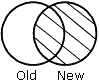Especifica cómo se deben comparar los registros recuperados de los archivos.
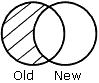
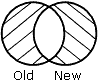
Los resultados de cada frase se representan gráficamente mediante diagramas de Venn. En los diagramas, el círculo de la izquierda representa el antiguo origen de datos; el círculo de la derecha representa al nuevo origen de datos y las áreas sombreadas representan los datos escritos en el archivo HOLD.
OLD-OR-NEW especifica que todos los registros del antiguo origen de datos y del nuevo aparecen en el archivo HOLD. Si se omite la línea AFTER MATCH, esta es la opción predeterminada.
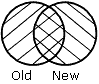
OLD-AND-NEW especifica que los registros que aparezcan en el antiguo origen de datos y en el nuevo, aparecerán en el archivo HOLD. (La intersección de los conjuntos).
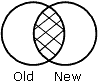
OLD-NOT-NEW especifica que los registros que aparezcan solamente en el antiguo origen de datos aparecerán en el archivo HOLD.
NEW-NOT-OLD especifica que los registros que aparezcan solamente en el nuevo origen de datos aparecerán en el archivo HOLD.
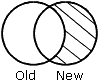
OLD-NOR-NEW especifica que sólo los registros que se encuentren en el antiguo origen de datos pero no en el nuevo, o en el nuevo pero no en el antiguo, aparecerán en el archivo HOLD (el conjunto completo de todos los verbos sin correspondencia de ambos orígenes de datos).
OLD especifica que todos los registros del antiguo origen de datos y Cualquier registros correspondientes en el nuevo origen de datos se fusionen en el archivo HOLD.
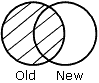
NEW especifica que todos los registros del nuevo origen de datos y Cualquier registros correspondientes en el viejo origen de datos se fusionen en el archivo HOLD.