Cómo calcular tendencias y predecir valores con FORECAST
Puede calcular tendencias en los datos numéricos y predecir valores más allá del intervalo de los que están almacenados en el origen de datos usando la función FORECAST . Se puede utilizar FORECAST en una solicitud de informe o de gráfico.
Los cálculos que realice para identificar tendencias y valores de pronóstico son:
-
Promedio móvil simple (MOVAVE). Calcula una serie de medios aritméticos mediante un número determinado de valores de un campo. Para más detalles, consulte Cómo utilizar un promedio móvil simple.
-
Promedio móvil exponencial. Calcula un promedio ponderado entre el valor del promedio calculado anteriormente y el siguiente punto de datos. Existen tres métodos para utilizar un promedio móvil exponencial:
-
Análisis de regresión lineal (REGRESS). Deriva los coeficientes de la línea recta que más se ajuste a los puntos de datos y emplea esta ecuación lineal para estimar valores. Para ver información detallada, vaya a Notas sobre cómo crear campos virtuales.
A la hora de predecir valores y calcular tendencias, FORECAST continúa realizando los mismos cálculos más allá de los puntos de datos, usando los valores de tendencia generados como nuevos puntos de datos. En la técnica de regresión lineal, la ecuación calculada se utiliza para obtener valores de tendencias y valores pronosticados.
FORECAST realiza los cálculos en base a los datos proporcionados, pero las decisiones sobre su uso y fiabilidad son responsabilidad del usuario. Por tanto, las predicciones de FORECAST no son siempre acertadas. Existen muchos factores que determinan la precisión de un pronóstico.
x
Procesamiento de FORECAST
Para invocar procesamiento FORECAST, incluya FORECAST en un comando RECAP. En este comando, especifique los parámetros necesarios para generar valores estimados, incluyendo el campo que hay que usar para realizar los cálculos, el tipo de cálculo que se va a utilizar y el número de pronósticos que se va a generar. El campo RECAP que contiene el resultado de FORECAST puede ser un campo nuevo (no recursivo) o el mismo campo usado en los cálculos de FORECAST (recursivo):
- En un tipo recursivo de FORECAST, el campo RECAP que contiene los resultados también es el campo usado para generar los cálculos de FORECAST. En este caso, el campo original no queda impreso, incluso si aparecía citado en el comando de visualización, y la columna RECAP contiene los valores de campo originales, seguidos del número de valores pronosticados, especificado en la sintaxis de FORECAST. No aparecen valores de tendencia en el informe. Sin embargo, la columna original se almacena en un archivo de salida a menos que establezca HOLDLIST en PRINTONLY.
- Si es no recursivo el FORECAST, un nuevo campo contiene los resultados de los cálculos del FORECAST. El nuevo campo aparece en el informe junto con el campo original cuando se menciona en el comando de visualización. El nuevo campo contiene valores de tendencia y de pronóstico cuando así se haya especificado.
FORECAST actúa sobre el último campo ACROSS de la solicitud. Si la solicitud no contiene ningún campo ACROSS , actúa sobre el último campo BY. Los cálculos de FORECAST empiezan de nuevo cuando cambia el valor del campo de clasificación de más alto nivel. En una solicitud con múltiples comandos de visualización, FORECAST actúa sobre el último campo ACROSS (o si no hay ningún campo ACROSS, el último campo By) del último comando de visualización.
Cuando se usa un campo ACROSS con FORECAST, el comando de visualización debe ser SUM o COUNT.
Nota: Aunque pase parámetros a FORECAST mediante una lista de argumentos entre paréntesis, FORECAST no es una función. Puede coexistir con una función del mismo nombre, siempre y cuando la función no esté especificada en un comando RECAP.
x
Sintaxis: Cómo Calcular tendencias y pronosticar valores
Cálculo MOVAVE
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'MOVAVE',npoint1)sendstyle
Cálculo EXPAVE
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'EXPAVE',npoint1);
Cálculo DOUBLEXP
ON sortfield RECAP fld1[/fmt] = FORECAST(infield,
interval, npredict, 'DOUBLEXP',npoint1, npoint2);
Cálculo SEASONAL
ON sortfield RECAP fld1[/fmt] = FORECAST(infield,
interval, npredict, 'SEASONAL', nperiod, npoint1, npoint2, npoint3);
Cálculo REGRESS
ON sortfield RECAP result_field[/fmt] = FORECAST(infield, interval,
npredict, 'REGRESS');
donde:
- sortfield
- Es el último campo ACROSS en la solicitud. Este campo debe estar en formato numérico o de fecha. Si la solicitud no contiene un campo ACROSS, FORECAST funciona en el último campo BY.
- result_field
- Es el campo que contiene el resultado de FORECAST. Puede ser un campo nuevo, o el mismo que infield. Este debe ser un campo numérico; ya sea un campo real, un campo virtual o un campo calculado.
Nota: La palabra FORECAST y los paréntesis iniciales deben estar en la misma línea que la sintaxis sortfield=.
- fmt
- Es el formato de salida para result_field. El formato predeterminado es D12.2. Si previamente se había reformateado result_field con un comando
DEFINE o COMPUTE, se respeta el formato especificado en el comando RECAP.
- infield
- Es cualquier campo numérico. Puede ser el mismo campo que result_field o puede ser un campo diferente. No puede ser un campo de fecha y hora o un campo numérico con opciones de visualización de fecha.
- interval
- Es el incremento para sumar a cada valor sortfield (después del último punto de datos) para crear el próximo valor. Debe ser un número entero positivo. Para clasificar en orden descendente, utilice la frase BY HIGHEST. El resultado de sumar este número a los valores de sortfield se convierte al mismo formato que sortfield.
Para campos de fecha, el componente mínimo en el formato determina cómo se interpreta el número. Por ejemplo, si el formato es YMD, MDY o DMY, un valor de intervalo de 2 se interpreta como dos días. Si el formato es YM, el valor de intervalo de 2 se interpreta como dos meses.
- npredict
- Es el número de predicciones que hay que calcular para FORECAST. Debe ser un número entero mayor o igual a cero. Cero indica que no desea obtener pronósticos y sólo lo admite FORECAST no recursivo. Para el método SEASONAL, npredict es el número de periodos a calcular. El número de puntos generados es:
nperiod * npredict
- nperiod
- En el método SEASONAL, es
un número entero positivo que especifica el número de puntos de datos en un periodo.
- npoint1
- Es el número de valores que hay que promediar para el método MOVAVE. En EXPAVE, DOUBLEXP y SEASONAL, este número se utiliza para calcular los pesos de cada componente en el promedio. Este valor debe ser un número entero positivo. El peso, k, se calcula mediante la siguiente fórmula:
k=2/(1+npoint1)
- npoint2
- En DOUBLEXP y SEASONAL, este número entero positivo se utiliza para calcular los pesos de cada término de la tendencia. El peso, g, se calcula mediante la siguiente fórmula:
g=2/(1+npoint2)
- npoint3
- En SEASONAL, este número entero positivo se utiliza para calcular los pesos de cada término del ajuste estacional. El peso, p, se calcula mediante la siguiente fórmula:
p=2/(1+npoint3)
x
Referencia: Notas de uso FORECAST
- El campo de clasificación usado para FORECAST debe estar en formato numérico o de fecha.
- Cuando utilice los métodos de promedio móvil simple y de promedio móvil exponencial, los valores de datos deben espaciarse de manera uniforme para obtener resultados adecuados.
- Cuando se usa un comando RECAP con FORECAST, el comando sólo puede contener la sintaxis FORECAST. FORECAST no reconoce ninguna sintaxis después del punto y coma (;) final. Para especificar opciones como AS o IN:
- En solicitudes no recursivas FORECAST, emplee un comando COMPUTE vacío antes de RECAP.
- En solicitudes FORECAST recursivas FORECAST, indique las opciones en la primera referencia al campo en la solicitud del informe.
- No está soportado el uso de la notación de columna en solicitudes que incluyen FORECAST. El proceso de generar los valores de FORECAST crea columnas adicionales que no se imprimen en la salida del informe. El número y colocación de estas columnas adicionales varía dependiendo de la solicitud específica.
- La solicitud puede contener hasta siete no FORECAST
comando no RECAP y siete comandos FORECAST RECAP.
- El lado izquierdo de un comando RECAP usado para FORECAST admite el atributo CURR para crear un campo denominado en moneda.
- Los atributos REGRESS recursivos y no recursivos no están soportados en la misma solicitud cuando el comando de visualización es SUM, ADD o WRITE.
- Los valores no disponibles no están soportados con REGRESS.
- Si emplea el parámetro ESTRECORDS para activar la clasificación externa y así obtener una estimación más precisa del espacio de trabajo de clasificación necesario, tenga en cuenta que el uso de FORECAST con predicciones genera registros adicionales en la salida.
- En los informes con estilo, puede asignar atributos específicos a los valores pronosticados por FORECAST con el atributo de hoja de estilos WHEN=FORECAST. Por ejemplo, para que los valores pronosticados aparezcan en color rojo, utilice la siguiente sintaxis en la solicitud TABLE:
ON TABLE SET STYLE *TYPE=DATA,COLUMN=MYFORECASTSORTFIELD,WHEN=FORECAST,COLOR=RED,
$ENDSTYLE
x
Referencia:
Límites de FORECAST
No se admiten las siguientes con un comando
RECAP que utilice FORECAST:
- El comando BY TOTAL.
- Las frases MORE, MATCH, FOR y OVER.
- No se admiten SUMMARIZE y RECOMPUTE para el mismo campo de clasificación que se use para FORECAST.
- atributo MISSING.
xCómo utilizar un promedio móvil simple
Un promedio móvil simple es una serie de medios aritméticos calculados con un número de valores de un campo especificado. Cada nueva media en la serie se calcula omitiendo el primer valor utilizado en el cálculo anterior y sumando el próximo valor de datos al cálculo.
Los promedios móviles simples se usan a veces para analizar las tendencias que con el tiempo desarrollan los precios de las acciones. En esta situación, se calcula el promedio usando un número específico de periodos de precios de acciones. Una desventaja de este indicador es que, dado que omite los valores más antiguos del cálculo en la medida que avanza, pierde su memoria con el tiempo. Además, los valores medios se distorsionan con altos y bajos extremos, toda vez que este método les da el mismo peso a cada punto.
Los valores pronosticados más allá del rango de los valores de datos se calculan usando un promedio móvil que maneja los valores de tendencias calculados como si fueran nuevos puntos de datos.
El primer promedio móvil completo ocurre en el nº punto de datos porque el cálculo necesita n valores. Esto se conoce como el retardo. Los valores del promedio móvil para las filas finales se calculan como sigue: el primer valor en la columna del promedio móvil es igual al primer valor de datos, el segundo valor en la columna es el promedio de los dos valores de datos, y así sucesivamente hasta la nª fila, momento en el cual ya habrá suficientes valores para calcular el promedio móvil con el número de valores especificado.
Ejemplo: Cómo calcular una nueva columna de promedio móvil simple
Esta solicitud define un valor de número entero llamado PERIOD que se usa como una variable independiente para el promedio móvil. Pronostica tres periodos de valores más allá del rango de datos recuperados.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP MOVAVE/D10.1= FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La salida es:
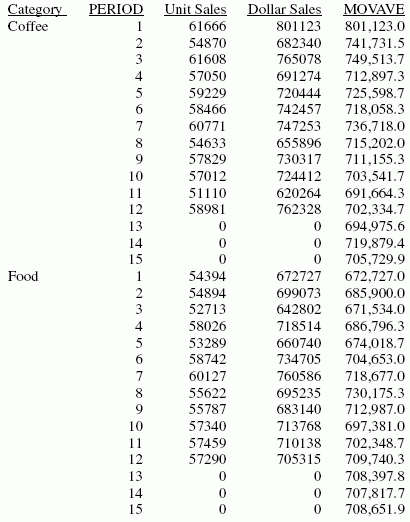
En el informe, el número de valores que hay que utilizar en el promedio es 3 y no hay valores de UNITS o DOLLARS para los valores de PERIOD generados.
Cada promedio (valor MOVAVE) se calcula con valores DOLLARS allí donde existen. El cálculo del promedio móvil comienza del siguiente modo:
- El primer valor MOVAVE (801,123.0) es igual al primer valor DOLLARS.
- El segundo valor MOVAVE (741,731.5) es la media de los valores DOLLARS uno y dos: (801,123 + 682,340) /2.
- El tercer valor MOVAVE (749,513.7) es la media de los valores DOLLARS uno a tres: (801,123 + 682,340 + 765,078) / 3.
- El cuarto valor MOVAVE (712,897.3) es la media de los valores DOLLARS dos a cuatro: (682,340 + 765,078 + 691,274) /3.
En los valores pronosticados más allá de los valores provistos, se usan los valores MOVAVE calculados como nuevos puntos de datos para continuar el promedio móvil. Los valores MOVAVE (empezando con 694,975.6 para el periodo 13) se calculan a partir de los valores MOVAVE anteriores como nuevos puntos de datos. Por ejemplo, el primer valor pronosticado (694,975.6) es el promedio de los puntos de datos de los periodos 11 y 12 (620,264 y762,328) y el promedio móvil para el periodo 12 (702,334.7). El cálculo es: 694,975 = (620,264 + 762,328 + 702,334.7)/3.
Ejemplo: Cómo utilizar un campo existente como una columna de promedio móvil simple
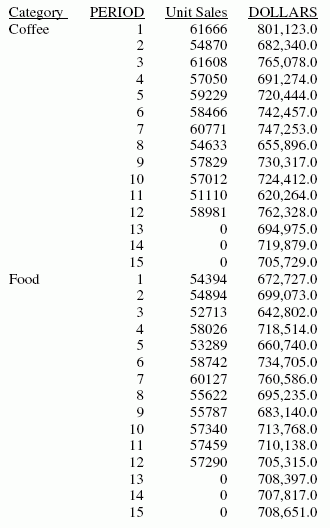
Esta solicitud define un valor de número entero llamado PERIOD que se usa como una variable independiente para el promedio móvil. Pronostica tres periodos de valores más allá del rango de datos recuperados. Usa el mismo nombre para el campo RECAP y como primer argumento de la lista de parámetro FORECAST. Los valores de tendencia no se muestran en el informe. A los valores de datos reales para DOLLARS siguen los valores pronosticados en la columna de informe.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP DOLLARS/D10.1 = FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La salida es:
xCómo utilizar suavización con un solo exponente
El método de una sola columna exponencial suavizada calcula un promedio que le permite elegir pesos que aplicar a valores nuevos y viejos.
La siguiente fórmula determina el peso dado al valor más nuevo.
k = 2/(1+n)
donde:
- k
- Es el valor más nuevo.
- n
- Es un número entero mayor que uno. Cada n mayor aumenta el peso asignado a las notaciones anteriores (o datos) comparado a los posteriores.
El próximo cálculo del valor del promedio móvil exponencial (EMA) proviene de la fórmula siguiente:
EMA = (EMA * (1-k)) + (datavalue * k)
Eso significa que el valor más actual del origen de datos se multiplica por el factor k y el promedio móvil actual se multiplica por el factor (1-k). Estas cantidades se suman para generar el nuevo EMA.
Nota: Cuando se han agotado los valores de datos, se utiliza el último valor de datos en el grupo de clasificación como el próximo valor de datos.
Ejemplo: Cómo calcular una sola columna exponencial suavizada
Lo que sigue define un valor de número entero llamado PERIOD para utilizarlo como la variable independiente del promedio móvil. Pronostica tres periodos de valores más allá del rango de datos recuperados.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY NE 'Gifts'
ON PERIOD RECAP EXPAVE/D10.1= FORECAST(DOLLARS,1,3,'EXPAVE',3);
END
La salida es:
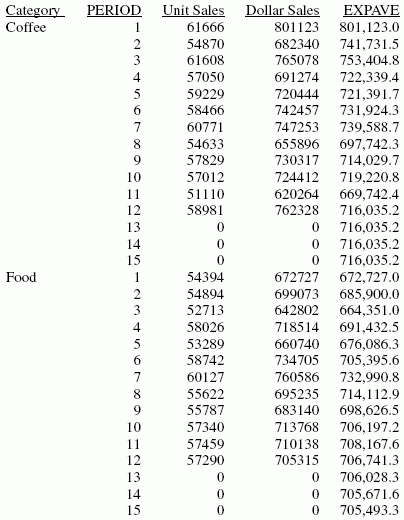
En el informe, los tres valores pronosticados de EXPAVE se calculan en cada valor de CATEGORY. Para valores que estén fuera del rango de datos, los nuevos valores PERIOD se generan añadiendo el valor interno (1) al valor anterior de PERIOD.
Cada promedio (valor EXPAVE) se calcula con valores DOLLARS, cuando existan. El cálculo del promedio móvil comienza del siguiente modo:
- El primer valor EXPAVE (801,123.0) es el mismo que El primer valor DOLLARS.
- El segundo valor EXPAVE (741,731.5) se calcula del siguiente modo. Fíjese que como resultado del redondeo y el número de lugares decimales usados, el valor producido en este cálculo de visualización varía ligeramente con respecto al que se muestra en la salida de informe:
n=3 (number used to calculate weights)
k = 2/(1+n) = 2/4 = 0.5
EXPAVE = (EXPAVE*(1-k))+(new-DOLLARS*k) = (801123*0.5) + (682340*0.50) = 400561.5 + 341170 = 741731.5
- El tercer valor EXPAVE (753,404.8) se calcula como sigue:
EXPAVE = (EXPAVE*(1-k))+(new-DOLLARS*k) = (741731.5*0.5)+(765078*0.50) = 370865.75 + 382539 = 753404.75
Para los valores pronosticados más allá de los provistos, el último valor EXPAVE se utiliza como el nuevo punto de datos en el cálculo exponencial suavizado. Los valores EXPAVE pronosticados (empezando por 706,741.6) se calculan con el promedio anterior y el nuevo punto de datos. Dado que el promedio anterior también se utiliza como nuevo punto de datos, los valores pronosticados son siempre iguales al último valor de la tendencia. Por ejemplo, el promedio anterior para el periodo 13 es 706,741.6, lo cual se usa también como el próximo punto de datos. Por lo tanto, el promedio se calcula de la manera siguiente: (706,741.6 * 0.5) + (706,741.6 * 0.5) = 706,741.6
EXPAVE = (EXPAVE * (1-k)) + (new-DOLLARS * k) = (706741.6*0.5) +
(706741.6*0.50) = 353370.8 + 353370.8 = 706741.6
xCómo utilizar suavización con doble exponente
El suavizado exponencial doble produce un promedio móvil exponencial que toma en cuenta la tendencia de los datos para aumentarlos o disminuirlos con el paso del tiempo sin que se repitan. Esto se logra usando dos ecuaciones con dos constantes.
Ambas ecuaciones se resuelven para producir el promedio suavizado. El primer promedio suavizado se establece al primer valor de datos. El primer componente de tendencia se establece en cero. Para elegir las dos constantes, los mejores resultados se suelen obtener minimizando el error de media cuadrado (MSE) entre los valores de datos y los promedios calculados. Podría necesitar técnicas de optimización no lineal para hallar las constantes óptimas.
La ecuación utilizada para pronosticar más allá de los puntos de datos con suavizado de doble exponente es
forecast(t+m) = DOUBLEXP(t) + m * b(t)
donde:
- m
- Es el número de periodos de tiempo que quedan para el pronóstico.
Ejemplo: Cómo calcular una columna suavizada con doble exponente
Lo que sigue define un valor de número entero llamado PERIOD para utilizarlo como la variable independiente del promedio móvil. El método de suavizado exponencial doble pronostica la tendencia de los puntos de datos mejor que el método de suavizado único:
SET HISTOGRAM = OFF
TABLE FILE CENTSTMT
SUM ACTUAL_YTD
BY PERIOD
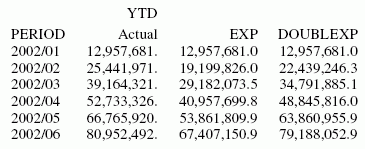
ON PERIOD RECAP EXP/D15.1 = FORECAST(ACTUAL_YTD,1,0,'EXPAVE',3);
ON PERIOD RECAP DOUBLEXP/D15.1 = FORECAST(ACTUAL_YTD,1,0,
'DOUBLEXP',3,3);
WHERE GL_ACCOUNT LIKE '3%%%'
ENDLa salida es:
xCómo utilizar suavización con triple exponente
El suavizado exponencial triple produce un promedio móvil exponencial que toma en cuenta la tendencia de datos que se repite en intervalos con el paso del tiempo. Por ejemplo, los datos de venta que aumentan y en los que el 25% de las ventas ocurre durante diciembre contienen tanto tendencias como estacionalidad. La toma en cuenta tanto la tendencia como la estacionalidad mediante el uso de tres ecuaciones con tres constantes.
Para realizar el suavizado exponencial triple debe conocer el número de puntos de datos en cada periodo de tiempo (designado como L en las siguientes ecuaciones). Se calcula el índice estacional para que represente la estacionalidad. Los datos se dividen por el índice de la estación anterior y a continuación, se utilizan en el cálculo del promedio suavizado.
- La primera ecuación representa el periodo de tiempo actual y es un promedio ponderado del valor de datos actual dividido entre el factor estacional y el promedio anterior ajustado a la tendencia del periodo anterior. La constante ponderada es k:
SEASONAL(t) = k * (datavalue(t)/I(t-L)) + (1-k) * (SEASONAL(t-1) + b(t-1))
- La segunda ecuación es el valor de tendencia calculado y es un promedio ponderado de la diferencia entre el promedio actual y la tendencia para el periodo de tiempo anterior. b(t) representa la tendencia media. La constante ponderada es g:
b(t) = g * (SEASONAL(t)-SEASONAL(t-1)) + (1-g) * (b(t-1))
- La tercera ecuación es el índice estacional ponderado y es un promedio ponderado del valor de datos actual dividido entre el promedio actual y el índice estacional de la estación anterior. I(t) representa el coeficiente temporal medio. La constante ponderada es p:
I(t) = p * (datavalue(t)/SEASONAL(t)) + (1 - p) * I(t-L)
Estas ecuaciones se resuelven para producir el promedio suavizado de triple exponente. El primer promedio suavizado se establece al primer valor de datos. Los valores iniciales para los valores estacionales se calculan a partir del número máximo de periodos de datos completos en el origen de datos, en tanto que la tendencia inicial se calcula a partir de dos periodos de datos. Estos valores se calculan siguiendo los siguientes pasos:
- El factor inicial de la tendencia se calcula con la siguiente fórmula:
b(0) = (1/L) ((y(L+1)-y(1))/L + (y(L+2)-y(2))/L + ... + (y(2L) -
y(L))/L )
- El cálculo del factor de estacionalidad inicial se hace a partir del promedio de valores de datos en cada periodo, A(j) (1<=j<=N):
A(j) = ( y((j-1)L+1) + y((j-1)L+2) + ... + y(jL) ) / L
- Luego se aporta el factor de periodicidad inicial mediante la fórmula que sigue, donde N es el número de periodos completos disponibles en los datos, L es el número de puntos por periodo y n es un punto en el periodo (1<= n <= L):
I(n) = ( y(n)/A(1) + y(L+n)/A(2) + ... + y((N-1)L+n)/A(N) ) / N
Se deben escoger cuidadosamente las tres constantes. Los mejores resultados se suelen obtener eligiendo las constantes para minimizar el error de media cuadrado (MSE) entre los valores de datos y los promedios calculados. Cambiar los valores de npoint1 y npoint2 afecta los resultados y puede que haya algunos valores que generen una mejor aproximación. Para buscar una mejor aproximación, tal vez quiera buscar valores que minimicen el MSE.
La ecuación utilizada para pronosticar más allá del último punto de datos con suavizado exponencial triple es:
forecast(t+m) = (SEASONAL(t) + m * b(t)) / I(t-L+MOD(m/L))
donde:
- m
- Es el número de periodos de tiempo que quedan para el pronóstico.
Ejemplo: Cómo calcular una columna suavizada con triple exponente
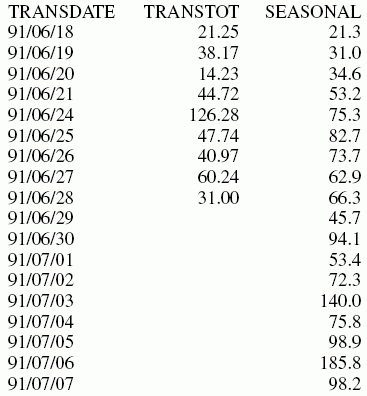
Lo que sigue contiene datos con estacionalidad pero sin tendencia. Por lo tanto, npoint se establece en un número elevado (1000) para que el factor de tendencia resulte insignificante en el cálculo:
SET HISTOGRAM = OFF
TABLE FILE VIDEOTRK
SUM TRANSTOT
BY TRANSDATE
ON TRANSDATE RECAP SEASONAL/D10.1 = FORECAST(TRANSTOT,1,3,'SEASONAL',
3,3,1000,1);
WHERE TRANSDATE NE '19910617'
END
En la salida, npredict es 3. De allí que se generen tres periodos (nueve puntos, nperiod* npredict).
xCómo utilizar una ecuación de regresión lineal
La ecuación de regresión lineal estima valores al asumir que la variable dependiente (los nuevos valores calculados) y la variable independiente (los valores del campo de clasificación) están relacionados por una función que representa una línea recta:
y = mx + b
donde:
- y
- Es la variable dependiente.
- x
- Es la variable independiente.
- m
- Es la curva de la línea.
- b
- Es el punto de intercepción del eje Y.
REGRESS utiliza la técnica de mínimos cuadrados ordinarios para calcular valores de m y b que reducen la suma de las diferencias cuadradas entre los datos y la línea resultante.
Las siguientes fórmulas muestran cómo se calculan m y b.
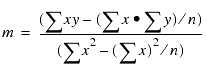
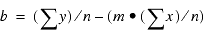
donde:
- n
- Es el número de puntos de datos.
- y
- Es los valores de los datos (variables dependientes).
- x
- Es los valores de campos de clasificación (variables independientes).
Al igual que los valores pronosticados, los valores de tendencia se calculan mediante una ecuación de línea de regresión.
Ejemplo: Cómo calcular un nuevo campo de regresión lineal
TABLE FILE CAR
PRINT MPG
BY DEALER_COST
WHERE MPG NE 0.0
ON DEALER_COST RECAP FORMPG=FORECAST(MPG,1000,3,'REGRESS');
END
La salida es:
DEALER_COST MPG FORMPG
2,886 27 25.51
4,292 25 23.65
4,631 21 23.20
4,915 21 22.82
5,063 23 22.63
5,660 21 21.83
21 21.83
5,800 24 21.65
6,000 24 21.38
7,427 16 19.49
8,300 18 18.33
8,400 18 18.20
10,000 18 16.08
11,000 18 14.75
11,194 9 14.50
14,940 11 9.53
15,940 0 8.21
16,940 0 6.88
17,940 0 5.55Nota:
- Se calculan tres valores pronosticados de FORMPG. Para los valores que estén fuera del rango de datos, los nuevos valores de DEALER_COST se generan añadiendo el valor de intervalo (1,000) al valor anterior de DEALER_COST.
- No existen valores MPG para los valores de DEALER_COST generados.
- Cada valor FORMPG se calcula con una regresión lineal, calculada con todos los valores de datos reales correspondientes a MPG.
DEALER_COST es la variable independiente (x) y MPG es la variable dependiente (y). La ecuación se utiliza para calcular la tendencia MPGFORECAST y los datos pronosticados.
En este caso, la ecuación es aproximadamente como se muestra a continuación:
FORMPG = (-0.001323 * DEALER_COST) + 29.32
Los valores pronosticados son (a causa del redondeo, los valores no son exactamente como los ha calculado FORECAST, pero muestran el proceso de cálculo).
DEALER_COST | Cálculo | FORMPG |
|---|
15,940 | (-0.001323 * 15,940) + 29.32 | 8.23 |
16,940 | (-0.001323 * 16,940) + 29.32 | 6.91 |
17,940 | (-0.001323 * 17,940) + 29.32 | 5.59 |
xTécnicas de informes FORECAST
Puede utilizar FORECAST varias veces en una solicitud. Ahora bien, todas las solicitudes de FORECAST deben especificar el mismo campo de clasificación, intervalo y número de predicciones. Lo único que puede cambiar son el campo RECAP, el método, el campo usado para calcular los valores FORECAST y el número de puntos para el promedio. Si cambia cualquiera de los otros parámetros, se ignoran los nuevos.
Si desea mover una columna de FORECAST en la salida del informe, utilice un comando COMPUTE vacío para el campo FORECAST como un marcador de posición. El tipo de datos (I, F, P, D) debe ser el mismo en el comando COMPUTE y el comando RECAP.
Para facilitar la interpretación de la salida de informe, cree un campo que indique si el valor de FORECAST en cada fila es un valor pronosticado. Para lograr esto, defina un campo virtual cuyo valor sea una constante que no sea cero. Las filas en la salida de informe que representen registros reales en el origen de datos aparecerán con esta constante. En las filas que representen valores pronosticados aparecerá cero. También puede propagar este campo a un archivo HOLD.
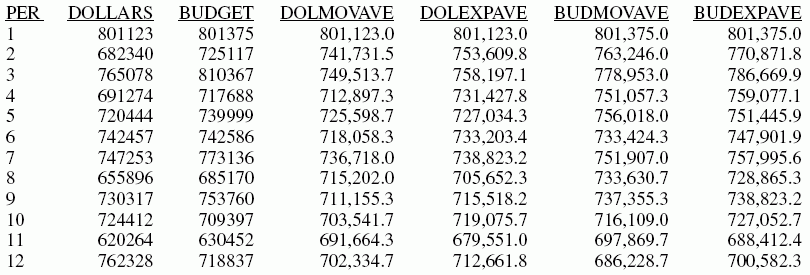
Ejemplo: Cómo generar varias columnas FORECAST en una solicitud
Este ejemplo calcula los promedios móviles y exponenciales para los campos DOLLARS y BUDDOLLARS en el origen de datos GGSALES. El campo de clasificación, el intervalo y el número de pronósticos son iguales para todos los cálculos.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM DOLLARS AS 'DOLLARS' BUDDOLLARS AS 'BUDGET'
BY CATEGORY NOPRINT BY PERIOD AS 'PER'
WHERE SYEAR EQ 97 AND CATEGORY EQ 'Coffee'
ON PERIOD RECAP DOLMOVAVE/D10.1= FORECAST(DOLLARS,1,0,'MOVAVE',3);
ON PERIOD RECAP DOLEXPAVE/D10.1= FORECAST(DOLLARS,1,0,'EXPAVE',4);
ON PERIOD RECAP BUDMOVAVE/D10.1 = FORECAST(BUDDOLLARS,1,0,'MOVAVE',3);
ON PERIOD RECAP BUDEXPAVE/D10.1 = FORECAST(BUDDOLLARS,1,0,'EXPAVE',4);
END
La salida se muestra en la siguiente imagen.
Ejemplo: Cómo mover la columna FORECAST (Pronóstico )
El ejemplo que aparece a continuación coloca el campo DOLLARS después del campo MOVAVE usando un comando COMPUTE vacío como marcador de posición para el campo MOVAVE. Los comandos COMPUTE y RECAP especifican formatos para MOVAVE (del mismo tipo de datos), pero el formato del comando RECAP toma precedencia.
DEFINE FILE GGSALES
SDATE/YYM = DATE;
SYEAR/Y = SDATE;
SMONTH/M = SDATE;
PERIOD/I2 = SMONTH;
END
TABLE FILE GGSALES
SUM UNITS
COMPUTE MOVAVE/D10.2 = ;
DOLLARS
BY CATEGORY BY PERIOD
WHERE SYEAR EQ 97 AND CATEGORY EQ 'Coffee'
ON PERIOD RECAP MOVAVE/D10.1= FORECAST(DOLLARS,1,3,'MOVAVE',3);
END
La salida se muestra en la siguiente imagen.
Category PERIOD Unit
Sales MOVAVE Dollar
SalesCoffee 1 61666 801,123.0 801123
2 54870 741,731.5 682340
3 61608 749,513.7 765078
4 57050 712,897.3 691274
5 59229 725,598.7 720444
6 58466 718,058.3 742457
7 60771 736,718.0 747253
8 54633 715,202.0 655896
9 57829 711,155.3 730317
10 57012 703,541.7 724412
11 51110 691,664.3 620264
12 58981 702,334.7 762328
13 0 694,975.6 0
14 0 719,879.4 0
15 0 705,729.9 0
Ejemplo: Cómo distinguir filas de datos de filas pronosticadas
En el ejemplo que aparece a continuación, el campo virtual DATA_ROW tiene el valor 1 para cada fila en el origen de datos. Para las filas pronosticadas tiene un valor de cero. El campo PREDICT se calcula como YES para filas pronosticadas y como NO para filas que contengan datos.
DEFINE FILE CAR
DATA_ROW/I1 = 1;
END
TABLE FILE CAR
PRINT DATA_ROW
COMPUTE PREDICT/A3 = IF DATA_ROW EQ 1 THEN 'NO' ELSE 'YES' ;
MPG
BY DEALER_COST
WHERE MPG GE 20
ON DEALER_COST RECAP FORMPG/D12.2=FORECAST(MPG,1000,3,'REGRESS');
ON DEALER_COST RECAP MPG =FORECAST(MPG,1000,3,'REGRESS');
END
La salida es:
DEALER_COST DATA_ROW PREDICT MPG FORMPG
2,886 1 NO 27.00 25.65
4,292 1 NO 25.00 23.91
4,631 1 NO 21.00 23.49
4,915 1 NO 21.00 23.14
5,063 1 NO 23.00 22.95
5,660 1 NO 21.00 22.21
1 NO 21.00 22.21
5,800 1 NO 24.20 22.04
6,000 1 NO 24.20 21.79
7,000 0 YES 20.56 20.56
8,000 0 YES 19.32 19.32
9,000 0 YES 18.08 18.08