En esta sección: |
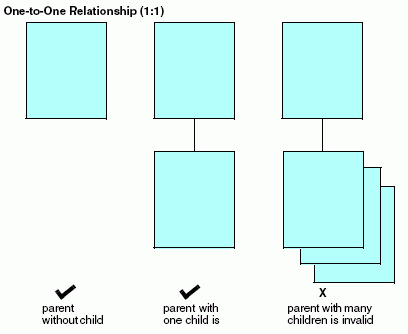
Los campos del segmento tienen una relación de uno a uno entre ellos. Los segmentos también pueden tener este tipo de relación. Cada instancia del segmento principal puede estar relacionada a una instancia del segmento secundario, como se indica en la siguiente imagen. Como la relación es de uno a uno, la instancia principal nunca está relacionada con más de una instancia del secundario. Sin embargo, no todos las instancias principales deben tener una instancia secundaria, coincidente.
El segmento secundario en una relación de uno a uno se denomina único, ya que nunca puede haber más de una instancia secundaria. El siguiente diagrama explica el concepto de relación de uno a uno.
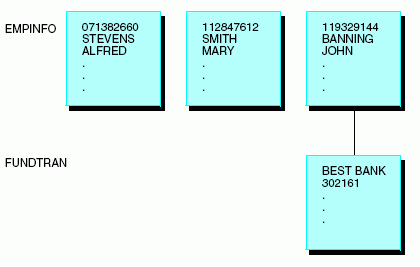
En el origen de datos EMPLOYEE, cada instancia del segmento EMPINFO describe un número de ID de empleado, un nombre, un salario actual y demás información relacionada. Algunos de los empleados se han adscrito al programa de domiciliación de nómina, que deposita sus salarios directamente en sus cuentas bancarias, una vez por semana. Para estos empleados, el origen de datos también incluye el nombre de su banco y el número de cuenta.
Puesto que sólo es necesario un conjunto de información bancaria por cada empleado (cada nómina se deposita en una sola cuenta), existe una relación de uno a uno entre los campos de ID del empleado y los campos de información bancaria. Puesto que la participación en el programa es limitada, sólo hay información bancaria de algunos empleados. La mayoría no necesita estos campos bancarios.
El origen de datos fue diseñado teniendo en cuenta la eficiencia de almacenamiento, así que los campos bancarios están situados en un segmento diferente, llamado FUNDTRAN. Este espacio sólo se usa para información bancaria, creándose una instancia de FUNDTRAN cuando sea necesario. Sin embargo, si los campos se utilizan bancarios en el segmento principal (EMPINFO), el segmento EMPINFO de cada empleado reserva un espacio para estos campos, aunque en la mayoría de los casos estén vacíos. El concepto aparece explicado en el siguiente diagrama.
Al recuperar sus datos, puede especificar un segmento único para asegurar el cumplimiento de una relación de uno a uno.
Cuando recupere datos de un segmento descrito como único, la solicitud trata el segmento como una extensión de su principal. Si el segmento único tiene varias instancias, la solicitud sólo recupera una. Si el segmento único no tiene instancias, la solicitud sustituye los campos no disponibles del segmento por valores predeterminados. Para los campos numéricos se usa el cero (0), un espacio en blanco ( ) para los alfanuméricos y valor no disponible para los campos con atributo MISSING. El atributo MISSING aparece descrito en Cómo describir un campo individual.
Describa esta relación uniendo las tablas del archivo máster y especificando un SEGTYPE de U para la tabla secundaria. Para más información sobre cómo unir las tablas en un archivo máster, consulte la documentación del adaptador de datos correspondiente. Alternativamente, puede unir las tablas emitiendo el comando JOIN, sin la opción ALL (o MULTIPLE), o con la opción UNIQUE, y desactivando el recurso Optimización de SQL con el comando SET OPTIMIZATION.
Especifique esta relación entre dos registros, emitiendo el comando JOIN sin la opción ALL (o MULTIPLE), o con la opción UNIQUE.
Describa esta relación especificando un SEGTYPE de U para el segmento secundario. Alternativamente, puede unir estos segmentos emitiendo el comando JOIN sin la opción ALL (o MULTIPLE), o con la opción UNIQUE, o especificando un join único, en el archivo máster, utilizando un SEGTYPE de KU (join estático) o DKU (join dinámico). Todos estos valores de SEGTYPE aparecen descritos en Cómo describir un origen de datos de FOCUS.
Además, puede describir una relación de uno a uno como una de uno a varios en el archivo máster, o mediante el comando JOIN. Esta técnica aporta mayor flexibilidad, pero no asegura el cumplimiento de la relación de uno a uno a la hora de generar informes o introducir datos, y no usa los recursos de un modo eficiente.
| WebFOCUS |