In this section: Reference: |
When you join two data sources, some records in one of the files may lack corresponding records in the other file. When a report omits records that are not in both files, the join is called an inner join. When a report displays all matching records, plus all records from the host file that lack corresponding cross-referenced records, the join is called a left outer join.
The SET ALL command globally determines how all joins are implemented. If the SET ALL=ON command is issued, all joins are treated as outer joins. With SET ALL=OFF, the default, all joins are treated as inner joins.
Each JOIN command can specify explicitly which type of join to perform, locally overruling the global setting. This syntax is supported for FOCUS, XFOCUS, Relational, VSAM, IMS, and Adabas. If you do not specify the type of join in the JOIN command, the ALL parameter setting determines the type of join to perform.
You can also join data sources using one of two techniques for determining how to match records from the separate data sources. The first technique is known as an equijoin and the second is known as a conditional join. When deciding which of the two join techniques to use, it is important to know that when there is an equality condition between two data sources, it is more efficient to use an equijoin rather than a conditional join.
You can use an equijoin structure when you are joining two or more data sources that have two fields, one in each data source, with formats (character, numeric, or date) and values in common. Joining a product code field in a sales data source (the host file) to the product code field in a product data source (the cross-referenced file) is an example of an equijoin. For more information on using equijoins, see Creating an Equijoin.
The conditional join uses WHERE-based syntax to specify joins based on WHERE criteria, not just on equality between fields. Additionally, the host and cross-referenced join fields do not have to contain matching formats. Suppose you have a data source that lists employees by their ID number (the host file), and another data source that lists training courses and the employees who attended those courses (the cross-referenced file). Using a conditional join, you could join an employee ID in the host file to an employee ID in the cross-referenced file to determine which employees took training courses in a given date range (the WHERE condition). For more information on conditional joins, see Using a Conditional Join.
Joins can also be unique or non-unique. A unique, or one-to-one, join structure matches one value in the host data source to one value in the cross-referenced data source. Joining an employee ID in an employee data source to an employee ID in a salary data source is an example of a unique equijoin structure.
A non-unique, or one-to-many, join structure matches one value in the host data source to multiple values in the cross-referenced field. Joining an employee ID in a company's employee data source to an employee ID in a data source that lists all the training classes offered by that company results in a listing of all courses taken by each employee, or a joining of the one instance of each ID in the host file to the multiple instances of that ID in the cross-referenced file.
For more information on unique and non-unique joins, see Unique and Non-Unique Joined Structures.
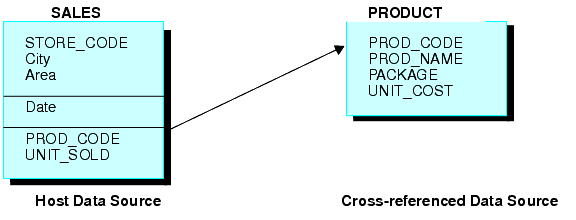
Consider the SALES and PRODUCT data sources. Each store record in SALES may contain many instances of the PROD_CODE field. It would be redundant to store the associated product information with each instance of the product code. Instead, PROD_CODE in the SALES data source is joined to PROD_CODE in the PRODUCT data source. PRODUCT contains a single instance of each product code and related product information, thus saving space and making it easier to maintain product information. The joined structure, which is an example of an equijoin, is illustrated below:
The use of data sources as host files and cross-referenced files in joined structures depends on the types of data sources you are joining:
SET PASS = pswd1 IN file1, pswd2 IN file2
Individual DBA information remains in effect for each file in the JOIN. For details about the DBAFILE attribute, see the Describing Data manual.
How to: |
In a unique joined structure, one value in the host field corresponds to one value in the cross-referenced field. In a non-unique joined structure, one value in the host field corresponds to multiple values in the cross-referenced field.
The ALL parameter in a JOIN command indicates that the joined structure is non-unique.
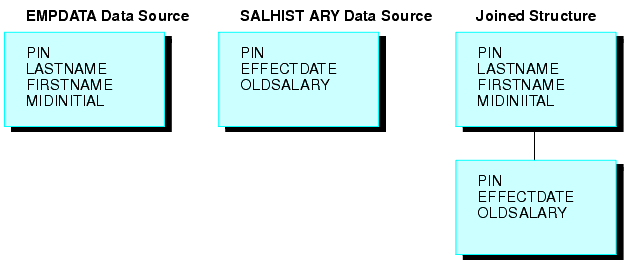
The following example illustrates a unique joined structure. Two FOCUS data sources are joined together: an EMPDATA data source and a SALHIST data source. Both data sources are organized by PIN, and they are joined on a PIN field in the root segments of both files. Each PIN has one segment instance in the EMPDATA data source, and one instance in the SALHIST data source. To join these two data sources, issue this JOIN command:
JOIN PIN IN EMPDATA TO PIN IN SALHIST
If a field value in the host file can appear in many segment instances in the cross-referenced file, then you should include the ALL phrase in the JOIN syntax. This structure is called a non-unique joined structure.
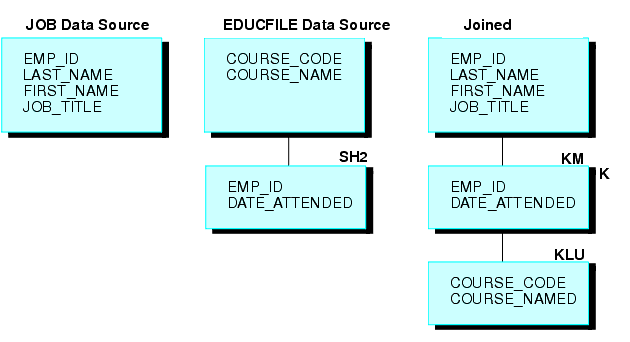
For example, assume that two FOCUS data sources are joined together: the JOB data source and an EDUCFILE data source which records employee attendance at in-house courses. The joined structure is shown in the following diagram.
The JOB data source is organized by employee, but the EDUCFILE data source is organized by course. The data sources are joined on the EMP_ID field. Since an employee has one position but can attend several courses, the employee has one segment instance in the JOB data source but can have as many instances in the EDUCFILE data source as courses attended.
To join these two data sources, issue the following JOIN command, using the ALL phrase:
JOIN EMP_ID IN JOB TO ALL EMP_ID IN EDUCFILE
If a parent segment has two or more unique child segments that each have multiple children, the report may incorrectly display a missing value. The remainder of the child values may then be misaligned in the report. These misaligned values are called lagging values. The JOINOPT parameter ensures proper alignment of your output by correcting for lagging values.
SET JOINOPT={NEW|OLD|GNTINT}where:
Specifies that segments be retrieved from left to right and from top to bottom, which results in the display of all data for each record, properly aligned. Missing values only occur when they exist in the data.
Specifies that segments be retrieved as unique segments, which results in the display of missing data in a report where all records should have values. This might cause lagging values. OLD is the default value.
Specifies that segments be retrieved from left to right and from top to bottom, which results in the display of all data for each record, properly aligned. Missing values only occur when they exist in the data.
Note: The value GNTINT both corrects for lagging values and enables joins between different numeric data types, as described in Joining Fields With Different Numeric Data Types.
This example is a hypothetical scenario in which you would use the JOINOPT parameter to correct for lagging values. Lagging values display missing data such that each value appears off by one line.
A single-segment host file (ROUTES) is joined to two files (ORIGIN and DEST), each having two segments. The files are joined to produce a report that shows each train number, along with the city that corresponds to each station.
The following request prints the city of origin (OR_CITY) and the destination city (DE_CITY). Note that missing data is generated, causing the data for stations and corresponding cities to lag, or be off by one line.
TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
The output is:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL . 202 BOS BOSTON BLT ATLANTA 303 DET DETROIT BOS BALTIMORE 404 CHI CHICAGO DET BOSTON 505 BOS BOSTON STL DETROIT 505 BOS . STL ST. LOUIS
Issuing SET JOINOPT=NEW enables segments to be retrieved in the expected order (from left to right and from top to bottom), without missing data.
SET JOINOPT=NEW TABLE FILE ROUTES PRINT TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY END
The correct report has only 5 lines instead of 6, and the station and city data is properly aligned. The output is:
TRAIN_NUM OR_STATION OR_CITY DE_STATION DE_CITY --------- ---------- ------- ---------- ------- 101 NYC NEW YORK ATL ATLANTA 202 BOS BOSTON BLT BALTIMORE 303 DET DETROIT BOS BOSTON 404 CHI CHICAGO DET DETROIT 505 BOS BOSTON STL ST. LOUIS
Reference: |
You can join a FOCUS or IMS data source to itself, creating a recursive structure. In the most common type of recursive structure, a parent segment is joined to a descendant segment, so that the parent becomes the child of the descendant. This technique (useful for storing bills of materials, for example) enables you to report from data sources as if they have more segment levels than is actually the case.
For example, the GENERIC data source shown below consists of Segments A and B.
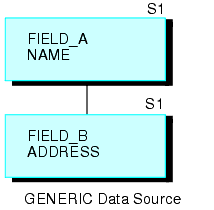
The following request creates a recursive structure:
JOIN FIELD_B IN GENERIC TAG G1 TO FIELD_A IN GENERIC TAG G2 AS RECURSIV
This results in the joined structure (shown below).
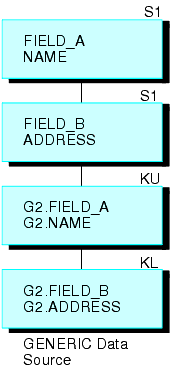
Note that the two segments are repeated on the bottom. To refer to the fields in the repeated segments (other than the field to which you are joining), prefix the tag names to the field names and aliases and separate them with a period, or append the first four characters of the JOIN name to the field names and aliases. In the above example, the JOIN name is RECURSIV. You should refer to FIELD_B in the bottom segment as G2.FIELD_B (or RECUFIELD_B). For related information, see Usage Notes for Recursive Joined Structures.
This example explains how to use recursive joins to store and report on a bill of materials. Suppose you are designing a data source called AIRCRAFT, that contains the bill of materials for a company's aircraft. The data source records data on three levels of airplane parts:
The data source must record each part, the part description, and the smaller parts composing the part. Some parts, such as nuts and bolts, are common throughout the aircraft. If you design a three-segment structure, one segment for each level of parts, descriptions of common parts are repeated in every place they are used.
To reduce this repetition, design a data source that has only two segments (shown in the following diagram). The top segment describes each part of the aircraft, large and small. The bottom segment lists the component parts without descriptions.
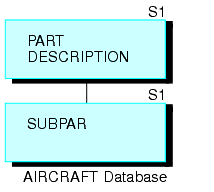
Every part (except for the largest divisions) appears in both the top segment, where it is described, and in the bottom segment, where it is listed as one of the components of a larger part. (The smallest parts, such as nuts and bolts, appear in the top segment without an instance of a child in the bottom segment.) Note that each part, no matter how often it is used in the aircraft, is described only once.
If you join the bottom segment to the top segment, the descriptions of component parts in the bottom segment can be retrieved. The first-level major divisions can also be related to third-level small parts, going from the first level to the second level to the third level. Thus, the structure behaves as a three-level data source, although it is actually a more efficient two-level source.
For example, CABIN is a first-level division appearing in the top segment. It lists SEATS as a component in the bottom segment. SEATS also appears in the top segment. It lists BOLTS as a component in the bottom segment. If you join the bottom segment to the top segment, you can go from CABIN to SEATS and from SEATS to BOLTS.

Join the bottom segment to the top segment with this JOIN command:
JOIN SUBPART IN AIRCRAFT TO PART IN AIRCRAFT AS SUB
This creates the following recursive structure.

You can then produce a report on all three levels of data with this TABLE command (the field SUBDESCRIPT describes the contents of the field SUBPART):
TABLE FILE AIRCRAFT PRINT SUBPART BY PART BY SUBPART BY SUBDESCRIPT END
| Information Builders |