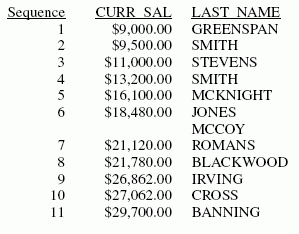
x
Referencia: Notas de uso de SET RANK
- El operador de prefijo RNK. no se ve afectado por el parámetro RANK.
- Los números de ranking propagados al archivo HOLD, dependen de la configuración del parámetro RANK.
Ejemplo: Cómo establecer un ranking de valores en un origen de datos de FOCUS
La siguiente solicitud, basada en el origen de datos EMPDATA, establece un ranking de salarios descendente, por división. El parámetro RANK se encuentra establecido en DENSE (por defecto).
SET RANK = DENSE
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME
RANKED BY HIGHEST 12 SALARY
BY DIV
ON TABLE SET PAGE NOPAGE
END
La salida indica que hay seis empleados en el número 6 del ranking. Con el método denso, el próximo número del ranking será el número entero siguiente, más alto, el 7.
RANK SALARY DIV LASTNAME FIRSTNAME
---- ------ --- -------- ---------
1 $115,000.00 CE LASTRA KAREN
2 $83,000.00 CORP SANCHEZ EVELYN
3 $80,500.00 SE NOZAWA JIM
4 $79,000.00 CORP SOPENA BEN
5 $70,000.00 WE CASSANOVA LOIS
6 $62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
7 $58,800.00 WE GOTLIEB CHRIS
8 $55,500.00 CORP VALINO DANIEL
NE PATEL DORINA
9 $54,100.00 CE ADDAMS PETER
WE FERNSTEIN ERWIN
10 $52,000.00 NE LIEBER JEFF
11 $50,500.00 SE LEWIS CASSANDRA
12 $49,500.00 CE ROSENTHAL KATRINA
SE WANG KATE Si ejecuta la misma solicitud con SET RANK=SPARSE, obtendrá la siguiente salida. Puesto que la categoría 6 del ranking incluye seis empleados, el próximo número del ranking será 6 + 6.
RANK SALARY DIV LASTNAME FIRSTNAME
---- ------ --- -------- ---------
1 $115,000.00 CE LASTRA KAREN
2 $83,000.00 CORP SANCHEZ EVELYN
3 $80,500.00 SE NOZAWA JIM
4 $79,000.00 CORP SOPENA BEN
5 $70,000.00 WE CASSANOVA LOIS
6 $62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
12 $58,800.00 WE GOTLIEB CHRIS
Ejemplo: Cómo limitar el número de valores de campos de clasificación
La siguiente solicitud, basada en el origen de datos EMPDATA, clasifica los salarios en un orden descendente, por división, e imprime los 12 más altos. El parámetro RANK se encuentra establecido en DENSE (por defecto).
SET RANK = DENSE
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME
BY HIGHEST 12 SALARY
BY DIV
ON TABLE SET PAGE NOPAGE
END
La salida presenta los 12 valores distintos de salario más altos, aunque algunos de los empleados tengan el mismo salario.
SALARY DIV LASTNAME FIRSTNAME
------ --- -------- ---------
$115,000.00 CE LASTRA KAREN
$83,000.00 CORP SANCHEZ EVELYN
$80,500.00 SE NOZAWA JIM
$79,000.00 CORP SOPENA BEN
$70,000.00 WE CASSANOVA LOIS
$62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
$58,800.00 WE GOTLIEB CHRIS
$55,500.00 CORP VALINO DANIEL
NE PATEL DORINA
$54,100.00 CE ADDAMS PETER
WE FERNSTEIN ERWIN
$52,000.00 NE LIEBER JEFF
$50,500.00 SE LEWIS CASSANDRA
$49,500.00 CE ROSENTHAL KATRINA
SE WANG KATE Si ejecuta la misma solicitud con SET RANK=SPARSE, obtendrá la siguiente salida. Puesto que hay seis empleados con un salario de $62,500, el valor se cuenta 6 veces para que sólo aparezcan 12 líneas (siete valores distintos de salario) en la salida.
SALARY DIV LASTNAME FIRSTNAME
------ --- -------- ---------
$115,000.00 CE LASTRA KAREN
$83,000.00 CORP SANCHEZ EVELYN
$80,500.00 SE NOZAWA JIM
$79,000.00 CORP SOPENA BEN
$70,000.00 WE CASSANOVA LOIS
$62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
$58,800.00 WE GOTLIEB CHRIS