SQL.Function Syntax for Direct DBMS Function Calls
The SQL adapters support SQL scalar functions in a request. The function must be row based and have a parameter list that consists of a comma-delimited list of columns, constants, or expressions. In order to reference the function in a request, prefix the function name with SQL.
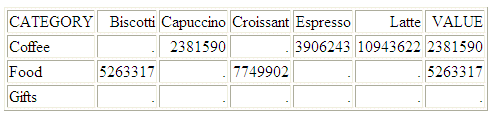
The following example creates the table GGORA, which has columns Biscotti, Capuccino, Croissant, Espresso, and Latte, some of which are null. It then issues a TABLE request that calls the SQL function COALESCE. COALESCE returns the first column in the parameter list that does not contain a null value, if one exists.
The Master File for GGORA is:
FILENAME=GGORA , SUFFIX=SQLORA , IOTYPE=STREAM, $
SEGMENT=GGORA, SEGTYPE=S0, $
FIELDNAME=CATEGORY, ALIAS=CAT, USAGE=A11, ACTUAL=A11,
MISSING=ON, $
FIELDNAME=Biscotti, ALIAS=BIS, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Capuccino, ALIAS=CAP, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Croissant, ALIAS=CROI, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Espresso, ALIAS=ESP, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Latte, ALIAS=LAT, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Mug, ALIAS=MUG, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Scone, ALIAS=SCO, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Thermos, ALIAS=THER, USAGE=I08, ACTUAL=A08,
MISSING=ON, $The following procedure creates the table GGORA based on the FOCUS data source GGSALES (with MISSING=ON attributes added to the DOLLARS field in the Master File):
APP HOLDMETA baseapp APP HOLDDATA baseapp SET HOLDMISS = ON SET HOLDMISS = ON SET ASNAMES = ON TABLE FILE GGSALES SUM DOLLARS AS '' BY CATEGORY ACROSS PRODUCT WHERE PRODUCT NE 'Coffee Grinder' OR 'Coffee Pot' ON TABLE HOLD AS GGFLAT FORMAT ALPHA END FILEDEF GGFLAT DISK baseapp/ggflat.ftm CREATE FILE GGORA MODIFY FILE GGORA FIXFORM FROM GGFLAT DATA ON GGFLAT END
The following TABLE request calls the SQL function COALESCE:
SET TRACEUSER = ON SET TRACESTAMP = OFF SET TRACEON = STMTRACE//CLIENT DEFINE FILE GGORA VALUE/I8 MISSING ON = SQL.COALESCE(Biscotti, Capuccino, Croissant, Espresso, Latte); END TABLE FILE GGORA PRINT Biscotti Capuccino Croissant Espresso Latte VALUE BY CATEGORY ON TABLE SET PAGE NOPAGE END
The trace output shows that the SQL function call was passed to the RDBMS:
SELECT COALESCE(T1."BIS",T1."CAP",T1."CROI",T1."ESP",T1."LAT"), T1."CAT", T1."BIS", T1."CAP", T1."CROI", T1."ESP", T1."LAT" FROM GGORA T1 ORDER BY T1."CAT";
The output is: