$
FIELDNAME = B2 ,ALIAS= ,ACTUAL = I1 ,USAGE = I1 ,$
SEGNAME = THREE, SEGTYPE=S0, PARENT = TWO, OCCURS = B2 ,$
FIELDNAME = C1 ,ALIAS= ,ACTUAL = A25 ,USAGE = A25 ,$
SEGNAME = FOUR, SEGTYPE=S0, PARENT = ONE, OCCURS = A2 ,$
FIELDNAME = D1 ,ALIAS= ,ACTUAL = A15 ,USAGE = A15 ,$
SEGNAME = FIVE, SEGTYPE=S0, PARENT = ONE, OCCURS = VARIABLE,$
FIELDNAME = E1 ,ALIAS= ,ACTUAL = A5 ,USAGE = A5 ,$
Nota:
- Los segmentos ONE, TWO y THREE representan un grupo anidado de segmentos repetidos. Los campos B1 y B2 aparecen un número de veces fijo, así que OCCURS es igual a 2. El campo C1 aparece un número determinado de veces dentro de cada caso de los campos B1 y B2. El número de veces en que aparece C1 viene determinado por el valor del campo B2, que es el contador. En este caso, su valor es de 3 para la primera aparición del segmento TWO y de 4 para la segunda.
- Los segmentos FOUR y FIVE están compuestos por campos que se repiten de forma independiente al segmento principal. No guardan ninguna relación entre sí ni con el segmento TWO, a excepción del segmento principal, y por ello representan un grupo paralelo de segmentos repetidos.
- Al igual que con el segmento THREE, el número de veces en que aparece el segmento FOUR depende del contador de su segmento principal, A2. En este caso, el valor de A2 es de dos.
- El número de veces en que aparece FIVE varía. Esto indica que el resto de los campos del registro (todos los que estén a la derecha del primer caso de E1) se lee como fuesen recurrencias del campo E1. Para garantizar que los datos del registro se interpreten sin ambigüedades, debe haber un segmento definido como OCCURS=VARIABLE al final del registro. En los diagramas de estructuras de datos, éste es el segmento situado a la derecha del todo. Observe que sólo puede haber un segmento definido como OCCURS=VARIABLE por cada tipo de registro.
xCómo usar el atributo POSITION
El atributo POSITION es un atributo opcional utilizado para describir una estructura en que los campos que aparecen en un número establecido de ocasiones, están situados en mitad del registro. El origen de datos se describe como una estructura jerárquica, compuesta por un segmento principal y, al menos, un secundario con campos recurrentes. El segmento principal está compuesto por cualquier campo que sólo aparezca una vez en el registro, además de uno o varios campos alfanuméricos que aparezcan en el lugar en que lo hacen los campos recurrentes. El campo alfanumérico puede ser ficticio y equivaler a la longitud exacta de los campos recurrentes combinados. Por ejemplo, si tiene cuatro casos de un campo de ocho caracteres, la longitud del campo del segmento principal es de 32 caracteres.
Además, puede usar el atributo POSITION para describir nuevamente los campos con SEGTYPE=U. Consulte Cómo redefinir un campo en un origen de datos que no sea FOCUS.
x
Sintaxis: Cómo Especificar la posición de un campo repetido
El atributo POSITION aparece descrito en el segmento secundario. Proporciona el nombre del campo del segmento principal, que especifica la posición inicial y la longitud total de los campos recurrentes. La sintaxis del atributo POSITION es:
POSITION = fieldname
donde:
- fieldname
Es el nombre del campo del segmento principal que define la posición inicial de los camposr recurrentes.
Ejemplo: Cómo especificar la posición de un campo repetido
Examine la siguiente estructura de datos:
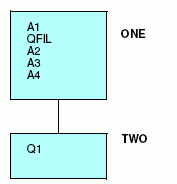
En este ejemplo, el campo Q1 se repite cuatro veces en la mitad del registro. Al describir esta estructura, debe especificar uno o varios campos que ocupen la posición de los cuatro campos Q1 en el registro. A continuación, asigne los campos Q1 mismos al segmento descendiente, recurrente. El atributo POSITION, especificado en el segmento descendiente, proporciona el nombre del campo del segmento principal, que identifica la posición inicial y longitud total de los campos Q.
Emplee el siguiente archivo máster para describir esta estructura:
FILENAME = EXAMPLE3, SUFFIX = FIX,$
SEGNAME = ONE, SEGTYPE=S0,$
FIELDNAME = A1 ,ALIAS= ,USAGE = A14 ,ACTUAL = A14 ,$
FIELDNAME = QFIL ,ALIAS= ,USAGE = A32 ,ACTUAL = A32 ,$
FIELDNAME = A2 ,ALIAS= ,USAGE = I2 ,ACTUAL = I2 ,$
FIELDNAME = A3 ,ALIAS= ,USAGE = A10 ,ACTUAL = A10 ,$
FIELDNAME = A4 ,ALIAS= ,USAGE = A15 ,ACTUAL = A15 ,$
SEGNAME = TWO, SEGTYPE=S0, PARENT = ONE, POSITION = QFIL, OCCURS = 4 ,$
FIELDNAME = Q1 ,ALIAS= ,USAGE = D8 ,ACTUAL = D8 ,$
Esto produce la siguiente estructura:
Si la longitud total de los campos recurrentes es superior a 4095, puede usar un campo de relleno detrás del campo ficticio para compensar la longitud restante. Esto es obligatorio ya que el formato de un campo alfanumérico no puede exceder los 4095 bytes.
Tenga en cuenta que esta estructura sólo funciona con un número fijo de casos del campo repetido. Esto signfica que el atributo OCCURS del segmento descendiente debe ser de tipo OCCURS=n. OCCURS=fieldname y OCCURS=VARIABLE no funcionan.
xCómo especificar el campo ORDER
En un segmento OCCURS, el orden de los datos puede ser importante. Por ejemplo, los valores pueden representar datos mensuales o trimestrales, aunque puede que el propio registro no especifique explícitamente el mes o el trimestre al que se corresponden los datos.
Para asociar un número de secuencia a cada aparición del campo, puede definir un campo contador interno en cualquier campo OCCURS. Se proporciona automáticamente un valor que define el número de secuencia de cada grupo repetido.
x
Sintaxis: Cómo Especificar la secuencia de un campo repetido
Las reglas de sintaxis de los campos ORDER son:
- Debe ser el último campo descrito en un segmento OCCURS.
- El nombre del campo es arbitrario.
- El ALIAS es ORDER.
- USAGE es In, con cualquier opción de modificación aplicable.
- ACTUAL es I4.
Los valores de orden son 1, 2, 3, etc., dentro de cada aparición del segmento. El valor se asigna con anterioridad a cualquier prueba de selección que pueda aceptar o rechazar el registro, haciéndolo válido para cualquier prueba de selección.
Ejemplo: Cómo usar el atributo ORDER en una prueba de selección
La siguiente declaración asigna ACT_MONTH como campo ORDER:
FIELD = ACT_MONTH, ALIAS = ORDER, USAGE = I2MT, ACTUAL = I4, $
La siguiente prueba WHERE obtiene, únicamente, los datos del mes de junio:
SUM AMOUNT...
WHERE ACT_MONTH IS 6
El campo ORDER es un campo virtual de uso interno. No altera la longitud del registro lógico (LRECL en sus siglas inglesas) del origen de datos al que se está accediendo.