In diesem Abschnitt: Referenz: |
Wenn Sie zwei Datenquellen verbinden, kann es vorkommen, dass es für manche Datensätze in einer der Dateien keine entsprechenden Datensätze in der anderen Datei gibt. Wenn ein Report Datensätze weglässt, die sich nicht in beiden Dateien befinden, wird dies als innerer Join bezeichnet. Wenn ein Report alle übereinstimmenden Datensätze sowie alle Datensätze der Host-Datei anzeigt, denen entsprechende Querverweisdatensätze fehlen, wird der Join als linker äußerer Join bezeichnet.
Der Befehl SET ALL bestimmt global, wie alle Joins implementiert werden. Wenn der SET ALL=ON-Befehl ausgegeben wird, werden alle Joins als äußere Joins behandelt. Bei SET ALL=OFF (Default) werden alle Joins als innere Joins behandelt.
Jeder JOIN-Befehl kann explizit angeben, welche Art von Join ausgeführt werden soll, wodurch die globale Einstellung lokal überschrieben werden kann. Diese Syntax wird von FOCUS, XFOCUS, Relational, VSAM, IMS und Adabas unterstützt. Wenn Sie im JOIN-Befehl nicht den Typ des Joins spezifizieren, dann bestimmt die Einstellung des ALL-Parameters den Typ des Joins, der ausgeführt werden soll.
Sie können Datenquellen auch mit einer der beiden Methoden verbinden, mithilfe derer Datensätze von unterschiedlichen Datenquellen gegenübergestellt werden. Die erste Methode wird als Equijoin bezeichnet und die zweite Methode als bedingter Join. Es ist wichtig bei der Auswahl der geeigneten Verbindungsmethode zu wissen, dass es effizienter ist, einen Equijoin anstelle eines bedingten Joins zu verwenden, falls eine Gleichheitsbedingung zwischen den beiden Datenquellen vorliegt.
Sie können eine Equijoin-Struktur verwenden, wenn Sie zwei oder mehrere Datenquellen verbinden, die zwei Felder, d.h. eines in jeder Datenquelle, mit Formaten (Zeichen, numerisch oder Datum) und Werte gemein haben. Das Verbinden eines Produktcode-Feldes in einer Verkaufsdatenquelle (die Hostdatei) mit dem Feld Produktcode in einer Produktdatenquelle (die Querverweisdatei) ist ein Beispiel für einen Equijoin. Weitere Informationen über die Verwendung von Equijoins finden Sie unter Einen Equijoin erstellen.
Bedingte Joins verwenden auf WHERE basierende Syntax, um Joins auf WHERE-Kriterien basierend anzugeben, und nicht nur auf Gleichheit der Felder basierend. Außerdem müssen das Format der Host- und der Querverweis-Join-Felder nicht übereinstimmen. Angenommen Sie haben eine Datenquelle, die Angestellte nach ihren ID-Nummern auflistet (die Hostdatei) und eine andere Datenquelle, die Trainingskurse und die Angestellten auflistet, die diese Kurse besucht haben (die Querverweisdatei). Unter Verwendung eines bedingten Joins könnten Sie eine Angestellten-ID in der Hostdatei mit einer Angestellten-ID in der Querverweisdatei verbinden, um zu bestimmen, welche Angestellten in einem gewissen Zeitabschnitt Trainingskurse besucht haben (die WHERE-Bedingung). Weitere Informationen über bedingte Joins finden Sie unter Einen bedingten Join verwenden.
Joins können außerdem eindeutig oder nicht eindeutig sein. Eine eindeutige (1:1) Join-Struktur stellt einen Wert in der Host-Datenquelle einem Wert in der Querverweisdatenquelle gegenüber. Das Verbinden einer Angestellten-ID in einer Angestelltendatenquelle mit einer Angestellten-ID in einer Gehaltsdatenquelle ist ein Beispiel für eine eindeutige Equijoin-Struktur.
Eine nicht eindeutige (1:n) Join-Struktur stellt einen Wert in der Host-Datenquelle mehreren Werten im Querverweisfeld gegenüber. Das Verbinden einer Angestellten-ID in der Angestelltendatenquelle einer Firma mit einer Angestellten-ID in einer Datenquelle, die alle Trainingskurse dieser Firma auflistet, ergibt eine Liste aller Kurse, die von einem Angestellten besucht wurden. Es handelt sich hierbei also um das Verbinden der einen Instanz jeder ID in der Hostdatei mit mehreren Instanzen dieser ID in der Querverweisdatei.
Weitere Informationen über eindeutige und nicht eindeutige Joins finden Sie unter Eindeutige und nicht eindeutige verbundene Strukturen.
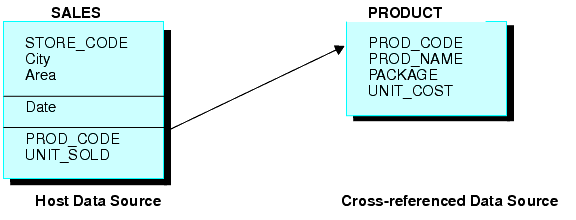
Betrachten Sie die Datenquellen SALES und PRODUCT. Jeder Filialendatensatz in SALES kann viele Instanzen des Feldes PROD_CODE enthalten. Es wäre überflüssig, die zugehörigen Produktinformationen mit jeder Instanz des Produktcodes zu speichern. Stattdessen wird PROD_CODE in der Datenquelle SALES mit PROD_CODE in der Datenquelle PRODUCT verbunden. PRODUCT enthält eine Instanz jedes Produktcodes und zugehöriger Produktinformationen. Hierdurch wird Speicherplatz eingespart und die Produktinformationenen können einfacher bearbeitet werden. Die verbundene Struktur in der folgenden Abbildung ist ein Beispiel für einen Equijoin:
Die Verwendung von Datenquellen als Host- und Querverweisdateien in verbundenen Strukturen hängt vom Typ der Datenquellen ab, die Sie verbinden:
SET PASS = pswd1 IN file1, pswd2 IN file2
Individuelle DBA-Informationen bleiben für jede Datei im JOIN erhalten. Genaueres über das DBAFILE-Attribut finden Sie im Handbuch Daten mit der WebFOCUS-Sprache beschreiben .
Vorgehensweise: |
In einer eindeutigen verbundenen Struktur bezieht sich ein Wert im Hostfeld auf einen Wert im Querverweisfeld. In einer nicht eindeutigen verbundenen Struktur bezieht sich ein Wert im Hostfeld auf mehrere Werte im Querverweisfeld.
Der ALL-Parameter in einem JOIN-Befehl gibt an, dass die verbundene Struktur nicht eindeutig ist.
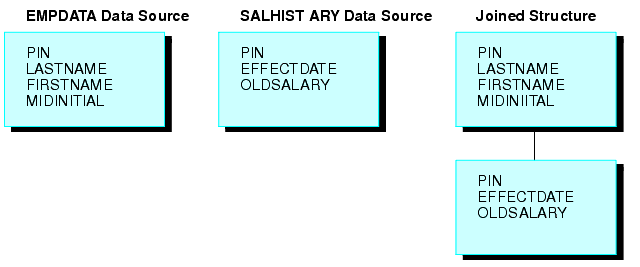
Im folgenden Beispiel sehen Sie eine eindeutige verbundene Struktur. Zwei FOCUS-Datenquellen werden verbunden: eine EMPDATA-Datenquelle und eine SALHIST-Datenquelle. Beide Datenquellen sind durch PIN gegliedert und werden mit einem PIN-Feld im Root-Segment beider Dateien verbunden. Jeder PIN besitzt eine Segmentinstanz in der EMPDATA-Datenquelle und eine Instanz in der SALHIST-Datenquelle. Geben Sie, um diese beiden Datenquellen zu verbinden, den folgenden JOIN-Befehl aus:
JOIN PIN IN EMPDATA TO PIN IN SALHIST
Falls ein Feldwert in der Hostdatei in mehreren Segmentinstanzen in der Querverweisdatei auftreten kann, sollten Sie die Phrase ALL in die JOIN-Syntax aufnehmen. Diese Struktur wird als nicht eindeutige Join-Struktur bezeichnet.
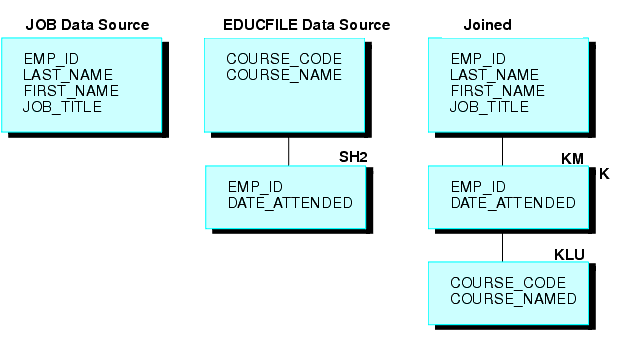
Nehmen wir beispielsweise an, dass die folgenden zwei FOCUS-Datenquellen verbunden sind: Die JOB-Datenquelle und eine EDUCFILE-Datenquelle, in der aufgezeichnet wird, welche Angestellten an betriebsinternen Kursen teilgenommen haben. Die verbundene Struktur ist im folgenden Diagramm zu sehen.
Die JOB-Datenquelle ist nach Angestellten sortiert, die EDUCFILE-Datenquelle jedoch nach Kurs. Die Datenquellen werden mit dem Feld EMP_ID verbunden. Da ein Angestellter nur eine Stellung hat, jedoch mehrere Kurse belegen kann, besitzt er nur eine Segmentinstanz in der Datenquelle JOB, kann aber in der Datenquelle EDUCFILE so viele Instanzen haben, wie er Kurse belegt hat.
Geben Sie, um diese beiden Datenquellen zu verbinden, den folgenden JOIN-Befehl mit der ALL-Phrase aus:
JOIN EMP_ID IN JOB TO ALL EMP_ID IN EDUCFILE
Wenn ein übergeordnetes Segment zwei oder mehr eindeutige untergeordnete Segmente hat, die alle mehrere untergeordnete Segmente haben, kann es vorkommen, dass der Report einen fehlenden Wert falsch anzeigt. Dies kann dazu führen, dass die restlichen untergeordneten Werte im Report falsch ausgerichtet werden. Diese falsch ausgerichteten Werte werden als Verzögerungswerte bezeichnet. Der Parameter JOINOPT stellt die korrekte Ausrichtung der Ausgabe sicher, indem er Verzögerungswerte korrigiert.
SET JOINOPT={NEW|OLD}Hierbei gilt:
Hinweis: Der Parameter JOINOPT aktiviert auch Joins zwischen unterschiedlichen numerischen Datentypen. Informationen finden Sie unter Felder mit unterschiedlichen numerischen Datentypen verbinden.
Dieses Beispiel ist hypothetisch. Es wird der Parameter JOINOPT verwendet, um Verzögerungswerte zu korrigieren. Verzögerungswerte zeigen fehlende Daten an, wodurch jeder Wert um eine Zeile verschoben angezeigt wird.
Eine Hostdatei mit einem Segment (ROUTES) wird mit zwei Dateien verbunden (ORIGIN und DEST), die jeweils zwei Segmente haben. Die Dateien werden verknüpft und erzeugen einen Report, der alle Zugnummern und für alle Bahnhöfe die ensprechende Stadt anzeigt.
Die folgende Anfrage druckt die Abfahrtsstadt (OR_CITY) und die Ankunftsstadt (DE_CITY). Beachten Sie, dass fehlende Daten erzeugt werden, wodurch die Daten für Bahnhöfe und die entsprechenden Städte verzögert werden und sich um eine Zeile verschieben.
TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
Die Ausgabe ist:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL . 202 BOS BOSTON BLT ATLANTA 303 DET DETROIT BOS BALTIMORE 404 CHI CHICAGO DET BOSTON 505 BOS BOSTON STL DETROIT 505 BOS . STL ST. LOUIS
Wenn Sie SET JOINOPT=NEW ausgeben, können die Segmente in der erwarteten Reihenfolge abgerufen werden (von links nach rechts und von oben nach unten), und zwar ohne fehlende Daten.
SET JOINOPT=NEW TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
Der korrekte Report hat nur 5 Zeilen, nicht 6, und die Daten für Bahnhof und Stadt sind richtig ausgerichtet. Die Ausgabe ist:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL ATLANTA 202 BOS BOSTON BLT BALTIMORE 303 DET DETROIT BOS BOSTON 404 CHI CHICAGO DET DETROIT 505 BOS BOSTON STL ST. LOUIS
Referenz: |
Sie können eine FOCUS- oder IMS-Datenquelle mit sich selbst verbinden, wodurch eine rekursive Struktur entsteht. In der üblichsten rekursiven Struktur wird ein übergeordnetes Segment mit einem untergeordneten Segment verbunden, so dass das übergeordnete Segment zum untergeordneten Segment wird und umgekehrt. Diese Methode (z. B. hilfreich beim Speichern von Stücklisten) ermöglicht es Ihnen, Reports aus Datenquellen zu erstellen, als ob diese mehr Segmentebenen hätten, als es tatsächlich der Fall ist.
Beispielsweise besteht die Datenquelle GENERIC, die unterhalb zu sehen ist, aus den Segmenten A und B.
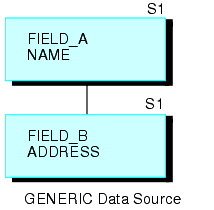
Durch die folgende Anfrage entsteht eine rekursive Struktur:
JOIN FIELD_B IN GENERIC TAG G1 TO FIELD_A IN GENERIC TAG G2 AS RECURSIV
Dies ergibt die verbundene Struktur, die unterhalb zu sehen ist.
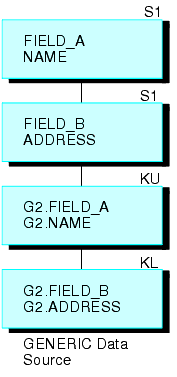
Beachten Sie, dass zwei Segmente am Ende wiederholt werden. Stellen Sie entweder, um auf die Felder in den wiederholten Segmenten (nicht auf das Feld, mit dem Sie verbinden) zu verweisen, den Feldnamen und Aliasen den Tag-Namen voran und trennen Sie diese mit einen Punkt, oder hängen Sie den Feldnamen und Aliasen die ersten vier Zeichen des JOIN-Namen an. Im obigen Beispiel ist der JOIN-Name RECURSIV. Sie sollten auf FIELD_B im unteren Segment mit G2.FIELD_B (oder RECUFIELD_B) verweisen. Weitere Informationen zu diesem Thema finden Sie unter Verwendungshinweise für rekursive verbundene Strukturen.
In diesem Beispiel wird beschrieben, wie rekursive Joins verwendet werden, um eine Stückliste zu speichern und einen Report über sie zu erstellen. Nehmen wir an, dass Sie eine Datenquelle mit dem Namen AIRCRAFT erstellen, die die Stückliste für ein Firmenflugzeug enthält. Die Datenquelle zeichnet Daten auf drei Ebenen von Flugzeugteilen auf:
Die Datenquelle muss jedes Teil, die Beschreibung des Teils und die Kleinteile, aus denen das Teil besteht, aufzeichnen. Manche Teile, wie z. B. Schrauben und Muttern, kommen im gesamten Flugzeug häufig vor. Wenn Sie eine Struktur mit drei Segmenten erstellen, d. h. ein Segment für jede Ebene, werden die Beschreibungen für häufig verwendete Teile überall, wo diese Teile verwendet werden, wiederholt.
Entwerfen Sie, um diese Wiederholungen zu reduzieren, eine Datenquelle, die nur zwei Segmente enthält (wie es im folgenden Diagramm zu sehen ist). Das obere Segment beschreibt alle Teile des Flugzeugs, ob groß oder klein. Das untere Segment listet die Komponenten ohne Beschreibung auf.
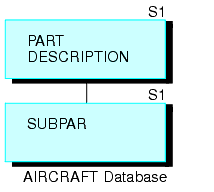
Jedes Teil (außer den Hauptbereichen) wird sowohl im oberen Segment, in dem es beschrieben wird, angezeigt, als auch im unteren Segment, in dem es als Komponente eines größeren Teils aufgelistet wird. (Die kleinsten Teile, wie z. B. Muttern und Schrauben, werden im oberen Segment angezeigt, ohne eine untergeordnete Instanz im unteren Segment zu besitzen.) Beachten Sie, dass jedes Teil, unabhängig davon, wie oft es im Flugzeug verwendet wird, nur einmal beschrieben wird.
Wenn Sie das untere Segment mit dem oberen Segment verbinden, können die Beschreibungen der Komponenten im unteren Segment abgerufen werden. Die Hauptbereiche der ersten Ebene können auch mit Kleinteilen der dritten Ebene verbunden werden, wobei von der ersten Ebene zur zweiten Ebene und dann zur dritten Ebene gegangen wird. Die Struktur verhält sich daher wie eine Datenquelle mit drei Ebenen, obwohl es sich tatsächlich um eine effizientere Datenquelle mit zwei Ebenen handelt.
CABIN ist z. B. ein Bereich der ersten Ebene, der im oberen Segment angezeigt wird. Er listet SEATS als eine Komponente im unteren Segment auf. SEATS wird auch im oberen Segment angezeigt. Es listet BOLTS als eine Komponente im unteren Segment auf. Wenn Sie nun das untere Segment mit dem oberen Segment verbinden, können Sie von CABIN zu SEATS und von SEATS zu BOLTS springen.

Verbinden Sie mit diesem JOIN-Befehl das untere Segment mit dem oberen Segment:
JOIN SUBPART IN AIRCRAFT TO PART IN AIRCRAFT AS SUB
Dadurch entsteht die folgende rekursive Struktur.
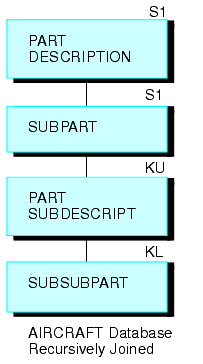
Sie können dann für alle drei Datenebenen einen Report mit diesem TABLE-Befehl erstellen (das Feld SUBDESCRIPT beschreibt den Inhalt des Feldes SUBPART):
TABLE FILE AIRCRAFT PRINT SUBPART BY PART BY SUBPART BY SUBDESCRIPT END
| WebFOCUS |