Cómo manipular campos de visualización con operadores de prefijos
Puede utilizar operadores de prefijos para realizar cálculos directamente sobre los valores de los campos.
Nota: A menos que cambie una columna o un título ACROSS con una frase AS, el operador de prefijo se añade al título automáticamente. Sin la presencia de una frase AS, el título de columna se contruye mediante el operador de prefijo y el nombre de campo o el atributo TITLE, en el archivo máster (si lo hay):
- Si no existe un atributo TITLE, se emplea el nombre de campo.
- Si el archivo máster presenta un atributo TITLE, el uso del campo de nombre o del atributo TITLE depende del valor del parámetro TITLES:
- Si SET TITLES = ON, se usa el atributo TITLE.
- Si SET TITLES = OFF o NOPREFIX, se usa el nombre de campo.
Para obtener una lista de operadores de prefijo y sus funciones, vaya a Funciones que puede realizar con operadores de prefijos.
xPrincipios básicos de operadores de prefijo
Este tema describe la sintaxis y notas básicas de uso de los operadores de prefijo.
x
Sintaxis: Cómo Utilizar operadores de prefijo
Cada operador de prefijo se aplica a un solo campo y afecta solamente a ese campo.
{SUM|COUNT} prefix.fieldname AS 'coltitle'
{PRINT|COMPUTE} RNK.byfielddonde:
- prefix
- Es cualquier operador de prefijos.
- fieldname
- Es el nombre del campo que se mostrará en el informe.
- 'coltitle'
- Es el título de columna de la columna del informe, entre comillas simples.
- byfield
- Es el nombre de un campo de clasificación vertical cuyo rango se va establecer en el informe.
x
Referencia: Notas sobre el uso de operadores de prefijo
- Puesto que PRINT y LIST muestran valores de campo individuales, no un valor agregado, no se utilizan con operadores de prefijos, excepto TOT.
- Para clasificar los resultados de un comando de prefijo, utilice la frase BY TOTAL para agregar y clasificar columnas numéricas simultáneamente. Para obtener información detallada, consulte Cómo clasificar informes tabulares.
- La frase WITHIN es muy útil cuando se usan prefijos.
- Puede utilizar los resultados de operadores de prefijos en comandos COMPUTE.
- Con la excepción de CNT. y PCT.CNT., los valores resultantes tienen el mismo formato que el campo frente al que se realizó la operación de prefijo.
- Los campos de texto sólo pueden usarse con los operadores de prefijos FST., LST. y CNT. operadores de prefijo.
x
Referencia: Funciones que puede realizar con operadores de prefijos
La tabla que sigue lista operadores de prefijo y describe la función de cada uno.
|
Prefijo
|
Función
|
|---|
ASQ. |
Calcula la suma media de cuadrados de la desviación estándar en análisis estadístico.
|
AVE. |
Calcula el valor medio del campo.
|
CNT. |
Cuenta el número de casos del campo. El tipo de datos del resultado siempre es un número entero.
|
CNT.DST. |
Cuenta el número de valores distintivos dentro de un campo.
|
CT. |
Produce un total acumulado del campo especificado. Este operador se aplica solamente cuando se usa en subpies. Para obtener información detallada, consulte Cómo usar encabezados, pies, títulos y etiquetas.
|
DST. |
Determina el número total de valores distintivos en un solo pase de un origen de datos.
|
FST. |
Genera la primera ocurrencia física del campo. Se puede usar con campos numéricos o de texto.
|
LST. |
Genera el último caso físico del campo. Se puede usar con campos numéricos o de texto.
|
MAX. |
Genera el valor máximo del campo.
|
MDE. |
Calcula el modo de los valores de los campos.
|
MDN. |
Calcula la mediana de los valores de los campos.
|
MIN. |
Genera el valor mínimo del campo.
|
PCT. |
Calcula el porcentaje de un campo en base a los valores totales de dicho campo. El operador PCT se puede usar tanto con campos de detalle como de sumario.
|
PCT.CNT. |
Calcula el porcentaje de un campo en base al número de casos hallados. El formato del resultado es siempre F6.2 y no se puede reformatear.
|
RNK. |
Cataloga los casos de un campo de clasificación BY en la solicitud. Se puede usar en comandos PRINT o COMPUTE y en pruebas IF o WHERE TOTAL.
|
RPCT. |
Calcula el porcentaje de un campo en base a los valores totales del campo en una fila.
|
ST. |
Genera un valor subtotal del campo especificado en el salto de clasificación del informe. Este operador se aplica solamente cuando se usa en subpies. Para obtener información detallada, consulte Cómo usar encabezados, pies, títulos y etiquetas.
|
SUM. |
Suma los valores de los campos.
|
TOT. |
Calcula el total de los valores de campo para su uso en un encabezado (incluye pies, subencabezados y subpies de página).
|
xCómo calcular el promedio de los valores de un campo
El prefijo AVE. calcula el valor promedio de un campo particular. El cómputo se realiza en el nivel de clasificación más bajo del comando de visualización. Se calcula como la suma de los valores de campos dentro de un grupo de clasificación dividido por el número de registros en ese grupo de clasificación. Si la solicitud no incluye una frase de clasificación, AVE. calcula la media para todo el informe.
Ejemplo: Cómo calcular el promedio de los valores de un campo
Esta solicitud calcula el promedio del número de horas de invertidas por cada departamento en educación.
TABLE FILE EMPLOYEE
SUM AVE.ED_HRS BY DEPARTMENT
END
A continuación puede ver la salida de la solicitud.
AVE
DEPARTMENT ED_HRS
---------- ------
MIS 38.50
PRODUCTION 20.00
xCómo calcular el promedio de la suma de campos al cuadrado
El prefijo ASQ. calcula la suma promedio de cuadrados, que es un componente de la desviación estándar en análisis estadístico (que en la siguiente imagen aparece como una fórmula).
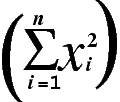
Si el formato de campo es de número entero y recibe un conjunto de números grande, el ASQ. puede ser negativo debido al desborde de campos.
Ejemplo: Cómo calcular el promedio de la suma de campos al cuadrado
Esta solicitud calcula la suma y la suma de campos al cuadrado para el campo DELIVER_AMT.
TABLE FILE SALES
SUM DELIVER_AMT AND ASQ.DELIVER_AMT
BY CITY
END
A continuación puede ver la salida de la solicitud.
ASQ
CITY DELIVER_AMT DELIVER_AMT
---- ----------- -----------
NEW YORK 300 980
NEWARK 60 900
STAMFORD 430 3637
UNIONDALE 80 1600
xCómo calcular valores de campo máximos y mínimos
Los prefijos MAX. y MIN. generan los valores máximos y mínimos, respectivamente, de un grupo de clasificación. Si la solicitud no incluye una frase de clasificación, MAX. y MIN. generan los valores máximos y mínimos para todo el informe.
Ejemplo: Cómo calcular valores de campo máximos y mínimos
Esta solicitud de informe calcula los valores máximos y mínimos de SALARY.
TABLE FILE EMPLOYEE
SUM MAX.SALARY AND MIN.SALARY
END
A continuación puede ver la salida de la solicitud.
MAX MIN
SALARY SALARY
------ ------
$29,700.00 $8,650.00
xCómo calcular los valores de mediana y modo de un campo
Puede usar los operadores de prefijo MDN. (mediana) y MDE. (modo), junto con un comando de visualización de agregación (SUM, WRITE) y un campo numérico o de fecha inteligente, para calcular la mediana y el modo estadísticos de los valores de un campo.
Estos cálculos no están permitidos en los comandos DEFINE, en expresiones WHERE o IF, ni en comandos de resumen. Si se emplean en una solicitud multiverbo, deben aplicarse al valor de agregación más bajo.
La mediana es el valor medio (50° percentil). Si el número de valores es par, la mediana es el promedio de los dos valores medios. El modo es el valor más repetido en un conjunto de valores. Si ninguno de los valores aparece más veces que el resto, MDE. devuelve el valor más bajo.
Ejemplo: Cómo calcula la mediana y el modo
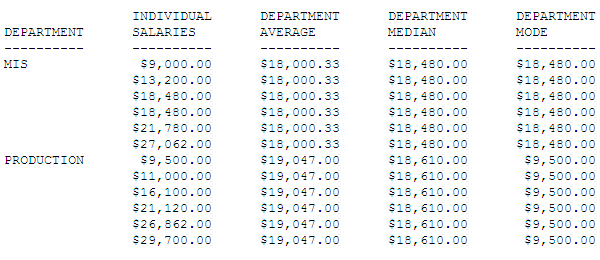
La siguiente solicitud, basada en el origen de datos EMPLOYEE, muestra los salarios actuales y calcula el promedio (media), la mediana y el modo de cada departamento.
TABLE FILE EMPLOYEE
SUM CURR_SAL AS 'INDIVIDUAL,SALARIES'
AVE.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,AVERAGE'
MDN.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,MEDIAN'
MDE.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,MODE'
BY DEPARTMENT
BY CURR_SAL NOPRINT
BY LAST_NAME NOPRINT BY FIRST_NAME NOPRINT
ON TABLE SET PAGE NOPAGE
END
Ambos departamentos tienen el mismo número de empleados. Como los dos valores medios del departamente MIS son iguales, dicho valor es al mismo tiempo el modo y la mediana ($18.480). En el departamento PRODUCTION, la mediana es el promedio de los dos valores medios ($16.100 y $21.120), siendo el modo, al no haber valores duplicados, el valor más bajo ($9.500).
xCómo calcular porcentajes de columnas y filas
Para cada valor individual de columna, PCT. calcula el porcentaje ocupado por ese campo con respecto al valor total de la columna. Puede controlar cómo se distribuyen los valores en la columna al clasificar la columna usando la frase BY. La nueva columna de porcentajes tiene el mismo formato que el campo original.
También puede determinar los porcentajes de los valores de fila. El operador RPCT. calcula el porcentaje que ocupa con respecto al valor total de la fila, para cada valor individual de una fila clasificada mediante la frase ACROSS. Los valores de porcentajes tienen el mismo formato que el campo original.
Ejemplo: Cómo calcular porcentajes de columnas
Para calcular la parte de horas de formación correspondiente a cada usuario, emita la siguiente solicitud:
TABLE FILE EMPLOYEE
SUM ED_HRS PCT.ED_HRS BY LAST_NAME
ON TABLE COLUMN-TOTAL
END
La salida es:
PCT
LAST_NAME ED_HRS ED_HRS
--------- ------ ------
BANNING .00 .00
BLACKWOOD 75.00 21.37
CROSS 45.00 12.82
GREENSPAN 25.00 7.12
IRVING 30.00 8.55
JONES 50.00 14.25
MCCOY .00 .00
MCKNIGHT 50.00 14.25
ROMANS 5.00 1.42
SMITH 46.00 13.11
STEVENS 25.00 7.12
TOTAL 351.00 100.00Dado que PCT. y RPCT adoptan el mismo formato que el campo, puede que el total de la columna no siempre sume 100 debido a la naturaleza de la aritmética de punto flotante.
Ejemplo: Cómo calcular porcentajes de filas
La siguiente solicitud calcula el total de unidades vendidas por cada producto (columna UNIT_SOLD) y el porcentaje que dicho total representa en relación con la suma de todos los productos vendidos en cada ciudad (columna RPCT.UNIT_SOLD).
TABLE FILE SALES
SUM UNIT_SOLD RPCT.UNIT_SOLD ROW-TOTAL
BY PROD_CODE
ACROSS CITY WHERE
CITY EQ 'NEW YORK' OR 'STAMFORD'
END
La salida es:

Puesto que UNIT_SOLD tiene formato de número entero, las columnas creadas por PCT. también tienen formato de número entero (I). Por lo tanto, porcentajes individuales pueden estar truncados y el porcentaje total puede ser menor de 100%. Si necesita totales precisos, vuelva a definir el campo con un formato que indique posiciones decimales (D, F).
xCómo generar un porcentaje directo de una cuenta
Al contar los casos en un archivo, una de las necesidades más comunes de los informes es la de determinar los porcentajes relativos de la suma de cada fila, dentro del número total de casos. Puede lograrlo con la sintaxis siguiente, pero sólo para columnas:
PCT.CNT.fieldname
El formato es un valor decimal de seis dígitos con dos posiciones decimales (F6.2).
Ejemplo: Cómo generar un porcentaje directo de una cuenta
Esta solicitud muestra el porcentaje relativo de los valores en el campo EMP_ID para cada departamento.
TABLE FILE EMPLOYEE
SUM PCT.CNT.EMP_ID
BY DEPARTMENT
END
La salida es:
| PCT.CNT |
DEPARTMENT
---------- | EMP_ID
------ |
MIS | 50.00 |
PRODUCTION | 50.00 |
xCómo agregar y listar valores únicos
El operador de prefijos distinto (DST.) puede usarse para agregar y listar valores únicos de cualquier campo de origen de datos. Su función es parecida a las funciones de columnas SQL COUNT, SUM y AVG (columna DISTINCT), y le permite determinar el número total de valores distintivos en un único pase del origen de datos.
El operador DST. puede usarse con los comandos SUM, PRINT o COUNT, y junto con los operadores de prefijo agregados SUM., CNT. y AVE. Las solicitudes TABLE y TABLEF admiten múltiples operadores DST. Se admiten en solicitudes que emplean las frases BY, ACROSS y FOR.
Tenga en cuenta que, en las solicitudes que emplean el comando PRINT y varios operadores DST, tiene que emitir el comando SET PRINTDST=NEW. Para más información, consulte el manual
Cómo desarrollar aplicaciones de informes.
x
Sintaxis: Cómo Utilizar el operador distintivo
command DST.fieldname
o
SUM [operator].DST.fieldname
donde:
- command
- Es SUM, PRINT o COUNT.
- DST.
- Indica el operador distintivo.
- fieldname
- Indica el nombre de campo o de objeto del campo de visualización.
- operator
- Indica SUM., CNT. o AVE.
Ejemplo: Cómo utilizar el operador distintivo
El procedimiento que solicita una cuenta de valores ED_HRS únicos es:
TABLE FILE EMPLOYEE
SUM CNT.DST.ED_HRS
END
o
TABLE FILE EMPLOYEE
COUNT DST.ED_HRS
END
La salida es:
COUNT
DISTINCT
ED_HRS
--------
9Observe que el recuento incluye registros de los dos empleados que se apellidan SMITH, pero excluye los segundos registros de los valores 50.00, 25.00 y .0, resultando en nueve valores únicos de ED_HRS.
Ejemplo: Cómo contar los valores de campos distintos con múltiples comandos de visualización
La siguiente solicitud, basada en el origen de datos GGSALES, cuenta el número total de registros por región y después, el número de registros, categorías distintas y productos distintos por región y estado. El operador DST o CNT.DST sólo puede usarse con el último comando de visualización.
TABLE FILE GGSALES
COUNT CATEGORY AS 'TOTAL,COUNT'
BY REGION
SUM CNT.CATEGORY AS 'STATE,COUNT'
CNT.DST.CATEGORY CNT.DST.PRODUCT
BY REGION
BY ST
ENDLa salida es:
COUNT COUNT
TOTAL STATE DISTINCT DISTINCT
Region COUNT State COUNT CATEGORY PRODUCT
------ ----- ----- ----- -------- --------
Midwest 1085 IL 362 3 9
MO 361 3 9
TX 362 3 9
Northeast 1084 CT 361 3 10
MA 360 3 10
NY 363 3 10
Southeast 1082 FL 361 3 10
GA 361 3 10
TN 360 3 10
West 1080 CA 721 3 10
WA 359 3 10
x
Referencia: Limitaciones del operador distintivo
- Si vuelve a reformatear una columna creada con el operador COUNT DST. o CNT.DST, debe aplicarle el formato de tipo de datos de número entero (I). Si especifica otro tipo de datos, ocurre el siguiente error:
(FOC950) INVALID REFORMAT OPTION WITH COUNT OR CNT.
- Ocurre el siguiente error al usar los operadores de prefijo CNT., SUM y AVE. con cualquier otro comando de visualización:
(FOC1853) CNT/SUM/AVE.DST CAN ONLY BE USED WITH AGGREGATION VERBS
- Si emplea DST. en un comando MATCH, ocurre el siguiente error:
(FOC1854) THE DST OPERATOR IS ONLY SUPPORTED IN TABLE REQUESTS
- Ocurre el siguiente error al reformatear un campo BY (cuando se usa con el comando PRINT, elnombre de campo se convierte en un campo BY):
(FOC1862) REFORMAT DST.FIELD IS NOT SUPPORTED WITH PRINT
- Si emplea el operador DST. con NOSPLIT, ocurre el siguiente error:
(FOC1864) THE DST OPERATOR IS NOT SUPPORTED WITH NOSPLIT
- El error que sigue tiene lugar si utiliza una solicitud de múltiples verbos, SUM DST.fieldname BY field PRINT fld BY fld (un operador de objeto verbal usado con el comando SUM debe colocarse al más bajo nivel de agregación):
(FOC1867) DST OPERATOR MUST BE AT THE LOWEST LEVEL OF AGGREGATION
- El operador DST. podría no usarse como parte de un HEADING o FOOTING.
xCómo recuperar el primer y el último registro
FST. es un prefijo que muestra el primer registro recuperado seleccionado para un campo determinado. LST. muestra el último campo recuperado seleccionado para un campo determinado.
Al usar los operadores de prefijo FST. y LST., es importante comprender la estructura de su origen de datos.
- Si el registro está en un segmento, con los valores ordenados de menor a mayor (segmento de tipo S1), el primer registro lógico recuperado por FST. es el valor más bajo del conjunto de valores. El operador de prefijo LST. recuperaría, por lo tanto, el valor más alto en el conjunto de valores.
- Si el registro está en un segmento, con los valores ordenados de mayor a menor (segmento de tipo SH1), el primer registro lógico recuperado por FST. es el valor más alto del conjunto de valores. El operador de prefijo LST. recuperaría, en consecuencia, el valor más bajo en el conjunto de valores.
Para más información sobre tipos de segmento y diseño de archivos, consulte el manual Cómo describir datos con el lenguaje WebFOCUS. Si desea reorganizar los datos en el origen de datos o restructurar el origen de datos mientras prepara informes, vaya a Cómo mejorar su procesamiento de informes.
Ejemplo: Cómo recuperar el primer registro
La solicitud que sigue recupera el primer registro lógico en el campo EMP_ID:
TABLE FILE EMPLOYEE
SUM FST.EMP_ID
END
La salida es:
FST
EMP_ID
------
071382660
Ejemplo: Tipos de segmento y recuperación de registros
El origen de datos EMPLOYEE contiene el segmento DEDUCT, que ordena los campos DED_CODE y DED_AMT del menor valor al mayor (segmento del tipo S1). El campo DED_CODE indica el tipo de deducción, por ejemplo CITY, STATE, FED y FICA. La solicitud a continuación recupera el primer registro lógico de DED_CODE para cada empleado:
TABLE FILE EMPLOYEE
SUM FST.DED_CODE
BY EMP_ID
END
La salida es:
FST
EMP_ID DED_CODE
------ --------
071382660 CITY
112847612 CITY
117593129 CITY
119265415 CITY
119329144 CITY
123764317 CITY
126724188 CITY
219984371 CITY
326179357 CITY
451123478 CITY
543729165 CITY
818692173 CITY
Observe, sin embargo, que el comando SUM LST.DED_CODE habría recuperado el último registro lógico para DED_CODE correspondiente a cada empleado.
Si el registro está en un segmento, con los valores ordenados de mayor a menor (segmento de tipo SH1), el primer registro lógico recuperado por FST. es el valor más alto del conjunto de valores. El operador de prefijo LST. recuperaría, por lo tanto, el valor más bajo en el conjunto de valores.
Por ejemplo, el origen de datos EMPLOYEE contiene el segmento PAYINFO, que ordena los campos JOBCODE, SALARY, PCT_INC y DAT_INC de mayor a menor (segmento de tipo SH1). La solicitud a continuación recupera el primer registro lógico de SALARY para cada empleado:
TABLEF FILE EMPLOYEE
SUM FST.SALARY
BY EMP_ID
END
La salida es:
FST
EMP_ID SALARY
------ ------
071382660 $11,000.00
112847612 $13,200.00
117593129 $18,480.00
119265415 $9,500.00
119329144 $29,700.00
123764317 $26,862.00
126724188 $21,120.00
219984371 $18,480.00
326179357 $21,780.00
451123478 $16,100.00
543729165 $9,000.00
818692173 $27,062.00
Sin embargo, el comando SUM LST.SALARY habría recuperado el último registro lógico para SALARY de cada empleado.
xCómo sumar y contar valores
Puede contar ocurrencias y sumar valores en un solo comando de visualización con los operadores de prefijo CNT., SUM. y TOT. Al igual que el comando COUNT, CNT. cuenta los casos del campo que prefija. Al igual que el comando SUM, SUM. suma los valores del campo que prefija. TOT. suma los valores del campo al que va añadido como prefijo cuando se usa en un encabezado (al igual que pies, subencabezados y subpies).
Ejemplo: Cómo contar valores con CNT
La siguiente solicitud cuenta las ocurrencias de PRODUCT_ID y suma el valor de UNIT_PRICE.
TABLE FILE GGPRODS
SUM CNT.PRODUCT_ID AND UNIT_PRICE
END
La salida es:
Product
Code Unit
COUNT Price
------- -----
10 660.00
Ejemplo: Cómo sumar valores con SUM
La siguiente solicitud cuenta las ocurrencias de PRODUCT_ID y suma el valor de UNIT_PRICE.
TABLE FILE GGPRODS
COUNT PRODUCT_ID AND SUM.UNIT_PRICE
END
La salida es:
Product
Code Unit
COUNT Price
------- -----
10 660.00
Ejemplo: Sumar valores con TOT
La solicitud siguiente usa el operador de prefijo TOT para mostrar el total de salarios actuales de todos los empleados.
TABLE FILE EMPLOYEE
PRINT LAST_NAME
BY DEPARTMENT
ON TABLE SUBFOOT
"Total salaries equal: <TOT.CURR_SAL"
END
La salida es:
DEPARTMENT LAST_NAME
---------- ---------
MIS SMITH
JONES
MCCOY
BLACKWOOD
GREENSPAN
CROSS
PRODUCTION STEVENS
SMITH
BANNING
IRVING
ROMANS
MCKNIGHT
Total salaries equal: $222,284.00
xCómo catalogar valores de campo de clasificación con RNK.
Cuando se usa RANKED BY fieldname en una frase de clasificación en una solicitud TABLE, no sólo clasifica los datos por el campo especificado, sino que también asigna un valor RANK a los casos. El operador de prefijo RNK. también calcula el rango al tiempo que permite que el valor RANK se imprima en cualquier parte de la página. Se usa este operador especificando RNK.fieldname, donde fieldname es un campo BY en la solicitud.
El proceso de catalogación ocurre después de seleccionar y clasificar los registros. Por lo tanto, no se puede usar el operador RNK. en una prueba de selección WHERE o IF o en un campo virtual (DEFINE). Sin embargo, se puede usar RNK. fieldname en una prueba WHERE o IF TOTAL o en un valor calculado (COMPUTE). Puede cambiar el título de columna predeterminada por el campo de catalogación usando una frase AS.
Puede aplicar el operador RANK. a múltiples campos de clasificación, en cuyo caso, el rango de cada campo BY se calcula en su campo BY de nivel más alto.
x
Sintaxis: Cómo Calcular catalogaciones con el operador de prefijo Operador de prefijo
En un comando PRINT, una expresión COMPUTE o IF/WHERE TOTAL:
RNK.field ...
donde:
- campo
- Es un campo de clasificación vertical (BY) en la solicitud.
Ejemplo: Cómo catalogar en grupos de clasificación
La siguiente solicitud cataloga años de servicio en un departamento y salario en años de servicio y departamento. Fíjese que los años de servicio dependen del valor de TODAY. La salida en este ejemplo era válida cuando se realizó en septiembre de 2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT SALARY
RNK.YRS_SERVICE AS 'RANKING,BY,SERVICE'
RNK.SALARY AS 'SALARY,RANK'
BY DEPT
BY HIGHEST YRS_SERVICE
BY HIGHEST SALARY NOPRINT
WHERE DEPT EQ 'MARKETING' OR 'SALES'
ON TABLE SET PAGE NOPAGE
ENDLa salida es:
RANKING
BY SALARY
DEPT YRS_SERVICE SALARY SERVICE RANK
---- ----------- ------ ------- ------
MARKETING 17 $55,500.00 1 1
$55,500.00 1 1
16 $62,500.00 2 1
$62,500.00 2 1
$62,500.00 2 1
$58,800.00 2 2
$52,000.00 2 3
$35,200.00 2 4
$32,300.00 2 5
15 $50,500.00 3 1
$43,400.00 3 2
SALES 17 $115,000.00 1 1
$54,100.00 1 2
16 $70,000.00 2 1
$43,000.00 2 2
15 $43,600.00 3 1
$39,000.00 3 2
15 $30,500.00 3 3
Ejemplo: Cómo usar RNK. en una prueba de WHERE TOTAL
La siguiente solicitud muestra sólo aquellas filas en los dos niveles superiores de salario que corresponden a la categoría de años de servicio. Fíjese que los años de servicio dependen del valor de TODAY. La salida en este ejemplo era válida cuando se realizó en septiembre de 2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME RNK.SALARY
BY HIGHEST YRS_SERVICE BY HIGHEST SALARY
WHERE TOTAL RNK.SALARY LE 2
END
La salida es:
RANK
YRS_SERVICE SALARY LASTNAME FIRSTNAME SALARY
----------- ------ -------- --------- ------
17 $115,000.00 LASTRA KAREN 1
$80,500.00 NOZAWA JIM 2
16 $83,000.00 SANCHEZ EVELYN 1
$70,000.00 CASSANOVA LOIS 2
15 $62,500.00 HIRSCHMAN ROSE 1
WANG JOHN 1
$50,500.00 LEWIS CASSANDRA 2
Ejemplo: Cómo usar RNK. en un comando COMPUTE
La siguiente solicitud coloca un banderín en Y para registros en los cuales el rango salarial en el departamento es menor o igual a 5 y el rango de años de servicio en salario y departamento es menor o igual a 6. De lo contrario, el banderín tiene un valor de N. Fíjese que los años de servicio dependen del valor de TODAY. La salida en este ejemplo era válida cuando se realizó en septiembre de 2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT RNK.SALARY RNK.YRS_SERVICE
COMPUTE FLAG/A1 = IF RNK.SALARY LE 5 AND RNK.YRS_SERVICE LE 6
THEN 'Y' ELSE 'N';
BY DEPT BY SALARY BY YRS_SERVICE
WHERE DEPT EQ 'MARKETING' OR 'SALES'
ON TABLE SET PAGE NOPAGE
ENDLa salida es:
RANK RANK
DEPT SALARY YRS_SERVICE SALARY YRS_SERVICE FLAG
---- ------ ----------- ------ ----------- ----
MARKETING $32,300.00 16 1 1 Y
$35,200.00 16 2 1 Y
$43,400.00 15 3 1 Y
$50,500.00 15 4 1 Y
$52,000.00 16 5 1 Y
$55,500.00 17 6 1 N
6 1 N
$58,800.00 16 7 1 N
$62,500.00 16 8 1 N
8 1 N
8 1 N
SALES $30,500.00 15 1 1 Y
$39,000.00 15 2 1 Y
$43,000.00 16 3 1 Y
$43,600.00 15 4 1 Y
$54,100.00 17 5 1 Y
$70,000.00 16 6 1 N
$115,000.00 17 7 1 N