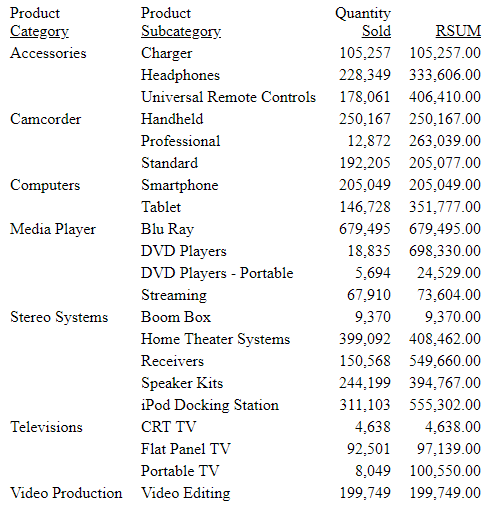
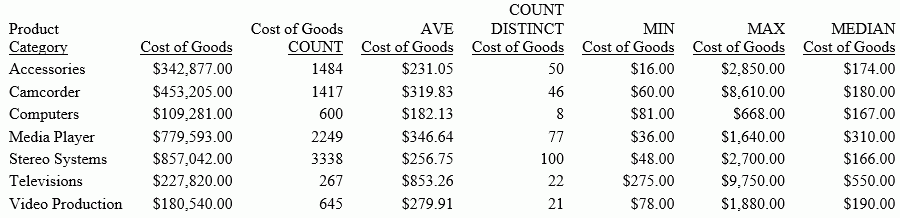
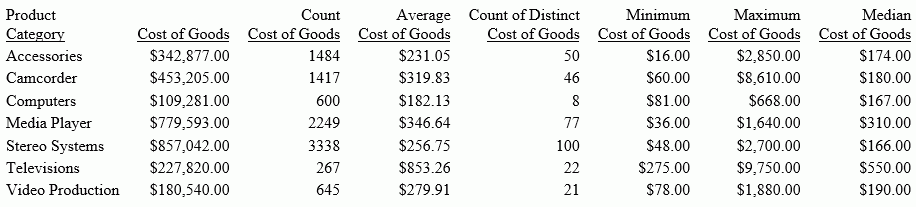
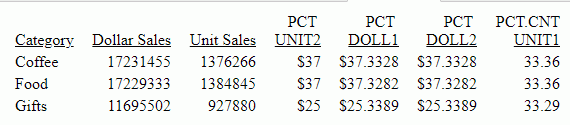
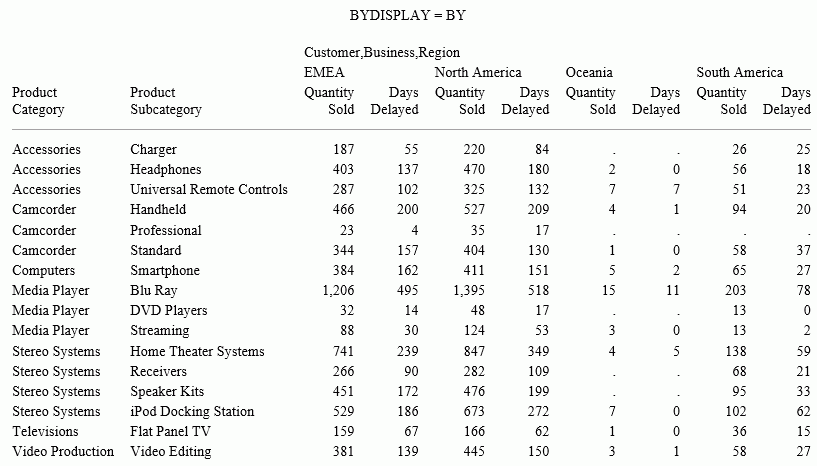
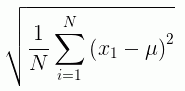COALESCE: Returning the First Non-Missing Value
|
How to: |
Given a list of arguments, COALESCE returns the value of the first argument that is not missing. If all argument values are missing, it returns a missing value if MISSING is ON. Otherwise it returns a default value (zero or blank).
Syntax: How to Return the First Non-Missing Value
COALESCE(arg1, arg2, ...)
where:
- arg1, arg2, ...
-
Any field, expression, or constant. The arguments should all be either numeric or alphanumeric.
Are the input parameters that are tested for missing values.
The output data type is the same as the input data types.
Example: Returning the First Non-Missing Value
This example uses the SALES data source with missing values added. The missing values are added by the following procedure named SALEMISS:
MODIFY FILE SALES
FIXFORM STORE/4 DATE/5 PROD/4
FIXFORM UNIT/3 RETAIL/5 DELIVER/3
FIXFORM OPEN/3 RETURNS/C2 DAMAGED/C2
MATCH STORE
ON NOMATCH REJECT
ON MATCH CONTINUE
MATCH DATE
ON NOMATCH REJECT
ON MATCH CONTINUE
MATCH PROD_CODE
ON NOMATCH INCLUDE
ON MATCH REJECT
DATA
14Z 1017 C13 15 1.99 35 30 6
14Z 1017 C14 18 2.05 30 25 4
14Z 1017 E2 33 0.99 45 40
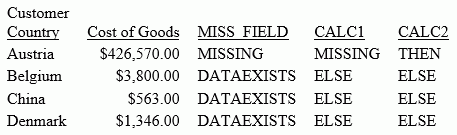
ENDThe following request uses COALESCE to return the first non-missing value:
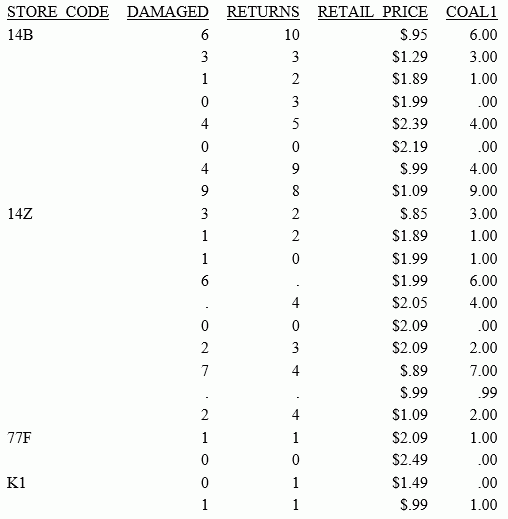
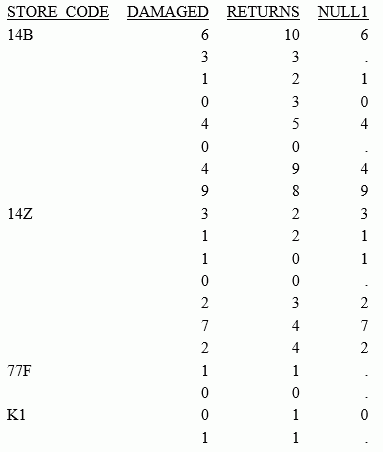
TABLE FILE SALES PRINT DAMAGED RETURNS RETAIL_PRICE COMPUTE COAL1/D12.2 MISSING ON = COALESCE(DAMAGED, RETURNS, RETAIL_PRICE); BY STORE_CODE ON TABLE SET PAGE NOLEAD ON TABLE SET STYLE * GRID=OFF,$ ENDSTYLE END
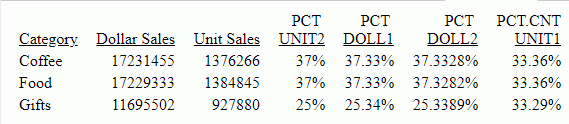
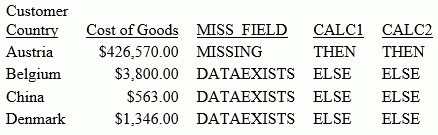
The output is shown in the following image. The value of DAMAGED is returned, if it is not missing. If DAMAGED is missing, the value of RETURNS is returned, if it is not missing. If they are both missing, the value of RETAIL_PRICE is returned.