En esta sección: Referencia: |
Cuando une dos orígenes de datos, puede que algunos registros de uno de los archivos no tengan los registros correspondientes en el otro archivo. Cuando un informe omite registros que no están en ambos archivos, se le llama join interna. Cuando un informe muestra todos los todos los registros coincidentes, además de todos los registros del archivo host, sin los registros de referencia cruzada correspondientes, la join se denomina join externa.
El comando SET ALL determina cómo se implementan todas las joins. Si se emite el comando SET ALL=ON, se tratan todas las joins como joins externas. Con SET ALL=OFF, el predeterminado, se tratan todas las joins se como joins internas.
Cada comando JOIN puede especificar explícitamente qué tipo de join a realizar, invalidando localmente la configuración global. Esta sintaxis está soportada en FOCUS, XFOCUS, Relational, VSAM, IMS y Adabas. Si no especifica el tipo de join en el comando JOIN, la configuración de parámetro ALL determina el tipo de join a realizar.
También puede unir orígenes de datos con una o dos técnicas para determinar cómo armonizar registros de dos orígenes de datos separados. La primera técnica se conoce como un equijoin y la segunda como una join condicional. Cuando deba decidir cuál de las dos técnicas de join utilizar, es importante saber que cuando se da una condición de igualdad entre dos orígenes de datos, es más eficiente utilizar una equijoin en vez de una join condicional.
Puede utilizar una estructura de equijoin cuando combina dos o más orígenes de datos que constan de dos campos, uno en cada origen de datos, con formatos (de caracteres, numéricos o de fecha) y valores en común. Un ejemplo de equijoin puede ser la join de un campo de código de producto en un origen de datos de venta (el archivo host) con un campo de código de producto en un origen de datos de producto (el campo de referencia cruzada). Para más información acerca del uso de equijoin, vaya a Cómo crear un equijoin.
La join condicional usa sintaxis basada en WHERE para especificar joins basadas en criterios WHERE, no sólo en la igualdad entre campos. Además, los campos join de host y de referencia cruzada no tienen por qué tener formatos coincidentes. Supongamos que tiene un origen de datos que lista empleados por su número de identificación (el archivo host) y otro origen de datos que lista los cursos de formación y los empleados que han asistido a esos cursos (archivo de referencia cruzada). Mediante una join condicional, puede unir la identificación de un empleado en el archivo host con la identificación de un empleado en el campo de referencia cruzada para determinar cuáles empleados han tomado cursos de formación en un intervalo de tiempo determinado (la condición WHERE). Para más información, consulte Cómo utilizar una join condicional .
Las joins pueden ser únicas o no únicas. Una estructura de join única o de uno a uno armoniza un valor en el origen de datos host con un valor en el origen de datos de referencia cruzada. Un ejemplo de una estructura de equijoin única es la join de la identificación de un empleado en un origen de datos de empleados con un origen de datos de salario.
Una estructura de join no única o de uno a muchos armoniza un valor en el origen de datos host con múltiples valores en el origen de datos de referencia cruzada. La join de la identificación de un empleado en el origen de datos de empleado de una compañía con la identificación de un empleado en un origen de datos que lista todas las clases de formación ofrecidas por esa compañía arroja una lista de todos los cursos tomados por cada empleado, o bien una combinación de la ocurrencia de cada identificación en el archivo host, con las múltiples ocurrencias de dicha identificación en el archivo de referencia cruzada.
Para más información sobre joins únicos y no únicos, consulte Estructuras unidas únicas y no únicas.
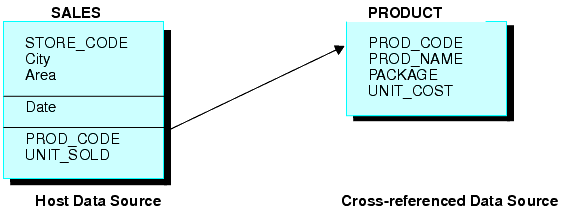
Examine los orígenes de datos SALES y PRODUCT. Cada registro de tienda en SALES podría contener muchas ocurrencias del campo PROD_CODE. Puesto que sería redundante guardar la información relacionada al producto con cada caso del código de producto, se establece un join entre PROD_CODE, en el origen de datos SALES, y PROD_CODE, en el origen de datos PRODUCT. PRODUCT contiene una sola ocurrencia de cada código de producto y la información de producto relacionada, lo que ahorra espacio y facilita mantener la información del producto. La estructura unida, un ejemplo de la equijoin, se explica más abajo:
El uso de orígenes de datos como archivos de host y archivos de referencia cruzada depende de los tipos de orígenes de datos que combine:
SET PASS = pswd1 IN file1, pswd2 IN file2
La información DBA individual se mantiene vigente para cada archivo en el JOIN. Para más detalles acerca del atributo DBAFILE, consulte el manual Cómo describir datos con el lenguaje WebFOCUS.
Cómo: |
En una estructura unida única, un valor en el campo host corresponde a un valor en el campo de referencia cruzada. En una estructura unida no única, un valor en el campo host corresponde a múltiples valores en el campo de referencia cruzada.
El parámetro ALL en el comando JOIN indica que la estructura unida no es única.
El ejemplo siguiente explica una estructura unida única. Dos orígenes de datos FOCUS se combinan: un origen de datos EMPDATA y un origen de datos SALHIST. Ambos orígenes de datos se organizan con PIN y se combinan en un campo PIN en los segmentos raíz de ambos archivos. Cada PIN cuenta con una ocurrencia de segmento en el origen de datos EMPDATA y una ocurrencia de segmento en el origen de datos SALHIST. Para unir ambos orígenes de datos, emita este comando JOIN:
JOIN PIN IN EMPDATA TO PIN IN SALHIST
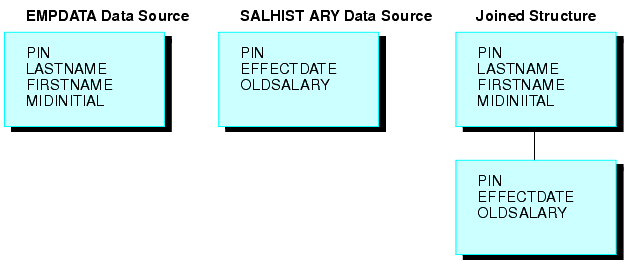
Si un valor de campo en el archivo host apareciera en muchas ocurrencias de segmento en el archivo de referencia cruzada, entonces debe incluir la frase ALL en la sintaxis JOIN. Esta estructura se llama un estructura unida no única.
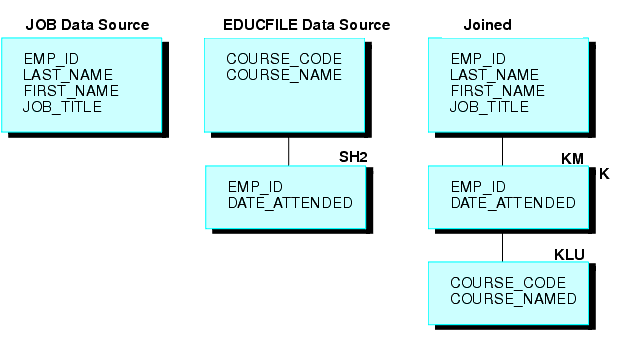
Por ejemplo, digamos que se combinen dos orígenes de datos de FOCUS: el origen de datos JOB y un origen de datos EDUCFILE, con registros de asistencia de empleados a cursos en la oficina. La estructura unida aparece en el diagrama siguiente:
El origen de datos JOB se organiza por empleado, pero el origen de datos EDUCFILE se organiza por curso. Los orígenes de datos se combinan en el campo EMP_ID. Dado que un empleado tiene una posición pero puede asistir a varios cursos, el empleado tiene una ocurrencia de segmento en el origen de datos JOB pero puede tener tantas ocurrencias en el origen de datos EDUCFILE como cursos a los que haya asistido.
Para unir ambos orígenes de datos, emita el siguiente comando JOIN mediante la frase ALL:
JOIN EMP_ID IN JOB TO ALL EMP_ID IN EDUCFILE
Si un segmento superior tiene dos o más segmentos inferiores únicos, todos con múltiples segmentos inferiores propios, el informe puede mostrar un valor no disponible incorrectamente. El resto de los valores inferiores por lo tanto podrán aparecer desalineados en el informe. Estos valores desalineados se denominan valores finales. El parámetro JOINOPT asegura una alineación correcta para su salida al corregir estos valores finales.
SET JOINOPT={NEW|OLD}donde:
Nota: El parámetro JOINOPT también permite establecer joins entre distintos tipos de datos numéricos. Para más información, consulte Cómo unir campos con tipos diferentes de datos numéricos.
Este ejemplo presenta una situación hipotética en la que se usaría el parámetro JOINOPT para corregir los valores retrasados. Los valores retrasados muestran los datos no disponibles de modo que cada valor aparece desalineado por una línea.
Un archivo de host de segmento único (ROUTES) está unido a dos archivos (ORIGIN y DEST), cada uno con dos segmentos. Estos archivos se unen para generar un informe que muestre cada número de tren, junto con la ciudad que corresponde a cada estación.
La solicitud a continuación imprime la ciudad de origen (OR_CITY) y la ciudad de destino (DE_CITY). Fíjese que se generan datos no disponibles, lo que hace que los datos de las estaciones y ciudades correspondientes se queden atrás o queden desalineados por una línea.
TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
La salida es:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL . 202 BOS BOSTON BLT ATLANTA 303 DET DETROIT BOS BALTIMORE 404 CHI CHICAGO DET BOSTON 505 BOS BOSTON STL DETROIT 505 BOS . STL ST. LOUIS
Al emitir SET JOINOPT=NEW le permitirá recuperar segmentos en el orden esperado (de izquierda a derecha y de arriba a abajo), sin valores no disponibles.
SET JOINOPT=NEW TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
El informe correcto tiene 5 líneas en lugar de 6 y los datos de estación y ciudad están alineados correctamente. La salida es:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL ATLANTA 202 BOS BOSTON BLT BALTIMORE 303 DET DETROIT BOS BOSTON 404 CHI CHICAGO DET DETROIT 505 BOS BOSTON STL ST. LOUIS
Referencia: |
Puede unir un origen de datos de FOCUS o de IMS consigo mismo mediante una estructura recursiva. En el tipo más común de estructura recursiva, un segmento principal se combina con un segmento descendiente, de manera que el principal se convierte en el secundario del descendiente. Esta técnica (útil para guardar facturas de materiales, por ejemplo) le permite informar desde orígenes de datos como si tuvieran más niveles de segmentos de lo que en realidad tienen.
Por ejemplo, el origen de datos GENERIC, que aparece más abajo, consta de los segmentos A y B.
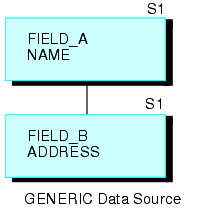
La siguiente solicitud crea una estructura recursiva:
JOIN FIELD_B IN GENERIC TAG G1 TO FIELD_A IN GENERIC TAG G2 AS RECURSIV
Que tiene como resultado la estructura unida (que aparece más abajo).
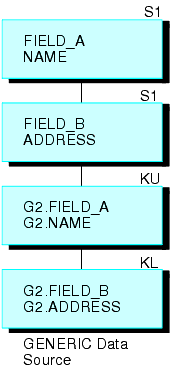
Fíjese que los dos segmentos se repiten al fondo. Para referirse a los campos en los segmentos repetidos (diferentes del archivo con el que desea unir), prefije los nombres de etiqueta con los nombres de campo y sus alias y sepárelos con un punto, o bien adjunte los primeros cuatro caracteres del nombre JOIN a los nombres de campo y alias. En el ejemplo superior, el nombre de JOIN es RECURSIV. Debe referirse a FIELD_B en el fondo del segmento como G2.FIELD_B (o RECUFIELD_B). Para más información, consulte Notas sobre el uso de estructuras unidas recursivas .
Este ejemplo explica cómo utilizar joins recursivas para guardar e informar acerca de una factura de materiales. Suponga que diseña un origen de datos llamado AIRCRAFT que contiene la factura de materiales de una empresa aeronáutica. El origen de datos registra los datos en tres niveles de partes y piezas de aeronaves:
El origen de datos debe registrar cada pieza, su descripción y las partes que la componen. Algunas piezas, como los tornillos y tuercas, abundan en toda la aeronave. Si diseña una estructura de trs segmentos, un segmento para cada nivel de piezas, se repiten las descripciones de las piezas comunes en cada lugar en que se utilicen.
Para reducir tal repetición, diseñe un origen de datos que tenga solamente dos segmentos (que se muestran en el diagrama que sigue). El segmento superior describe cada parte o pieza de la aeronave, sea grande o pequeña. El segmento inferior lista las piezas componentes sin descripciones.
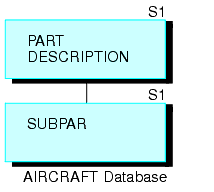
Cada parte o pieza (excepto por las divisiones más grandes) aparece tanto en el segmento superior, en que se describe; como en el inferior, en que se lista como uno de los componentes de una parte o pieza mayor. (Las piezas más pequeñas, como los tornillos y tuercas, aparecen en el segmento superior sin una ocurrencia del un secundario en el segmento inferior). Fíjese que cada parte o pieza se menciona sólo una vez, sin importar con qué frecuencia se use en la aeronave.
Si combina el segmento inferior con el segmento superior, podrá recuperar las descripciones de piezas en el segmento inferior. Las principales divisiones del primer nivel se pueden relacionar también con las piezas más pequeñas del tercer nivel, pasando del primer nivel al segundo y de este al tercero. De esta manera, la estructura se comporta como un origen de datos de tres niveles, aunque en realidad se trata de un origen de tres niveles.
Por ejemplo, CABIN es una división del primer nivel que aparece en el segmento superior. Lista SEATS como un componente en el segmento inferior. SEATS también aparece en el segmento superior. Lista BOLTS como un componente del segmento inferior. Si combina el segmento inferior con el segmento superior, puede pasar de CABIN a SEATS y de SEATS s BOLTS.

Combine el segmento inferior con el segmento superior con este comando JOIN:
JOIN SUBPART IN AIRCRAFT TO PART IN AIRCRAFT AS SUB
Esto crea la siguiente estructura recursiva.
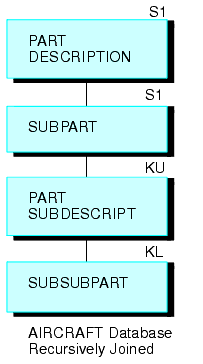
Puede entonces producir un informe en los tres niveles de datos con este comando TABLE (el campo SUBDESCRIPT describe el contenido del campo SUBPART):
TABLE FILE AIRCRAFT PRINT SUBPART BY PART BY SUBPART BY SUBDESCRIPT END
| WebFOCUS |