To access an IMS database from FOCUS, you must describe
IMS entities in FOCUS terms. Creating FOCUS Descriptions, explains specific syntax requirements,
and Sample File Descriptions,
includes sample descriptions. This section presents an overview
of the mapping concepts.
xDescribing the PSB: The FOCPSB
A FOCPSB contains attributes (keyword=value pairs) that
identify the PCBs in a PSB and associate each PCB with the name
of a Master File. Describing the Database: The Master File, and Creating FOCUS Descriptions, describes
the Master File in detail.
You associate a FOCPSB with the PSB it describes by giving them
both the same name. FOCPSBs are stored as members of a partitioned
data set. The member name for a FOCPSB must be identical to the
name of the corresponding IMS PSB.
Note: FOCPSBs created in prior FOCUS Releases may consist
of fixed format records with no attribute keywords. Release Dependent Adapter Features, discusses fixed format FOCPSBs. While this earlier
format is still supported, the comma-delimited format is preferable.
In the FOCPSB, you must provide the following
for each PCB:
-
The PCBNAME. This value is the name of the corresponding
Master File. A blank indicates either an I/O PCB (see Overview of IMS Control Blocks)
or a PCB that you do not want to access. You can include the same
PCB multiple times in the PSB. Each such duplicate should use the
same Master File name.
-
The PCBTYPE. This value identifies the type of PCB. Acceptable
values are DB for database PCBs, TERM for I/O
PCBs, and SKIP for PCBs you will not access.
Important: SKIP is a reserved word for the FOCPSB. Never use
SKIP as a Master File name.
Creating FOCUS Descriptions,
discusses additional attributes used for partitioning and concatenating
PCBs.
The following diagram illustrates the correspondence between
an IMS PSB and an equivalent FOCPSB:
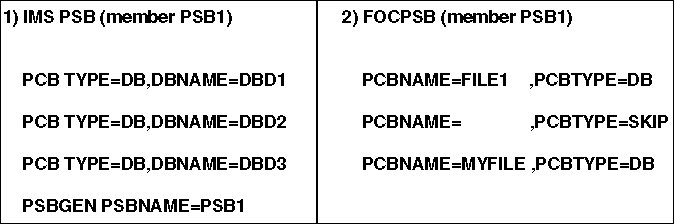
- Is an IMS PSB named PSB1. It contains three database PCBs.
- Is the corresponding FOCPSB, member PSB1 in the FOCPSB data
set. This FOCPSB ignores the second PCB in the PSB (PCBTYPE=SKIP).
It can issue a report request through the first PCB with the syntax
TABLE FILE FILE1 (against Master File FILE1), and through the third
PCB with the syntax TABLE FILE MYFILE (against Master File MYFILE).
xDescribing the Database: The Master File
With the Adapter for IMS/DB, a Master File is not necessarily
a complete description of the database, but rather is a description
as seen through a specific PCB. If the PCB is not sensitive to a
segment listed in the DBD, the Master File cannot include that segment.
Therefore, in order to create a Master File for the PCB, you must
combine information from the DBD and the PCB.
You do not have to describe every segment from the PCB in the
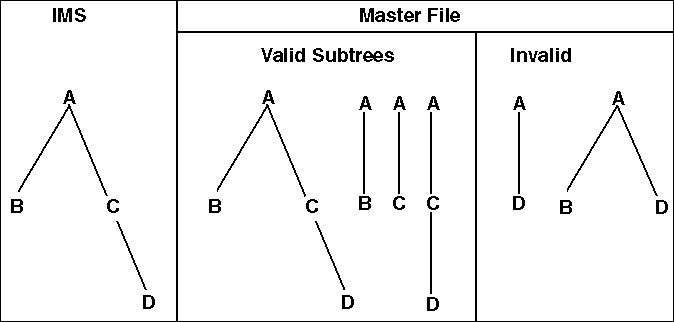
Master File. However, the portion of the hierarchy you describe
must be a subtree starting from the root. In a subtree, when
you include a child segment, you must also include its parent.
The following diagram illustrates the
concept of a subtree:
This section illustrates where each element that goes into the
Master File comes from in the IMS schema. Creating FOCUS Descriptions,
discusses Master File syntax in detail.
In the following discussion, you will
notice the following:
- An IMS field is equivalent to a field in the Master File.
- An IMS segment corresponds to a segment in the Master File.
- IMS fields that are composed of multiple elementary fields can
be represented as GROUP fields in the Master File.
- IMS segments that have multiple definitions can be represented
in the Master File with the RECTYPE attribute.
- IMS variable length segments and segments with repeating fields
can be represented with an OCCURS segment in the Master File.
Note: Master Files should maintain the hierarchy of the
structure as defined in the IMS DBD. The structure is traversed
from top to bottom, left to right. Failure to maintain the hierarchy
can produce unpredictable results.
x
Identifying the IMS Database
Each Master File corresponds
to one PCB and each PCB accesses one DBD. The FILENAME value in
the Master File can be any one- to eight-character name. However,
for consistency and documentation purposes, the examples in this
manual use the DBD name as the FILENAME value in the Master File:

- Is an IMS PSB containing a PCB for DBD1.
- Is the FILE record of the Master File for that PCB. The FILENAME
attribute has the value DBD1.
x
Describing IMS Segments to FOCUS
A Master File contains segment records to describe the
hierarchy of segments. These correspond to the SENSEG records in
the PCB.
The Segment record in the Master File
contains the following information:
-
The PARENT attribute. Its value is the name of the
parent of the segment from the SENSEG record in the PCB. The only
difference is in the root segment. The PCB specifies PARENT=0 for
the root segment or omits the PARENT parameter. In the Master File,
you can specify the PARENT attribute of the root segment as PARENT=, or
you can omit it.
The following diagram illustrates how
to create a Segment record in the Master File:

- Is an IMS PSB that has a PCB with two sensitive segments,
SEG1 and SEG2. SEG1 is the root segment (PARENT=0) and SEG2 is a
child of SEG1.
- Is the IMS DBD that the PCB is viewing. It indicates that the
key for SEG1 is unique. There is no key specified for SEG2. FLD2
is a search field but not a sequence field.
- Is the Master File corresponding to the PCB.
SEG1 is the root.
Therefore the PARENT attribute can be omitted. Since the segment
is data sensitive and the sequence field is unique, SEGTYPE=S2.
SEG2
is a child of SEG1. Therefore its PARENT=SEG1. Since it is not key
sensitive and has no key field, SEGTYPE=S0.
x
Describing IMS Fields to FOCUS
To describe data fields in the Master File, you must
also consider information from both the PCB and the DBD.
If the PCB you are describing contains SENFLD records for a segment,
the Master File can view only the fields explicitly named in those
SENFLD records.
However, if the PCB does not contain any SENFLD records for a
segment, you can describe the entire segment in the Master File.
You can get information about sequence and search fields from the
DBD. To describe other fields you may have to refer to the COBOL
FD description for the segment.
For each field you describe in the Master
File you must include the following:
-
The FOCUS FIELDNAME. This can be any name that complies
with FOCUS field naming conventions, as described in Creating FOCUS Descriptions.
-
The ALIAS. The adapter uses the alias to distinguish
between IMS sequence fields, IMS search fields, key fields from
the root of an HDAM database, and other fields. These designations
help the adapter produce optimized SSAs, as described in Reporting Efficiencies.
If the field is not listed in the DBD, the
alias can be any name that complies with FOCUS naming conventions.
If the field is listed in the DBD (it
is a sequence or search field), the alias value takes the form IMSname.suffix.
IMSname is the field name specified in the DBD. The following table
lists suffix values:
|
Suffix
|
Description
|
|---|
|
KEY
|
IMS key field
|
|
IMS
|
IMS search field
|
|
HKY
|
Key of root of an HDAM database
|
-
The USAGE format. The USAGE format is the FOCUS display
format for the field, as described in the Describing Data manual.
-
The ACTUAL format. The ACTUAL format describes how the
data is stored in the IMS database. The DBD specifies this information
with the TYPE and BYTES parameters in each FIELD record. See Creating FOCUS Descriptions,
for a discussion of ACTUAL formats.
The DBD indicates the length of each segment and the length and
starting position of each listed field within a segment. The Master
File need not describe all fields from a segment, but it must include
filler fields that occupy the same space as any field it omits. You
can use the BYTES and START parameters from the DBD to determine
how the fields in the segment are arranged. If you want to describe
two fields that are separated by data that you do not need, you
must include a field in the Master File occupying the unneeded space in
order to avoid a gap.
The following diagram illustrates FIELDNAME
and ALIAS values in a Master File for a HIDAM database:
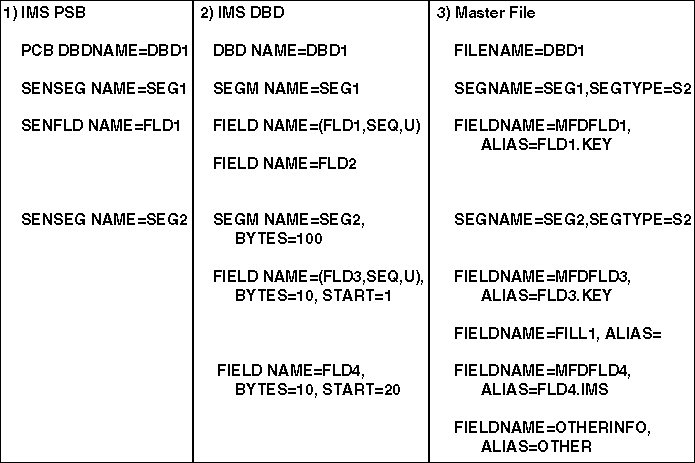
- Is an IMS PSB. SEG1 has a SENFLD record for FLD1 limiting
the view to that field alone. SEG2 has no SENFLD records. Therefore,
the entire segment is available.
- Is the IMS DBD that the PCB is viewing. SEG1 has two fields
listed, but the PCB is sensitive only to the first. SEG2 has two
fields listed, but they do not describe the entire segment.
- Is the corresponding Master File. In SEG1, only FLD1 is available
because of the SENFLD record in the PCB. The FIELDNAME can be any
convenient name. Since this field is the key for the segment, the
alias value is the name from the IMS DBD with the suffix value KEY
appended: ALIAS=FLD1.KEY.
In SEG2, the whole segment is available
since the PCB has no SENFLD records for the segment. FLD3 is the
key field. Therefore its alias value is FLD3.KEY. FLD4 is a non-key
search field; its alias value is FLD4.IMS. No other fields are described
in the PCB, but the Master File defines two more fields from the
segment. Their alias values are arbitrary names with no suffix values.
Notice the filler field between FLD3 and FLD4.
IMS key fields, secondary index fields, and search fields can
consist of multiple elementary fields. In the Master File, you can
break the IMS field into component parts (field redefinition) using
a GROUP field.
The following diagram illustrates a group
key:

- Is a DBD. The field G is 8 bytes long and is type character.
- Is the Master File. It defines the group as an 8-byte alphanumeric
field. It then breaks this field down into two 4-byte alphanumeric
fields.
- Is a FOCUS session or FOCEXEC that uses the group field and
its high-order component in screening tests. A slash must separate
components of the group (see Creating FOCUS Descriptions).
x
Describing IMS Segments That Have Multiple Definitions to FOCUS
An IMS segment can have multiple
definitions. For example, a segment may contain either shipment
or order information, depending on the value of one of its fields.
If the field that identifies the type of segment is at the same
position in each redefinition, you can use the RECTYPE attribute
to define the different segment types in the Master File:
- First define the non-changing portion of the segment as
usual. Include a filler field for the part that will be redefined.
The field that identifies the different types must be in the redefined
portion.
- Next, describe each redefined portion as a segment whose parent
is the non-changing segment. Do not define a SEGTYPE for these children.
Describe the field that identifies the segment type as FIELDNAME=RECTYPE
in the Master File. The alias for the RECTYPE field is the value
that identifies the type of data in the segment (in this example,
either ALIAS=S, for a shipment, or ALIAS=O, for an order).
Include
a filler field in each redefinition to occupy the fields that are
in the non-changing segment.
The following diagram illustrates segment
redefinition in the Master File:
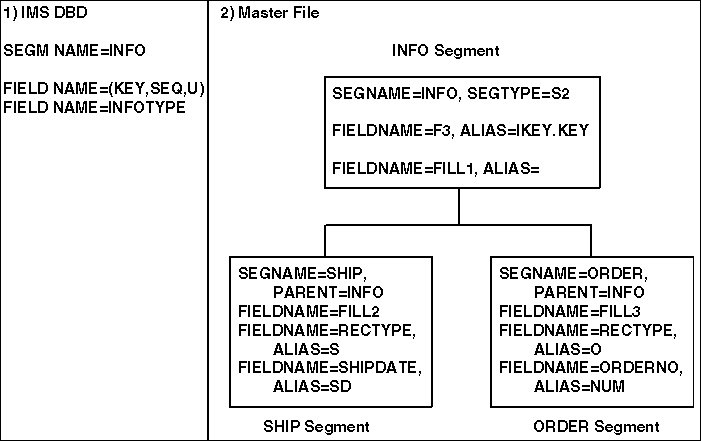
- Is a segment named INFO that has two definitions, one for
shipment information and one for order information. Field INFOTYPE
contains the value S in those segment instances that contain shipment
data. It contains the value O in those segment instances that represent
order information.
- Is the portion of the Master File that represents the IMS segment.
It uses three segments to describe the one IMS segment.
The parent
segment, named INFO to match the IMS segment name, contains the key
field since the key is not in the redefined portion. There is also
a filler field to account for the redefined portion of the segment.
Each
child segment has INFO as its parent and a null SEGTYPE value. In
each child, the field that corresponds to INFOTYPE from the DBD
has FIELDNAME=RECTYPE. The ALIAS value for the RECTYPE field in
each child segment is the INFOTYPE value that identifies that type
of segment, S for the SHIP segment type and O for the ORDER segment
type. (Each segment type also has a filler to occupy the positions
of the fields that are described in the parent segment, and each
segment type describes additional fields that it needs for either
order or shipment data.)
Creating FOCUS Descriptions, explains how to describe a segment type
that allows multiple RECTYPE values.
x
Supporting Logical Segment Types
A segment defined as type RECTYPE is considered a logical
segment type since it is possible that it will not exist for all
records in a file.
The Adapter for IMS allows logical segment
types to have child segments. In the following example, the RECTYPE
B segment has a real segment described as a child. This child segment
only exists when the RECTYPE field of the record specifies a B:
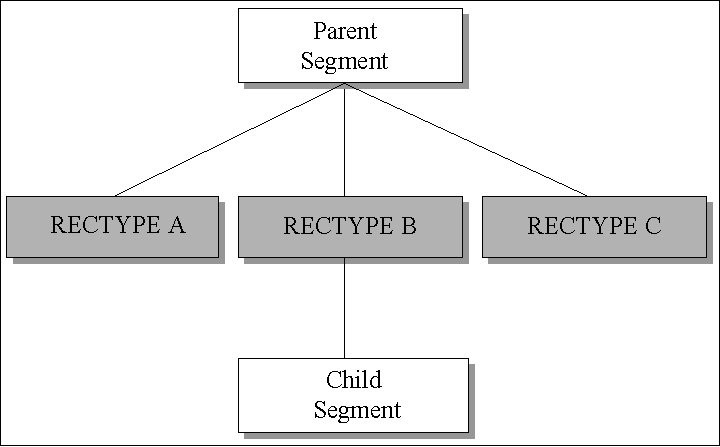
The previous example illustrates a child
segment that only exists when there is an instance of RECTYPE B.
The following example shows a child segment that exists for all record
types. The child segment will be accompanied by data that depends
on the record type:
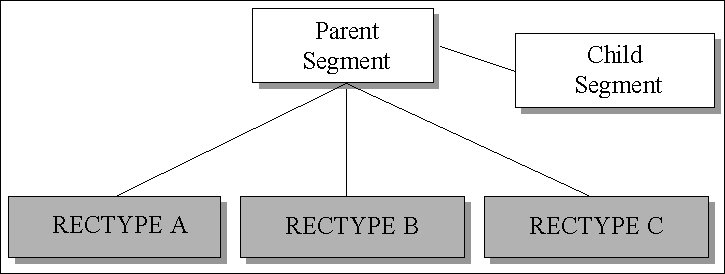
Through the use of the record type, the adapter activates only
the necessary paths. This eliminates unnecessary, independent paths
from the hierarchy traversal. This efficient data access results
in improved adapter performance.
x
Describing Variable Length Segments to FOCUS
In an IMS database, segments can have repeating fields
or repeating groups of fields. The number of repetitions may be
fixed, may depend on the value of a field from the parent segment
or from the non-repeating portion of the variable segment, or may have
to be calculated from the segment length.
In the Master File, you describe a segment
with repeating fields by defining each repeating field (or group)
as a separate segment whose parent is the non-repeating portion of
the segment. The child segment definition has no SEGTYPE, but it
includes the OCCURS attribute to specify how many times the field
repeats. The following table lists permissible values:
|
OCCURS=
|
Description
|
|---|
n |
Is the number of times the field repeats
in the segment.
|
fieldname |
Is the name of a field whose value indicates
the number of times the field repeats in the segment.
|
VARIABLE |
Indicates that the number of repetitions
must be computed from the length of the segment. In this case, the
segment must contain a counter field as its first field. The alias
of the counter field in the Master File must be IMSname.CNT.
|
If the repeating field is not at the end of the segment, you
must also identify its position within the segment (see Creating FOCUS Descriptions).
The following diagram illustrates an
OCCURS segment in the Master File. Creating FOCUS Descriptions includes examples for each value of the OCCURS
attribute.
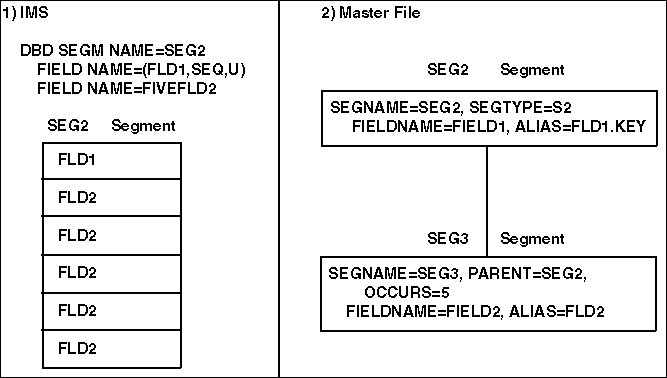
- Is an IMS segment with one key field and one repeating field.
- Are the equivalent segments in the Master File. Segment SEG2
contains the non-repeating portion of the IMS SEG2 segment. Segment
SEG3 contains the repeating field. It specifies OCCURS=5. SEG3 has
no SEGTYPE value.
x
Describing a Secondary Index to FOCUS
Using IMS secondary indexes, you can retrieve records
in order of a field other than the key field. (A secondary index
is itself a database with its own DBD.) The DBD for a database that
uses a secondary index includes an XDFLD statement that assigns
a field name to the index.
If a PCB includes the parameter PROCSEQ=indexDBDname, the named
index is used as the main entry point into the database.
One Master File can describe the primary index and multiple secondary
indexes. You must also include a record for each secondary index
in the FOCPSB. Then, when you issue a FOCUS report request, the
adapter inspects all key fields and secondary indexes to select the
optimal retrieval path based on the selection criteria in the request.
In prior releases, each secondary index required a separate Master
File, and the application programmer had to decide which Master
File to use with each request. Release Dependent Adapter Features, describes that technique.
In order to access a database through a secondary index, the
IMS PSB must contain a PCB that defines the index as the main entry
point into the database. The PCB does this by identifying the DBD
for the index in the PROCSEQ parameter (recall that a secondary
index is, itself, an IMS database). The adapter requires the IMS
PSB to also include a PCB for the normal entry point into the database.
This PCB does not include a PROCSEQ parameter.
The FOCPSB has a one-to-one correspondence with the PSB. The
FOCPSB entry that corresponds to the normal entry point into the
database supplies the name of the Master File. Each FOCPSB entry
that corresponds to a secondary index PCB supplies the name of the
index from the XDFLD record of the DBD.
The following diagram illustrates an
IMS PSB and its corresponding FOCPSB:

- Is the IMS DBD for the PATDB01 database. The LCHILD record
for the secondary index gives the name of the index DBD. The corresponding
XDFLD record names the index.
- Is an IMS PSB with two PCBs for PATDB01. The first PCB does
not include a PROCSEQ parameter. Therefore, it uses the normal entry
point into the database. The second PCB includes the parameter PROCSEQ=PATDBIX1.
Therefore, a secondary index is the main entry point into the database
through this PCB, and the PATDBIX1 DBD describes it.
- Is the FOCPSB that describes the IMS PSB. The entry corresponding
to the first PCB supplies the Master File name, PCBNAME=PATINFO.
The entry corresponding to the PCB for the secondary index provides
the index name, PCBNAME=IXNAME.
To define the secondary index in the
Master File, you must do the following:
- Describe each field that participates in a secondary index
as a key or search field, with the suffix .KEY, .HKY, or .IMS.
- Describe the rest of the IMS segment with FOCUS field definitions
or filler fields.
- At the end of the root segment, define each secondary
index as a group field:
- The ALIAS of the group field must
have the suffix .SKY (Secondary index key) appended to the index
name from the XDFLD record in the DBD. That is, ALIAS=XDFLDname.SKY,
where XDFLDname is the value of the NAME parameter in the XDFLD
record of the DBD.
- The fields that comprise the secondary index must be subordinate
fields in the group. You can find the names of these fields in the
SRCH parameter of the XDFLD record in the DBD. You described these
fields previously in the Master File as sequence or search fields.
When you now describe them as subordinate fields, you must assign
them a new FIELDNAME not already used in the Master File. Their ALIAS
values must be the FIELDNAME values you previously gave them.
The following diagram illustrates how
to describe a secondary index in the Master File:
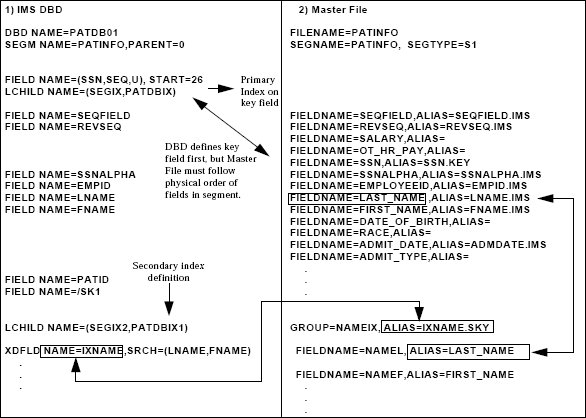
- Is the IMS DBD. It describes one secondary index. The XDFLD
record assigns the name IXNAME to the index. The SRCH parameter
indicates that the IXNAME index searches on the fields LNAME and
FNAME.
- Is the corresponding Master File. In the GROUP record at the
end of the Master File, the ALIAS value is the name of the index
from the DBD with the suffix SKY appended.
The subordinate fields
in the group were previously assigned field names in the Master
File. The ALIAS value for each subordinate field in the group definition
is the previously-assigned FIELDNAME. The FIELDNAME in the subordinate
field entry is a new name.
The adapter now has the information necessary for determining
the best access path for a particular request. Consider the following
request:
TABLE FILE PATINFO
PRINT LAST_NAME FIRST_NAME SALARY ADMIT_DATE
IF LAST_NAME IS 'SMITH'
END
Since the field referenced in the IF condition is the high-order
part of an index, the adapter generates a qualified SSA to retrieve
data using the PCB that permits access through the index. Reporting Efficiencies,
shows examples of such SSAs.
Sample File Descriptions illustrates
three secondary index definitions for this database.