The FOCUS for SQL EXPLAIN utility is an interactive
development tool that helps you fine-tune FOCUS query performance.
It invokes the RDBMS EXPLAIN function to analyze the efficiency
of data retrieval paths for TABLE requests. You cannot use the EXPLAIN
utility with MODIFY, MAINTAIN, or MATCH FILE requests. The analysis
result is displayed in the FOCUS Hot Screen facility. You can save
or print it for further examination.
xEXPLAIN Processing Overview
Given a TABLE request, the EXPLAIN utility invokes the
adapter and generates SQL statements using its normal mechanisms,
the FOCUS TABLE parser and Dialogue Manager.
However, instead of processing the request, FOCUS directs the
RDBMS to invoke its own native EXPLAIN function and analyze the
generated statements. The analysis produces a detailed evaluation
of the access path, the methodology for retrieving the data
for that request.
The RDBMS places this access path information into a table. The
FOCUS EXPLAIN utility reads these tables and generates a clear and
detailed report containing valuable information about the performance
characteristics of your query, information that anyone familiar
with the RDBMS and its performance characteristics can understand
and analyze.
xUsing the EXPLAIN Utility
Enter FOCUS and execute the EXPLAIN utility with the
following syntax
EX expproc
where:
- expproc
Can be one of the following:
- EXPDB2
Is the FOCEXEC that invokes the DB2 EXPLAIN function.
- EXPDBC
Is the FOCEXEC that invokes the Teradata EXPLAIN function.
Press the Enter key.
Note: If the IM parameter was set to zero when the adapter
was installed, you do not have access to the EXPLAIN utility. The
adapter will generate error message FOC1638 if you attempt to use
it. See the adapter installation instructions for more information.
The EXPLAIN utility cannot analyze an interactive TABLE request.
You must provide the name of a FOCEXEC on the main window. However,
you can access the TED editor from the FOCUS EXPLAIN utility and
create or change the TABLE request at will.
If you do not have the tables required for executing the RDBMS
EXPLAIN function, the FOCUS EXPLAIN utility attempts to create them.
In DB2, you need appropriate authorization for creating tables,
otherwise an SQLCODE of -551 results. The report results from the FOCUS
EXPLAIN utility are displayed in Hot Screen. You can save or print
them for later examination.
Note: DB2 v10 and above require the plan table to be created
in Unicode with a Unicode database.
The main window presents three choices:
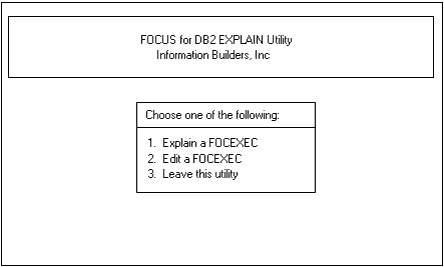
To make a selection, move your cursor under one of the numbers
and press the Enter key. To exit the utility
and return to the FOCUS command line, press the PF3 key. The choices
are:
1. | Explain a FOCEXEC | Invokes the RDBMS EXPLAIN command for the
TABLE request in your FOCEXEC. |
2. | Edit a FOCEXEC | Invokes the TED editor from within the FOCUS EXPLAIN
utility. You can create a new FOCEXEC or edit an existing one. |
3. | Leave this utility | Returns you to FOCUS, deleting any entries
made in the RDBMS EXPLAIN tables. |
At any point, you can use the PF3 key to return to a previous
window.
If you select Choice 1 or 2, you are asked for the name of your
FOCEXEC:

If you are creating a new FOCEXEC, the same FOCEXEC naming conventions
apply here as for the FOCUS EXECUTE (EX) command. Specify the z/OS
member name. If you have already used TED (Choice 2), the name of
the most recent FOCEXEC is automatically supplied.
Press the Enter key and continue with
either the EXPLAIN option or the TED editor:
- The EXPLAIN option.
For DB2, the option to explain
a FOCEXEC requires a query number, an internal control number used
by the RDBMS when populating the EXPLAIN tables. You can choose
any number between 1 and 32,767. However, if you choose a number
that already exists, the EXPLAIN utility informs you of its existence
and deletes all entries with that number before processing your
request. Therefore, make sure the number you choose does not correspond
to an existing entry that you would like to keep. If there are no
existing entries in the EXPLAIN tables, any number will do.
For Teradata,
no query number is needed. If you are prompted for a query number,
press Enter again.
For example, the
query number 1888 has been entered on the following screen:

At
this point, the message PLEASE WAIT, PROCESSING YOUR REQUEST displays, followed
by your EXPLAIN report.
Your EXPLAIN report is displayed in
the Hot Screen facility. All Hot Screen options are available. When
you exit Hot Screen, you return to the first window and can evaluate another
request.
- The TED editor. Edit a new or existing FOCEXEC. When you are
finished, type FILE (to save your edits) or QUIT. Do not issue the
RUN command from TED within the EXPLAIN utility. You return to the
initial main window and can evaluate your FOCEXEC with Choice 1,
the EXPLAIN option.
Note:
- With the EXPLAIN option (Choice 1), if you:
- Specify
a FOCEXEC that generates FOCUS or SQL errors, the EXPLAIN utility
stops processing and you return to the utility main menu.
- Misspell the name of a FOCEXEC or specify one that does not
exist, the EXPLAIN utility stops processing and you return to the
FOCUS command prompt.
- Do not execute large Dialogue Manager applications through the
EXPLAIN utility. The FOCUS TABLE parser executes the Dialogue Manager
statements and may produce unpredictable results.
- Create separate FOCEXECs for evaluating individual report requests.
Experiment with alternate parameters to improve response time and
RDBMS performance.
- Do not use the STMTRACE component in any FOCEXEC that you evaluate
with the EXPLAIN utility.
xSample EXPLAIN Report for DB2
FOCEXEC RPT1 contains the following TABLE request:
TABLE FILE INVQ5
SUM PRICE BY PARTNO
WHERE DESCRIPTION EQ 'BOLT' OR 'NUT' OR 'SCREW'
WHERE PRICE GT .30
IF TOTAL PRICE GT 1
END
The EXPLAIN output consists of two reports.
The first is a one-page report:
PAGE 1
EXPLAIN REPORT 1 FOR FOCEXEC RPT1 RUN ON 06/01/99
QUERY NUMBER IS 1000
THE FOLLOWING SQL STATEMENT(S) WILL BE EXPLAINED
SELECT T1.PARTNO, SUM(T2.PRICE) FROM "TESTID"."INVENT5" T1,
"TESTID"."QUOT5" T2 WHERE (T2.PARTNO = T1.PARTNO) AND
(T1.DESCRIPTION IN('BOLT', 'NUT', 'SCREW')) AND (T2.PRICE > .3)
GROUP BY T1.PARTNO HAVING (SUM(T2.PRICE) > 1.) ORDER BY
T1.PARTNO FOR FETCH ONLY;
MORE |
The second is a four-page report:
PAGE 1
EXPLAIN REPORT 2 FOR FOCEXEC RPT1 RUN ON 06/01/99
QUERY NUMBER IS 1000
1ST ACCESS OF DATA
TABLE NAME ........................: TESTID.INVENT5
TABLE NUMBER ......................: 1
JOIN METHOD .......................: FIRST TABLE ACCESSED
MULTIPLE INDEX OPERATION SEQUENCE .: 0
INDEX ACCESS TYPE .................: DIRECT INDEX ACCESS
# OF INDEX KEYS USED ..............: 0
INDEX NAME ........................: TESTID.INVENT5IX
INDEX ONLY ACCESS? ................: NO
SORT OF BASE TABLE REQUIRED FOR ...: NOTHING
SORT OF RESULT TABLE REQUIRED FOR .: NOTHING
LOCKING MODE ......................: INTENT SHARE
TYPE OF PREFETCH ..................: UNKNOWN/NO PREFETCH
COLUMN FUNCTION EVALUATED AT ......: N/A OR DETERMINED AT EXECUTION
MORE |
PAGE 2
EXPLAIN REPORT 2 FOR FOCEXEC RPT1 RUN ON 06/01/99
QUERY NUMBER IS 1000
PARALLEL ACCESS DEGREE ............: .
PARALLEL ACCESS GROUP .............: .
PARALLEL JOIN DEGREE ..............: .
PARALLEL JOIN GROUP ...............: .
MORE |
PAGE 3
EXPLAIN REPORT 2 FOR FOCEXEC RPT1 RUN ON 06/01/99
QUERY NUMBER IS 1000
2ND ACCESS OF DATA
TABLE NAME ........................: TESTID.QUOT5
TABLE NUMBER ......................: 2
JOIN METHOD .......................: NESTED LOOP JOIN
MULTIPLE INDEX OPERATION SEQUENCE .: 0
INDEX ACCESS TYPE .................: DIRECT INDEX ACCESS
# OF INDEX KEYS USED ..............: 0
INDEX NAME ........................: TESTID.QUOT5IX
INDEX ONLY ACCESS? ................: NO
SORT OF BASE TABLE REQUIRED FOR ...: NOTHING
SORT OF RESULT TABLE REQUIRED FOR .: NOTHING
LOCKING MODE ......................: INTENT SHARE
TYPE OF PREFETCH ..................: UNKNOWN/NO PREFETCH
COLUMN FUNCTION EVALUATED AT ......: N/A OR DETERMINED AT EXECUTION
MORE |
PAGE 4
EXPLAIN REPORT 2 FOR FOCEXEC RPT1 RUN ON 06/01/99
QUERY NUMBER IS 1000
PARALLEL ACCESS DEGREE ............: .
PARALLEL ACCESS GROUP .............: .
PARALLEL JOIN DEGREE ..............: .
PARALLEL JOIN GROUP ...............: .
IF YOUR REQUEST SPONSORED A SEQUENTIAL SCAN OF THE DATA, OR
ONE OR MORE ADDITIONAL SORTS, ESPECIALLY ON THE COMPOSITE
RESULT TABLES, YOU MAY WISH TO REPHRASE THIS REPORT
END OF REPORT |
For information about the EXPLAIN report, consult the DB2
Administration Guide.
xSample EXPLAIN Report for Teradata
Suppose you want to analyze the following request, stored
as SAMP1 FOCEXEC:
JOIN EMP_ID IN EMPINFO TO ALL WHO IN FUNDTRAN
TABLE FILE EMPINFO
WRITE AVE.CURRENT_SALARY ED_HRS BY WHO BY LAST_NAME
IF DEPARTMENT_CD IS MIS
END
The EXPLAIN utility produces a two-page
report:
PAGE 1 EXPLAIN REPORT FOR SAMP1 RUN ON 10/10/99 -_
SQL STATEMENT AS FOLLOWS:
SELECT T2.EID(CHAR( 9), UPPERCASE),T1.LNAME(CHAR( 15),
UPPERCASE), AVG(T1.CURRENT_SALARY)(DECIMAL(15, 2)),
SUM(T1.OJT)(FLOAT) FROM EMPINFO T1,FUNDTRAN T2 WHERE (T2.EID =
T1.EID) AND (T1.DEPARTMENT_CD = ¢MIS¢) GROUP BY T2.EID,T1.LNAME
ORDER BY T2.EID,T1.LNAME 1) First, we lock JANE.T2 for read, and we lock JANE.T1 for read.
2) Next, we do an all-AMPs JOIN step from JANE.T2 by way of an
all-rows scan with no residual conditions, which is joined to
JANE.T2 and JANE.T1 are joined using a merge join, with a join
condition of ("JANE.T2.EID = JANE.T1.EID"). The result goes into
Spool 2, which is built locally on the AMPs. The size |
PAGE 2 EXPLAIN REPORT FOR SAMP1 RUN ON 10/10/99
_
of Spool 2 is estimated to be 4 rows. The estimated time for this
step is 0.10 seconds.
3) We do a SUM step to aggregate from Spool 2 (Last Use) by way of an
all-rows scan. Aggregate Intermediate Results are computed
globally, then placed in Spool 3.
4) We do an all_AMPs RETRIEVE step from Spool 3 (Last Use) by way of
an all-rows scan into Spool 1, which is built locally on the AMPs.
Then we do a SORT to order Spool 1 by the sort key in spool field1.
The size of Spool 1 is estimated to be 2 rows. The estimated time
for this step is 0.07 seconds.
5) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
-> The contents of Spool 1 are sent back to the user as the result of
statement 1. |