Syntax: How to Join Real Fields
The following JOIN syntax requires that the fields you are using to join the files are real fields declared in the Master File. This join may be a simple one based on one field in each file to be joined, or a multi-field join for data sources that support this type of behavior. The following syntax describes the simple and multi-field variations:
JOIN [LEFT_OUTER|RIGHT_OUTER|INNER] hfld1 [AND hfld2 ...] IN hostfile [TAG tag1]
TO [UNIQUE|MULTIPLE]
crfield [AND crfld2 ...] IN crfile [TAG tag2] [AS joinname]
END where:
- JOIN hfld1
- Is the name of a field in the host file containing values shared with a field in the cross-referenced file. This field is called the host field.
- AND hfld2...
- Can be an additional field in the host file, with the caveats
noted below. The phrase beginning with AND is required when specifying
multiple fields.
- For adapters that support multi-field and concatenated joins, and FOCUS or XFOCUS data sources when SET NFOC=ON (the default), you can specify up to 128 fields. See your data adapter documentation for specific information about supported join features for each adapter.
- When you are joining two FOCUS data sources, and SET NFOC=OFF, you can specify up to four alphanumeric fields in the host file that, if concatenated, contain values shared with the cross-referenced file. You may not specify more than one field in the cross-referenced file when the suffix of the file is FOC. For example, assume the cross-referenced file contains a phone number field with an area code-prefix-exchange format. The host file has an area code field, a prefix field, and an exchange field. You can specify these three fields to join them to the phone number field in the cross-referenced file. The JOIN command treats the three fields as one. Other data sources do not have this restriction on the cross-referenced file.
- INNER
- Specifies an inner join. If you do not specify the type of join in the JOIN command, the ALL parameter setting determines the type of join to perform.
- LEFT_OUTER
- Specifies a left outer join. If you do not specify the type
of join in the JOIN command, the ALL parameter setting determines
the type of join to perform.
Note that in a left outer join, host records with a missing cross-referenced instance are included in the report output. To control how tests against missing cross-referenced segment instances are processed, use the SET SHORTPATH command described in Handling a Missing Segment Instance.
- RIGHT_OUTER
- Specifies a right outer join. This option is available for relational data sources that support this type of join. Using this
option requires that you issue the SET SHORTPATH = SQL command.
Note that in a right outer join, cross-referenced records with a missing host instance are included in the report output.
- IN hostfile
- Is the name of the host file.
- TAG tag1
- Is a tag name of up to 66 characters (usually the name of the
Master File), which is used as a unique qualifier for fields and
aliases in the host file.
The tag name for the host file must be the same in all the JOIN commands of a joined structure.
- TO [UNIQUE|MULTIPLE] crfld1
- Is the name of a field in the cross-referenced file containing
values that match those of hfld1 (or of concatenated host
fields). This field is called the cross-referenced field.
Note: Unique returns only one instance and, if there is no matching instance in the cross-referenced file, it supplies default values (blank for alphanumeric fields and zero for numeric fields).
Use the MULTIPLE parameter when crfld1 may have multiple instances in common with one value in hfld1. Note that ALL is a synonym for MULTIPLE, and omitting this parameter entirely is a synonym for UNIQUE. See Unique and Non-Unique Joined Structures for more information.
- AND crfld2...
- Is the name of a field in the cross-referenced file with values
in common with hfld2.
Note: crfld2 may be qualified. This field is only available for data adapters that support multi-field joins.
- IN crfile
- Is the name of the cross-referenced file.
- TAG tag2
- Is a tag name of up to 66 characters (usually the name of the
Master File), which is used as a unique qualifier for fields and
aliases in cross-referenced files. In a recursive join structure,
if no tag name is provided, all field names and aliases are prefixed
with the first four characters of the join name. For related information,
see Usage Notes for Recursive
Joined Structures.
The tag name for the host file must be the same in all the JOIN commands of a joined structure.
- AS joinname
- Is an optional name of up to eight characters that you may assign
to the join structure. You must assign a unique name to a join structure
if:
- You want to ensure that a subsequent JOIN command does not overwrite it.
- You want to clear it selectively later.
- The structure is recursive. See Recursive Joined Structures.
Note: If you do not assign a name to the join structure with the AS phrase, the name is assumed to be blank. A join without a name overwrites an existing join without a name.
- END
- Required when the JOIN command is longer than one line. It terminates the command. It must be on a line by itself.
Example: Creating a Simple Unique Joined Structure
An example of a simple unique join is shown below:
JOIN JOBCODE IN EMPLOYEE TO JOBCODE IN JOBFILE AS JJOIN
Example: Creating an Inner Join
The following procedure creates three FOCUS data sources:
- EMPINFO, which contains the fields EMP_ID, LAST_NAME, FIRST_NAME, and CURR_JOBCODE from the EMPINFO segment of the EMPLOYEE data source.
- JOBINFO, which contains the JOBCODE and JOB_DESC fields from the JOBFILE data source.
- EDINFO, which contains the EMP_ID, COURSE_CODE, and COURSE_NAME fields from the EDUCFILE data source.
The procedure then adds an employee to EMPINFO named Fred Newman who has no matching record in the JOBINFO or EDINFO data sources.
TABLE FILE EMPLOYEE SUM LAST_NAME FIRST_NAME CURR_JOBCODE BY EMP_ID ON TABLE HOLD AS EMPINFO FORMAT FOCUS INDEX EMP_ID CURR_JOBCODE END -RUN TABLE FILE JOBFILE SUM JOB_DESC BY JOBCODE ON TABLE HOLD AS JOBINFO FORMAT FOCUS INDEX JOBCODE END -RUN TABLE FILE EDUCFILE SUM COURSE_CODE COURSE_NAME BY EMP_ID ON TABLE HOLD AS EDINFO FORMAT FOCUS INDEX EMP_ID END -RUN MODIFY FILE EMPINFO FREEFORM EMP_ID LAST_NAME FIRST_NAME CURR_JOBCODE MATCH EMP_ID ON NOMATCH INCLUDE ON MATCH REJECT DATA 111111111, NEWMAN, FRED, C07,$ END
The following request prints the contents of EMPINFO. Note that Fred Newman has been added to the data source:
TABLE FILE EMPINFO PRINT * END
The output is:
EMP_ID LAST_NAME FIRST_NAME CURR_JOBCODE ------ --------- ---------- ------------ 071382660 STEVENS ALFRED A07 112847612 SMITH MARY B14 117593129 JONES DIANE B03 119265415 SMITH RICHARD A01 119329144 BANNING JOHN A17 123764317 IRVING JOAN A15 126724188 ROMANS ANTHONY B04 219984371 MCCOY JOHN B02 326179357 BLACKWOOD ROSEMARIE B04 451123478 MCKNIGHT ROGER B02 543729165 GREENSPAN MARY A07 818692173 CROSS BARBARA A17 111111111 NEWMAN FRED C07
The following JOIN command creates an inner join between the EMPINFO data source and the JOBINFO data source.
JOIN CLEAR * JOIN INNER CURR_JOBCODE IN EMPINFO TO MULTIPLE JOBCODE IN JOBINFO AS J0
Note that the JOIN command specifies a multiple join. In a unique join, the cross-referenced segment is never considered missing, and all records from the host file display on the report output. Default values (blank for alphanumeric fields and zero for numeric fields) display if no actual data exists.
The following request displays fields from the joined structure:
TABLE FILE EMPINFO PRINT LAST_NAME FIRST_NAME JOB_DESC END
Fred Newman is omitted from the report output because his job code does not have a match in the JOBINFO data source:
LAST_NAME FIRST_NAME JOB_DESC --------- ---------- -------- STEVENS ALFRED SECRETARY SMITH MARY FILE QUALITY JONES DIANE PROGRAMMER ANALYST SMITH RICHARD PRODUCTION CLERK BANNING JOHN DEPARTMENT MANAGER IRVING JOAN ASSIST.MANAGER ROMANS ANTHONY SYSTEMS ANALYST MCCOY JOHN PROGRAMMER BLACKWOOD ROSEMARIE SYSTEMS ANALYST MCKNIGHT ROGER PROGRAMMER GREENSPAN MARY SECRETARY CROSS BARBARA DEPARTMENT MANAGER
Example: Creating a Left Outer Join
The following JOIN command creates a left outer join between the EMPINFO data source and the EDINFO data source:
JOIN CLEAR * JOIN LEFT_OUTER EMP_ID IN EMPINFO TO MULTIPLE EMP_ID IN EDINFO AS J1
The following request displays fields from the joined structure:
TABLE FILE EMPINFO PRINT LAST_NAME FIRST_NAME COURSE_NAME END
All employee records display on the report output. The records for those employees with no matching records in the EDINFO data source display the missing data character (.) in the COURSE_NAME column. If the join were unique, blanks would display instead of the missing data character.
LAST_NAME FIRST_NAME COURSE_NAME --------- ---------- ----------- STEVENS ALFRED FILE DESCRPT & MAINT SMITH MARY BASIC REPORT PREP FOR PROG JONES DIANE FOCUS INTERNALS SMITH RICHARD BASIC RPT NON-DP MGRS BANNING JOHN . IRVING JOAN . ROMANS ANTHONY . MCCOY JOHN . BLACKWOOD ROSEMARIE DECISION SUPPORT WORKSHOP MCKNIGHT ROGER FILE DESCRPT & MAINT GREENSPAN MARY . CROSS BARBARA HOST LANGUAGE INTERFACE NEWMAN FRED .
Example: Creating a Right Outer Join
The following requests generate two Db2 tables to join, and then issues a request against the join.
The following request generates the WF_SALES table. The field ID_PRODUCT will be used in the right outer join command.
TABLE FILE WFLITE SUM GROSS_PROFIT_US PRODUCT_CATEGORY PRODUCT_SUBCATEG BY ID_PRODUCT WHERE ID_PRODUCT FROM 2150 TO 4000 ON TABLE HOLD AS WF_SALES FORMAT DB2 END
The following request generates the WF_PROD table. The field ID_PRODUCT will be used in the right outer join command.
TABLE FILE WFLITE SUM PRICE_DOLLARS PRODUCT_CATEGORY PRODUCT_SUBCATEG PRODUCT_NAME BY ID_PRODUCT WHERE ID_PRODUCT FROM 3000 TO 5000 ON TABLE HOLD AS WF_PROD FORMAT DB2 END
The following request issues the SET SHORTPATH=SQL and JOIN commands and displays values from the joined tables:
SET SHORTPATH = SQL JOIN RIGHT_OUTER ID_PRODUCT IN WF_PROD TAG T1 TO ALL ID_PRODUCT IN WF_SALES TAG T2 END TABLE FILE WF_PROD PRINT T1.ID_PRODUCT AS 'Product ID' PRICE_DOLLARS AS Price T2.ID_PRODUCT AS 'Sales ID' GROSS_PROFIT_US BY T1.ID_PRODUCT NOPRINT ON TABLE SET PAGE NOPAGE ON TABLE SET STYLE * GRID=OFF,$ ENDSTYLE END
You can generate a trace that shows the resulting SQL by adding the following commands.
SET TRACEUSER=ON SET TRACESTAMP=OFF SET TRACEOFF=ALL SET TRACEON = STMTRACE//CLIENT
The trace shows that the request was optimized as a right outer join to the RDBMS.
SELECT T1."ID_PRODUCT", T1."PRICE_DOLLARS", T2."ID_PRODUCT", T2."GROSS_PROFIT_US" FROM ( WF_PROD T1 RIGHT OUTER JOIN WF_SALES T2 ON T2."ID_PRODUCT" = T1."ID_PRODUCT" ) ORDER BY T1."ID_PRODUCT";
The output, shown in the following image, has a row for each ID_PRODUCT value that is in the WF_PRODUCT table. The columns from WF_SALES rows that do not have a matching ID_PRODUCT value display the NODATA symbol.
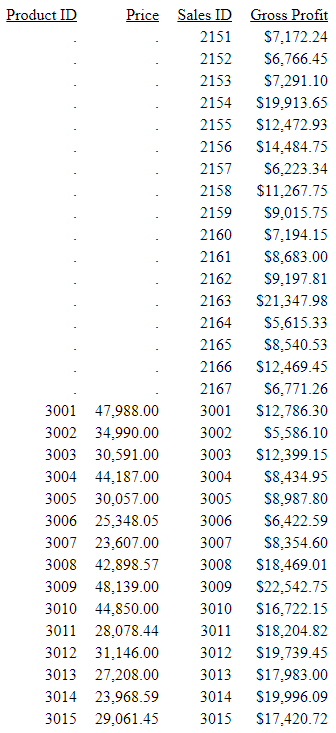
Example: Creating Two Inner Joins With a Multipath Structure
The following JOIN commands create an inner join between the EMPINFO and JOBINFO data sources and an inner join between the EMPINFO and EDINFO data sources:
JOIN CLEAR * JOIN INNER CURR_JOBCODE IN EMPINFO TO MULTIPLE JOBCODE IN JOBINFO AS J0 JOIN INNER EMP_ID IN EMPINFO TO MULTIPLE EMP_ID IN EDINFO AS J1
The structure created by the two joins has two independent paths:
SEG01
01 S1
**************
*EMP_ID **I
*CURR_JOBCODE**I
*LAST_NAME **
*FIRST_NAME **
* **
***************
**************
I
+-----------------+
I I
I SEG01 I SEG01
02 I KM 03 I KM
.............. ..............
:EMP_ID ::K :JOBCODE ::K
:COURSE_CODE :: :JOB_DESC ::
:COURSE_NAME :: : ::
: :: : ::
: :: : ::
:............:: :............::
.............: .............:
JOINED EDINFO JOINED JOBINFOThe following request displays fields from the joined structure:
SET MULTIPATH=SIMPLE TABLE FILE EMPINFO PRINT LAST_NAME FIRST_NAME IN 12 COURSE_NAME JOB_DESC END
With MULTIPATH=SIMPLE, the independent paths create independent joins. All employee records accepted by either join display on the report output. Only Fred Newman (who has no matching record in either of the cross-referenced files) is omitted:
LAST_NAME FIRST_NAME COURSE_NAME JOB_DESC --------- ---------- ----------- -------- STEVENS ALFRED FILE DESCRPT & MAINT SECRETARY SMITH MARY BASIC REPORT PREP FOR PROG FILE QUALITY JONES DIANE FOCUS INTERNALS PROGRAMMER ANALYST SMITH RICHARD BASIC RPT NON-DP MGRS PRODUCTION CLERK BANNING JOHN . DEPARTMENT MANAGER IRVING JOAN . ASSIST.MANAGER ROMANS ANTHONY . SYSTEMS ANALYST MCCOY JOHN . PROGRAMMER BLACKWOOD ROSEMARIE DECISION SUPPORT WORKSHOP SYSTEMS ANALYST MCKNIGHT ROGER FILE DESCRPT & MAINT PROGRAMMER GREENSPAN MARY . SECRETARY CROSS BARBARA HOST LANGUAGE INTERFACE DEPARTMENT MANAGER
With MULTIPATH=COMPOUND, only employees with matching records in both of the cross-referenced files display on the report output:
LAST_NAME FIRST_NAME COURSE_NAME JOB_DESC --------- ---------- ----------- -------- STEVENS ALFRED FILE DESCRPT & MAINT SECRETARY SMITH MARY BASIC REPORT PREP FOR PROG FILE QUALITY JONES DIANE FOCUS INTERNALS PROGRAMMER ANALYST SMITH RICHARD BASIC RPT NON-DP MGRS PRODUCTION CLERK BLACKWOOD ROSEMARIE DECISION SUPPORT WORKSHOP SYSTEMS ANALYST MCKNIGHT ROGER FILE DESCRPT & MAINT PROGRAMMER CROSS BARBARA HOST LANGUAGE INTERFACE DEPARTMENT MANAGER