Features Added in FOCUS 7.7.03
The following features were added as of FOCUS 7.7.03
xDEFINE FUNCTION Optimization
The DEFINE FUNCTION syntax can be sent directly to an
SQL engine as long as all expressions used in the function can be
optimized.
Note that in order for DEFINE FUNCTION syntax to be optimized,
the types and lengths of the arguments used to call the DEFINE FUNCTION
must exactly match the types and lengths of the DEFINE FUNCTION
parameters.
For example, the Oracle data source EMPINFO
has columns LAST_NAME (alias LN) and FIRST_NAME (alias FN). The
following DEFINE FUNCTION takes two arguments, N1 and N2, and sets
a flag, which it returns as EMPNAME. EMPNAME has the value 1 if
N1 is Smith and N2 is Richard:
DEFINE FUNCTION EMPNAME (N1/A15, N2/A10)
DEF1/I1 = IF N1 EQ 'SMITH' THEN 1 ELSE IF N1 EQ 'JONES' THEN 2
ELSE IF N1 EQ 'CARTER' THEN 3 ELSE 0;
DEF2/I1 = IF N2 EQ 'RICHARD' THEN 1 ELSE IF N2 EQ 'BARBARA' THEN 2
ELSE 0;
EMPNAME/I1 = IF DEF1 EQ 1 AND DEF2 EQ 1 THEN 1 ELSE 0;
ENDThe following request uses the result
of the DEFINE FUNCTION in an aggregation command. Note that the
format of LAST_NAME exactly matches the format defined for N1, and
the format of FIRST_NAME exactly matches the format defined for
N2:
SET TRACEUSER = ON
SET TRACESTAMP = OFF
SET TRACEON = STMTRACE//CLIENT
ENGINE SQLORA SET OPTIFTHENELSE ON
DEFINE FILE EMPINFO
DEF3/I1 = EMPNAME(LAST_NAME, FIRST_NAME);
END
TABLE FILE EMPINFO
SUM MAX.LAST_NAME IF DEF3 EQ 1
The trace output shows that the IF-THEN-ELSE
expressions from the DEFINE FUNCTION are translated to an SQL expression
in the WHERE predicate of the SELECT statement passed to the RDBMS:
AGGREGATION DONE ...
SELECT
MAX(T1."LN")
FROM
EMPINFO T1
WHERE
((CASE WHEN (((CASE (T1."LN") WHEN 'SMITH' THEN 1 WHEN 'JONES'
THEN 2 WHEN 'CARTER' THEN 3 ELSE 0 END) = 1) AND ((CASE
(T1."FN") WHEN 'RICHARD' THEN 1 WHEN 'BARBARA' THEN 2 ELSE 0
END) = 1)) THEN 1 ELSE 0 END) = 1);
xSQL.Function Syntax for Direct DBMS Function Calls
The SQL adapters support SQL scalar functions in a request.
The function must be row based and have a parameter list that consists
of a comma-delimited list of columns, constants, or expressions.
In order to reference the function in a request, prefix the function
name with SQL.
The following example creates the table GGORA, which has columns
Biscotti, Capuccino, Croissant, Espresso, and Latte, some of which
are null. It then issues a TABLE request that calls the SQL function
COALESCE. COALESCE returns the first column in the parameter list
that does not contain a null value, if one exists.
The Master File for GGORA is:
FILENAME=GGORA , SUFFIX=SQLORA , IOTYPE=STREAM, $
SEGMENT=GGORA, SEGTYPE=S0, $
FIELDNAME=CATEGORY, ALIAS=CAT, USAGE=A11, ACTUAL=A11,
MISSING=ON, $
FIELDNAME=Biscotti, ALIAS=BIS, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Capuccino, ALIAS=CAP, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Croissant, ALIAS=CROI, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Espresso, ALIAS=ESP, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Latte, ALIAS=LAT, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Mug, ALIAS=MUG, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Scone, ALIAS=SCO, USAGE=I08, ACTUAL=A08,
MISSING=ON, $
FIELDNAME=Thermos, ALIAS=THER, USAGE=I08, ACTUAL=A08,
MISSING=ON, $The following procedure creates the table
GGORA based on the FOCUS data source GGSALES (with MISSING=ON attributes
added to the DOLLARS field in the Master File):
APP HOLDMETA baseapp
APP HOLDDATA baseapp
SET HOLDMISS = ON
SET HOLDMISS = ON
SET ASNAMES = ON
TABLE FILE GGSALES
SUM DOLLARS AS ''
BY CATEGORY
ACROSS PRODUCT
WHERE PRODUCT NE 'Coffee Grinder' OR 'Coffee Pot'
ON TABLE HOLD AS GGFLAT FORMAT ALPHA
END
FILEDEF GGFLAT DISK baseapp/ggflat.ftm
CREATE FILE GGORA
MODIFY FILE GGORA
FIXFORM FROM GGFLAT
DATA ON GGFLAT
END
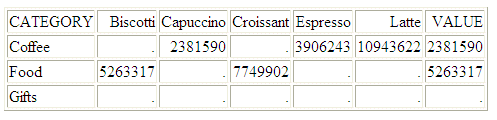
The following TABLE request calls the
SQL function COALESCE:
SET TRACEUSER = ON
SET TRACESTAMP = OFF
SET TRACEON = STMTRACE//CLIENT
DEFINE FILE GGORA
VALUE/I8 MISSING ON = SQL.COALESCE(Biscotti, Capuccino, Croissant, Espresso, Latte);
END
TABLE FILE GGORA
PRINT Biscotti Capuccino Croissant Espresso Latte VALUE
BY CATEGORY
ON TABLE SET PAGE NOPAGE
END
The trace output shows that the SQL function call was passed
to the RDBMS:
SELECT
COALESCE(T1."BIS",T1."CAP",T1."CROI",T1."ESP",T1."LAT"),
T1."CAT",
T1."BIS",
T1."CAP",
T1."CROI",
T1."ESP",
T1."LAT"
FROM
GGORA T1
ORDER BY
T1."CAT";
The output is:
xOptimizing Non-Equality WHERE-based Left Outer Joins
A left outer join selects all records from the host
table and matches them with records from the cross-referenced table.
When no matching records exist, the host record is still retained,
and default values (blank or zero) are assigned to the cross-referenced
fields. The relational adapters may optimize any WHERE-based left
outer join command in which the conditional expressions are supported
by the RDBMS.
x
Syntax: How to Specify a Conditional Left Outer Join
JOIN LEFT_OUTER FILE hostfile AT hfld1 [TAG tag1]
[WITH hfld2]
TO {UNIQUE|MULTIPLE}
FILE crfile AT crfld [TAG tag2] [AS joinname]
[WHERE expression1;
[WHERE expression2;
...]
ENDwhere:
- LEFT OUTER
Specifies a left outer join. If you do not specify the type
of join in the JOIN command, the ALL parameter setting determines
the type of join to perform.
- hostfile
Is the host Master File.
- AT
Links the correct parent segment or host to the correct child
or cross-referenced segment. The field values used as the AT parameter
are not used to cause the link. They are used as segment references.
- hfld1
Is the field name in the host Master File whose segment will
be joined to the cross-referenced data source. The field name must
be at the lowest level segment in the data source that is referenced.
- tag1
Is the optional tag name that is used as a unique qualifier
for fields and aliases in the host data source.
- WITH hfld2
Is a data source field with which to associate a DEFINE-based
conditional join. For a DEFINE-based conditional join, the KEEPDEFINES
setting must be ON, and you must create the virtual fields before
issuing the JOIN command.
- MULTIPLE
Specifies a one-to-many relationship between hostfile and crfile.
Note that ALL is a synonym for MULTIPLE.
- UNIQUE
Specifies a one-to-one relationship between hostfile and crfile.
Note that ONE is a synonym for UNIQUE.
Note: UNIQUE
returns only one instance and, if there is no matching instance
in the cross-referenced file, it supplies default values (blank
for alphanumeric fields and zero for numeric fields).
The
unique join is a FOCUS concept. The RDBMS makes no distinction between unique
and non-unique situations; it always retrieves all matching rows
from the cross-referenced file.
If the RDBMS processes a join
that the request specifies as unique, and if there are, in fact,
multiple corresponding rows in the cross-referenced file, the RDBMS
returns all matching rows. If, instead, optimization is disabled
so that FOCUS processes the join, a different report results because
FOCUS, respecting the unique join concept, returns only one cross-referenced
row for each host row.
- crfile
Is the cross-referenced Master File.
- crfld
Is the join field name in the cross-referenced Master File.
It can be any field in the segment.
- tag2
Is the optional tag name that is used as a unique qualifier
for fields and aliases in the cross-referenced data source.
- joinname
Is the name associated with the joined structure.
- expression1, expression2
Are any expressions that are acceptable in a DEFINE FILE
command. All fields used in the expressions must lie on a single path.
x
Reference: Conditions for WHERE-based Outer Join Optimization
- In order for a WHERE-based left outer join to be optimized,
the expressions must be optimizable for the RDBMS involved and at
least one of the following conditions must be true:
- The JOIN
WHERE command contains at least one field1 EQ field2 predicate
in which field1 is in table1 and field2 is
in table2.
or
- The right table has a key or a unique index that does not contain
NULL data.
or
- The right table contains at least one "NOT NULL" column that
does not have a long data type (such as TEXT or IMAGE).
- The adapter SQLJOIN OUTER setting must be ON (the default).
xOptimization of SUBSTR and SUBSTV Functions
The SUBSTR and SUBSTV FOCUS functions have been optimized
to their native SQL counterparts.
xOptimization of DATEADD and HADD Functions for YEAR and MONTH
The relational adapters now translate the DATEADD and
HADD FOCUS functions to their SQL counterparts. The year/month calculations
are optimized as an ADD_MONTHS() SQL function that will be processed
by the DBMS engine.
This is implemented for Oracle, DB2*, Teradata, Sybase IQ, and
MySQL.
Note:* For DB2, any calculations using the last day in
February (28/29 for leap year) generate incorrect predicates with
ADD_MONTHS and inaccurate calculations. The fix is available in
DB2 9.7 FixPack 4.
xIF-THEN-ELSE Optimization Enhancement
IF-THEN-ELSE optimization has been enhanced.
The default OPTIFTHENELSE setting is set to ON:
ENGINE SQLENG SET OPTIFTHENELSE ON
This setting optimizes all relational adapter IF-THEN-ELSE FOCUS
expressions as CASE or DECODE SQL expressions.
Valid OPTIFTHENELSE settings are:
- ON (default). Generates SQL CASE expressions for
FOCUS IF-THEN-ELSE expressions.
- OFF. Suppresses generation of SQL CASE or DECODE expressions
for IF-THEN-ELSE and/or DECODE expressions.
- CASE/ON CASE. Equivalent to ON.
- NOCASE/OFF NOCASE. Equivalent to OFF.
Starting in Version 7 Release 7, relational adapters optimize
IF-THEN-ELSE DEFINE fields only as SQL CASE statements. The WHERE
predicate without CASE is no longer generated.
xOptimizing IF-THEN-ELSE Using CASE
Optimization is the process in which the adapter translates
the projection, selection, join, sort, and aggregation operations
of a report request into their SQL equivalents and passes them to
the RDBMS for processing.
In some cases the relational adapters can optimize IF-THEN-ELSE
DEFINE expressions as part of aggregation or record selection.
In prior releases, two types of optimization were available for
IF-THEN-ELSE DEFINE fields:
- The expression could be converted to an expression in the
SQL WHERE predicate for a SELECT statement.
- The expression could be converted to an SQL CASE statement in
the SQL WHERE predicate for a SELECT statement. The SQL CASE statement
has WHEN, THEN, and ELSE clauses along with an END terminator. Starting
in Version 7 Release 7, the relational adapters optimize IF-THEN-ELSE
DEFINE fields only as SQL CASE statements. The WHERE predicate without
CASE is no longer generated.
x
Syntax: How to Control Optimization of IF-THEN-ELSE Expressions
ENGINE SQL SET OPTIFTHENELSE {ON|OFF}
where:
-
ON
-
Generates a CASE statement for IF-THEN-ELSE expressions and
DECODE expressions whenever possible. ON is the default value. Note
that CASE and ON CASE are synonyms for ON.
- OFF
-
Does not optimize IF-THEN-ELSE or DECODE expressions. Note
that NOCASE and OFF NOCASE are synonyms for OFF.
x
Reference: Usage Notes for SET OPTIFTHENELSE
- In prior releases, the options ON NOCASE and OFF CASE were supported.
These options are no longer valid.
- There is no guarantee that the SQL that is generated will improve
performance for all requests. If you find that this feature does
not improve performance, set OPTIFTHENELSE OFF to disable the feature.
Example: Using IF-THEN-ELSE Optimization Without Aggregation
Consider
the following request that has a WHERE condition on an IF-THEN-ELSE
DEFINE field named DEF1:
ENGINE DB2 SET OPTIFTHENELSE ON
DEFINE FILE DB2EMP
DEF1 = IF (LAST_NAME EQ ' ') AND (FIRST_NAME EQ ' ')
AND (DEPARTMENT EQ 'MIS') THEN 1 ELSE 0;
END
TABLE FILE DB2EMP
PRINT DEPARTMENT LAST_NAME FIRST_NAME
WHERE DEF1 EQ 1
ENDThe adapter generates an SQL request that incorporates
the IF-THEN-ELSE condition corresponding to the IF-THEN-ELSE DEFINE
field and the WHERE DEF1 EQ 1 test as a CASE statement:
SELECT
T1."LN",
T1."FN",
T1."DPT"
FROM
DB2EMP T1
WHERE
((CASE WHEN (((T1."LN" = ' ') AND (T1."FN" = ' ')) AND
(T1."DPT" = 'MIS')) THEN 1 ELSE 0 END) = 1)
FOR FETCH ONLY;
Example: Using IF-THEN-ELSE Optimization With Aggregation
The
following request displays the maximum salary when an IF-THEN-ELSE
DEFINE field named DEF2 equals 1:
ENGINE DB2 SET OPTIFTHENELSE ON
DEFINE FILE DB2EMP
DEF2 = IF LAST_NAME EQ 'SMITH' THEN 1 ELSE IF LAST_NAME EQ 'JONES' THEN 2
ELSE IF LAST_NAME EQ 'CARTER' THEN 3 ELSE 0;
END
TABLE FILE DB2EMP
SUM MAX.CURR_SAL IF DEF2 EQ 1
ENDThe adapter generates an SQL request that incorporates
the aggregation, the IF-THEN-ELSE DEFINE field, and the condition
corresponding to the WHERE DEF2 EQ 2 test as a CASE statement:
AGGREGATION DONE ...
SELECT
MAX(T1."CSAL")
FROM
DB2EMP T1
WHERE
((CASE (T1."LN") WHEN 'SMITH' THEN 1 WHEN 'JONES' THEN 2 WHEN
'CARTER' THEN 3 ELSE 0 END) = 1)
FOR FETCH ONLY;
Example: Using IF-THEN-ELSE Optimization With a Condition That Is Always False
The
following request has a condition that is always false because the
IF-THEN-ELSE DEFINE field named DEF3 is defined to be either 1 or
0, never 2:
ENGINE DB2 SET OPTIFTHENELSE ON
DEFINE FILE DB2EMP
DEF3 = IF FIRST_NAME EQ 'RITA' THEN 1 ELSE 0;
END
TABLE FILE DB2EMP
PRINT FIRST_NAME
IF DEF3 EQ 2
END
Because DEF3 EQ 2 will never be true, the adapter
passes the CASE statement ((CASE (T1."FN") WHEN 'RITA' THEN 1 ELSE
0 END) = 2), which is always false to the RDBMS, returning zero
records from the RDBMS:
SELECT
T1."FN"
FROM
DB2EMP T1
WHERE
((CASE (T1."FN") WHEN 'RITA' THEN 1 ELSE 0 END) = 2)
FOR FETCH ONLY;
xPassing the Exact Number of Trailing Blanks to the DBMS
All relational adapters have been enhanced to pass character
constants from the initial TABLE request to the database unchanged,
without truncating trailing spaces. It provides complete control
over the number of specified trailing spaces. This is important
for applications that communicate with RDBMS sensitive to trailing
blanks.
xCapturing Rows Affected by Direct SQL Passthru Commands as Dialogue Manager Variables
The &ROWSAFFECTED variable is populated with the
number of rows affected by the following DPT DML commands: INSERT,
UPDATE, and DELETE.
&ROWSAFFECTED is initialized to -1 and is set to -1 by any
Direct SQL Passthru command that does not return the number of rows
affected, such as a SELECT statement. &ROWSAFFECTED is undefined
for other types of requests, and remains unchanged for those requests.
Note: The value of &ROWSAFFECTED is overwritten each
time a Direct SQL Passthru INSERT, UPDATE, or DELETE command is
executed. If you want to retain the value, you must copy it to another
Dialogue Manager variable or store it in a calculated field.
The &ROWSAFFECTED variable is independent of the adapter
PASSRECS setting and is always populated for a Direct SQL Passthru
INSERT, UPDATE, or DELETE command, regardless of the value of the
PASSRECS parameter.
Example: Obtaining the Number of Rows Affected by a Direct SQL Passthru Command
The
following request creates an Oracle table:
TABLE FILE EMPLOYEE
SUM LAST_NAME FIRST_NAME DEPARTMENT
HIRE_DATE CURR_SAL CURR_JOBCODE
BY EMP_ID
ON TABLE HOLD AS EMPINFO FORMAT SQLORA
END
The EMPINFO Master File generated by the request
follows:
FILENAME=EMPINFO, SUFFIX=SQLORA
SEGNAME=EMPINFO ,SEGTYPE=S0,$
FIELD=EMP_ID ,ALIAS=EID ,USAGE=A9 ,ACTUAL=A9,$
FIELD=LAST_NAME ,ALIAS=LN ,USAGE=A15 ,ACTUAL=A15,$
FIELD=FIRST_NAME ,ALIAS=FN ,USAGE=A10 ,ACTUAL=A10,$
FIELD=HIRE_DATE ,ALIAS=HDT ,USAGE=YMD ,ACTUAL=DATE,$
FIELD=DEPARTMENT ,ALIAS=DPT ,USAGE=A10 ,ACTUAL=A10,
MISSING=ON,$
FIELD=CURR_SAL ,ALIAS=CSAL ,USAGE=P9.2 ,ACTUAL=P4,$
FIELD=CURR_JOBCODE ,ALIAS=CJC ,USAGE=A3 ,ACTUAL=A3,$
The
EMPINFO Access File generated by the request follows:
SEGNAME=EMPINFO, TABLENAME=EMPINFO, WRITE=YES, KEYS=1, $
The
following procedure sets the adapter PASSRECS setting to OFF, then
uses the Direct SQL Passthru DELETE command to delete all rows from
the Oracle table where the last name is SMITH. It saves the value
returned to &ROWSAFFECTED in another variable named &DELETE1.
Next, it deletes all rows where the first name is JOHN. It then
displays the number of rows affected by each delete command. &DELETE1
contains the value saved from the first delete command and &ROWSAFFECTED
contains the value from the second DELETE command:
SQL SQLORA SET PASSRECS OFF
SQL SQLORA
INSERT INTO EMPINFO (EID, LN, FN, DPT, HDT, CSAL, CJC) VALUES('111111111', 'ABEL', 'AARON', 'CORP', '990101', 25000, 'A05');
END
-RUN
-SET &IAFFECTED = &ROWSAFFECTED;
SQL SQLORA
DELETE FROM EMPINFO WHERE EID='111111111';
END
-RUN
-TYPE Rows affected on INSERT and DELETE: &IAFFECTED and &ROWSAFFECTED
SQL SQLORA SET PASSRECS OFF
SQL SQLORA
DELETE FROM EMPINFO WHERE LN='SMITH';
END
-RUN
-SET &DELETE1 = &ROWSAFFECTED;
SQL SQLORA
DELETE FROM EMPINFO WHERE FN='JOHN';
END
-RUN
-TYPE Rows affected on both deletes: &DELETE1 and &ROWSAFFECTEDSince
two employees had the last name SMITH and two employees had the
first name JOHN, two rows were deleted by each DELETE command:
Rows affected on both deletes: 2 and 2
If
you set the value of PASSRECS to ON, in addition to populating the
&ROWSAFFECTED variable you generate the FOC1364 message for
each Direct SQL Passthru INSERT, UPDATE, or DELETE command:
SQL SQLORA SET PASSRECS ON
SQL SQLORA
DELETE FROM EMPINFO WHERE LN='SMITH';
END
-RUN
-SET &DELETE1 = &ROWSAFFECTED;
SQL SQLORA
DELETE FROM EMPINFO WHERE FN='JOHN';
END
-RUN
-TYPE Rows affected on both deletes: &DELETE1 and &ROWSAFFECTED
The
PASSRECS ON setting generates the FOC1364 messages:
(FOC1364) ROWS AFFECTED BY PASSTHRU COMMAND : 2/DELETE
(FOC1364) ROWS AFFECTED BY PASSTHRU COMMAND : 2/DELETE
Rows affected on both deletes: 2 and 2
xPassing the Equivalent of FOCUS PCT to the SQL Engine
The relational adapters have been enhanced to optimize
aggregation in the presence of the FOCUS PCT function (which has
no direct SQL counterparts) to SQL SUM(). Note that:
- The percentage itself is not optimized (there is no SQL
equivalent) and it is calculated by FOCUS based on the obtained
SUMs.
- The SQL HAVING clause is not (and must not be) generated in
the presence of a PCT.
- HOLD FORMAT SAME_DB does not (and cannot) be used. It will result
in FOC2634 HOLD FORMAT SAME_DB CANNOT BE PERFORMED.
xUsing the DPART Function in SQL Generation
The DPART FOCUS function, which extracts a specified
component from a date field and returns it in numeric format, can
be passed to SQL for improved performance.
The syntax is:
DPART (value, 'component', outfield)
where:
- value
Is an input parameter (date) which can be a constant or a
variable in one of the following formats:
- (YYMD, ...,
...)
- (MDYY, ..., ...)
- (DMYY, ..., ...)
- component
Is one from the subset of components that can be specified
as:
- (..., 'YEAR',...)
- (..., 'YY',...)
- (..., 'QUARTER',...)
- (..., 'QQ',...)
- (..., 'MONTH',...)
- (..., 'MM',...)
- (..., 'DAY',...)
- (..., 'DD',...)
- (..., 'DAY-OF-MONTH',...)
Formats are case-sensitive.
- outfield
Is an integer variable or an I format enclosed in single quotes.
If any input errors are made, a value of zero will be returned.
For more information, see Optimization of the HPART, DPART, HDIFF, HDATE, and DATEDIF Functions.
Example: Extracting a Component From a Date Field
DEFINE FILE CAR
DATE/YYMD = IF COUNTRY IS 'ENGLAND' THEN '1941 DEC 7' ELSE DATE
+ 30;
YEAR/I11 = DPART(DATE, 'YEAR', 'I11');
MONTH/I11 = DPART(DATE, 'MM', 'I11');
DAY/I11 = DPART(DATE, 'DAY', 'I11');
END
TABLE FILE CAR
PRINT COUNTRY DATE YEAR MONTH DAY
END
COUNTRY DATE YEAR MONTH DAY
------- ---- ---- ----- ---
ENGLAND 1941/12/07 1941 12 7
JAPAN 1942/01/06 1942 1 6
ITALY 1942/02/05 1942 2 5
W GERMANY 1942/03/07 1942 3 7
FRANCE 1942/04/06 1942 4 6
>>
xOptimization of the HPART, DPART, HDIFF, HDATE, and DATEDIF Functions
The relational adapters can translate certain calls
to the HPART, DPART, HDIFF, HDATE, and DATEDIF functions to SQL
date and time functions, allowing the optimization of some TABLE
requests with DEFINE fields that call these functions.
x
Optimization of the DATEDIF and HDIFF Functions
The DATEDIF function returns the difference between
two dates in units, and the HDIFF function returns the difference
between two date-time values in units. Calls to these functions
can be translated to SQL when the unit is the number of days between two
values.
x
Syntax: How to Calculate the Number of Days Between Date or Date-Time Values
The
syntax for the DATEDIF function with the day unit
is
DATEDIF(from_date, to_date, 'D')
The
syntax for the HDIFF function with the day unit
is
HDIFF(to_date_time, from_date_time, 'DAY', outfield)
where:
- from_date
Is the starting date or date-time value from which to calculate
the difference.
- to_date
Is the ending date or date-time value from which to calculate
the difference.
- outfield
Numeric
Is the name of the field that contains the result, or the
format of the output value enclosed in single quotation marks.
x
Reference: Conversion of the DATEDIF and HDIFF Functions to SQL
For
Microsoft SQL Server, Oracle, SYBASE ASE and IQ, calls to DATEDIF
and HDIFF translate calls to the native DATE-TIME functions with
Datepart Parameter DAY, Startdate, and Enddate.
For example,
for DB2, calls to DATEDIF and HDIFF translate as calls to the DAYS function:
SELECT DAYS(d2) - DAYS(d1) FROM tablename
For
Teradata, calls to DATEDIF and HDIFF translate as a simple difference
between two date values for the DATE datatype and as calls to the
CAST function for the TIMESTAMP datatype.
Example: Optimizing the Difference Between DB2 Date or Timestamp Columns
The
following Master File represents a DB2 table named DATETIME with
two DATE fields named DATE1 and DATE2 and two TIMESTAMP fields named
TIMEST1 and TIMEST2:
FILENAME=DATETIME, SUFFIX=DB2 , $
SEGMENT=DATETIME, SEGTYPE=S0, $
FIELDNAME=DATE1, ALIAS=DATE1, USAGE=YYMD, ACTUAL=DATE,
MISSING=ON, $
FIELDNAME=DATE2, ALIAS=DATE2, USAGE=YYMD, ACTUAL=DATE,
MISSING=ON, $
FIELDNAME=TIMEST1, ALIAS=TIMEST1, USAGE=HYYMDm, ACTUAL=HYYMDm,
MISSING=ON, $
FIELDNAME=TIMEST2, ALIAS=TIMEST2, USAGE=HYYMDm, ACTUAL=HYYMDm,
MISSING=ON, $The following request calculates
the number of days difference between DATE1 and DATE2 using the
DATEDIF function and the number of days difference between TIMEST1
and TIMEST2 using the HDIFF function:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT DATE1 DATE2 TIMEST1 TIMEST2
WHERE DATEDIF(DATE2, DATE1, 'D') LT 5 AND
HDIFF(TIMEST1, TIMEST1, 'DAY', 'I11') EQ 1
END
The SQL generated for this request replaces the
calls to DATEDIF and HDIFF with calls to the SQL DAYS function in
the SQL WHERE predicate:
SELECT T1."DATE1", T1."DATE2", T1."TIMEST1", T1."TIMEST2"
FROM OWNER1.DATETIME T1
WHERE ((DAYS(T1."TIMEST1") - DAYS(T1."TIMEST1")) = 1) AND
((DAYS(T1."DATE1") - DAYS(T1."DATE2")) < 5)
FOR FETCH ONLY;
Example: Optimizing the Difference Between Oracle Date or Timestamp Columns
The
following Master File represents an Oracle table named DATETIME
with two DATE fields named DATE1 and DATE2 and two TIMESTAMP fields
named TIMEST1 and TIMEST2:
FILENAME=DATETIME, SUFFIX=SQLORA , $
SEGMENT=DATETIME, SEGTYPE=S0, $
FIELDNAME=DATE1, ALIAS=DATE1, USAGE=YYMD, ACTUAL=DATE,
MISSING=ON, $
FIELDNAME=DATE2, ALIAS=DATE2, USAGE=YYMD, ACTUAL=DATE,
MISSING=ON, $
FIELDNAME=TIMEST1, ALIAS=TIMEST1, USAGE=HYYMDm, ACTUAL=HYYMDm,
MISSING=ON, $
FIELDNAME=TIMEST2, ALIAS=TIMEST2, USAGE=HYYMDm, ACTUAL=HYYMDm,
MISSING=ON, $The following request calculates
the number of days difference between DATE1 and DATE2 using the
DATEDIF function and the number of days difference between TIMEST1
and TIMEST2 using the HDIFF function:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT DATE1 DATE2 TIMEST1 TIMEST2
WHERE DATEDIF(DATE2, DATE1, 'D') LT 5 AND
HDIFF(TIMEST1, TIMEST1, 'DAY', 'I11') EQ 1
END
The SQL generated for this request replaces the
calls to DATEDIF and HDIFF with calls to the SQL EXTRACT and TRUNC
functions in the SQL WHERE predicate:
SELECT T1."DATE1", T1."DATE2", T1."TIMEST1", T1."TIMEST2"
FROM OWNER1.DATETIME T1
WHERE (EXTRACT(DAY FROM (TRUNC(T1."TIMEST1") - TRUNC(T1."TIMEST1"))
DAY(9) TO SECOND) = 1)
AND (EXTRACT(DAY FROM (TRUNC(T1."DATE1") - TRUNC(T1."DATE2"))
DAY(9) TO SECOND) < 5);
x
Optimization of the HPART and DPART Functions
The HPART function extracts a specified component from
a date-time value and returns it in numeric format. The DPART function
extracts a specified component from a date value and returns it
in numeric format. Calls to HPART and DPART are optimized when the
second parameter is a case insensitive YEAR, MONTH, QUARTER, DAY-OF-MONTH,
or DAY. Calls to HPART are also optimized when the second argument
is a case-insensitive HOUR, MINUTE, SECOND, or MICROSECOND.
x
Syntax: How to Extract a Component From a Date-Time Value
HPART(dtvalue, 'component', outfield)
where:
- dtvalue
Date-time
Is a date-time value, the name of a date-time
field that contains the value, or an expression that returns the
value.
- component
Alphanumeric
Is the name of the component to be retrieved
enclosed in single quotation marks.
- outfield
Integer
Is the field that contains the result, or the
integer format of the output value enclosed in single quotation
marks.
x
Syntax: How to Extract a Date Component and Return a Date Component in Integer Format
DPART (datevalue, 'component', outfield)
where:
-
datevalue
-
Date
Is a full component date.
-
component
-
Alphanumeric
Is the name of the component to be retrieved
enclosed in single quotation marks. Valid values are:
For
year: YEAR, YY
For month: MONTH, MM
For day: DAY, For
day of month: DAY-OF-MONTH.
For quarter: QUARTER, QQ
-
outfield
-
Integer
Is the field that contains the result, or the
integer format of the output value enclosed in single quotation marks.
x
Reference: Conversion of the HPART Function to SQL
For
Microsoft SQL Server, SYBASE ASE, and IQ, calls to HPART and DPART
translate as calls to the DATEPART function.
For DB2 and MySQL,
calls to HPART translate as calls to the YEAR, MONTH, or DAY function.
For
Oracle and TERADATA (Both DATE and TIMESTAMP datatypes), calls to
HPART and DPART translate as calls to the EXTRACT function.
Example: Extracting a Component From a DB2 Timestamp Column
The
following request uses the HPART function to retrieve the year component
from the DB2 TIMEST1 column:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT TIMEST1
WHERE HPART(TIMEST1, 'YEAR', 'I4') EQ 2008
END
The generated SQL replaces the call to the HPART
function with a call to the SQL YEAR function in the SQL WHERE predicate:
SELECT T1."TIMEST1" FROM OWNER1.DATETIME T1
WHERE (YEAR(T1."TIMEST1") = 2008)
FOR FETCH ONLY;
Example: Extracting a Component From an Oracle Timestamp Column
The
following request uses the HPART function to retrieve the year component
from the Oracle TIMEST1 column:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT TIMEST1
WHERE HPART(TIMEST1, 'YEAR', 'I4') EQ 2008
END
The generated SQL replaces the call to the HPART
function with a call to the SQL EXTRACT function in the SQL WHERE
predicate:
SELECT T1."TIMEST1" FROM OWNER1.DATETIME T1
WHERE (EXTRACT(YEAR FROM T1."TIMEST1") = 2008);
x
Optimization of the HDATE Function
The HDATE function converts the date portion of a date-time
value to the date format YYMD.
x
Syntax: How to Extract the Date Portion of a Date-Time Value
HDATE(dtvalue, {'YYMD'|outfield})where:
- dtvalue
Date-time
Is the date-time value to be converted, the
name of a date-time field that contains the value, or an expression
that returns the value.
- YYMD
Date
Is the output format. The value must be YYMD.
- outfield
YYMD
Is the field that contains the result.
x
Reference: Conversion of the HDATE Function to SQL
For Microsoft
SQL Server (2008 and up), SYBASE ASE and IQ, DB2, TERADATA, and
MySQL, calls to DATE translate as calls to the CAST function.
For Oracle, calls to HDATE translate
as calls to the TRUNC function.
Example: Extracting the Date Portion of a DB2 Timestamp Column
The
following request uses the HDATE function to extract the date portion
of the TIMEST1 column:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT DATE1 TIMEST1
WHERE HDATE(TIMEST1, 'YYMD') GT DATE1
END
In the generated SQL, the call to HDATE is replaced
by a call to the SQL CAST function in the SQL WHERE predicate:
SELECT T1."DATE1", T1."TIMEST1" FROM OWNER1.DATETIME T1
WHERE (CAST(T1."TIMEST1" AS DATE) > T1."DATE1")
FOR FETCH ONLY;
Example: Extracting the Date Portion of an Oracle Timestamp Column
The
following request uses the HDATE function to extract the date portion
of the TIMEST1 column:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
TABLE FILE DATETIME
PRINT DATE1 TIMEST1
WHERE HDATE(TIMEST1, 'YYMD') GT DATE1
END
In the generated SQL, the call to HDATE is replaced
by a call to the SQL TRUNC function in the SQL WHERE predicate:
SELECT T1."DATE1", T1."TIMEST1" FROM OWNER1.DATETIME T1
WHERE (TRUNC(T1."TIMEST1") > T1."DATE1");
xPassing Virtual Fields Defined as Constants to an SQL Engine
A virtual field defined as a constant is passed directly
to an SQL database engine (RDBMS) for optimized processing that
takes advantage of RDBMS join, sort, and aggregation capabilities.
This reduces the volume of RDBMS-to-FOCUS communication, which improves
response time.
xImproved Error Diagnostics in Expression Generation
Diagnostic messages and tracing for aggregation functions,
DB-lookup of SQL Tables, and Cluster join structures that explain
SQL statement generation have been improved.
xDB2 DSN3SATH Support for CA-ACF2
The Adapter for DB2 supports primary and secondary authorization security
checking for DSN3SATH. Three modifications are required, as shown
in the following example.
Example: Changing DSN3SATH for RACF and eTrust CA-Top Secret Sites
1. Search for the SATH001 label -
add two lines (FOCDSN3):
SATH001 DS 0H
USING WORKAREA,R11 ESTABLISH DATA AREA ADDRESSABILITY
ST R2,FREMFLAG SAVE FREEMAIN INDICATOR
XC SAVEAREA(72),SAVEAREA CLEAR REGISTER SAVE AREA
.
.
.
*********SECTION 1: DETERMINE THE PRIMARY AUTHORIZATION ID ************
* *
* IF THE INPUT AUTHID IS NULL OR BLANKS, CHANGE IT TO THE AUTHID *
* IN EITHER THE JCT OR THE FIELD POINTED TO BY ASCBJBNS. *
* THE CODE IN THIS SECTION IS AN ASSEMBLER LANGUAGE VERSION OF *
* THE DEFAULT IDENTIFY AUTHORIZATION EXIT. IT IS EXECUTED ONLY *
* IF THE FIELD ASXBUSER IS NULL UPON RETURN FROM THE RACROUTE *
* SERVICE. FOR EXAMPLE, IT DETERMINES THE PRIMARY AUTH ID FOR *
* ENVIRONMENTS WITH NO SECURITY SYSTEM INSTALLED AND ACTIVE. *
* *
*************************************************************************
SPACE
LA R1,AIDLPRIM LOAD PARM REG1 <--ADD
CALL FOCDSN3 GO GET THE IBI EXIT <--ADD
CLI AIDLPRIM,BLANK IS THE INPUT PRIMARY AUTHID NULL
BH SATH020 SKIP IF A PRIMARY AUTH ID EXISTS2. Search for the SATH020 label -
add a comment box, add one line, and comment out four lines:
SATH020 DS 0H BRANCH TO HERE IF PRIMARY EXISTS
*****OPTIONAL CHANGE @CHAR7: FALLBACK TO SEVEN CHAR PRIMARY AUTHID***
* *
* IF YOUR INSTALLATION REQUIRES ONLY SEVEN CHARACTER PRIMARY *
* AUTHORIZATION IDS (POSSIBLY TRUNCATED) DUE TO DB2 PRIVILEGES *
* GRANTED TO TRUNCATED AUTHORIZATION IDS, THEN YOU MUST BLANK OUT *
* COLUMN 1 OF THE ASSEMBLER STATEMENT IMMEDIATELY FOLLOWING THIS *
* BLOCK COMMENT. THEN ASSEMBLE THIS PROGRAM AND LINK-EDIT IT INTO *
* THE APPROPRIATE DB2 LOAD LIBRARY AS EXPLAINED IN AN APPENDIX *
* OF "THE DB2 ADMINISTRATION GUIDE". *
* *
* OTHERWISE, YOU NEED DO NOTHING. *
* @KYD0271*
**********************************************************************
* MVI AIDLPRIM+7,BLANK BLANK OUT EIGHTH CHARACTER
SPACE
.
.
.
* RACF IS ACTIVE ON THIS MVS
****************************************************************** <--ADD
* * <--ADD
* The logic was modified because in DB2 V8 AIDLACEE is always not* <--ADD
* NULL. We used to honor AIDLACEE first, FOCDSN4 second and then * <--ADD
* AS ACEE. Now we honor FOCDSN4 first, AIDLACEE second and then * <--ADD
* AS ACEE. * <--ADD
* * <--ADD
* 03/11/05 ASK0 * <--ADD
****************************************************************** <--ADD
USING ACEE,R6 ESTABLISH BASE FOR ACEE @KYL0108
L R6,AIDLACEE Get => caller ACEE if any <--ADD
* ICM R6,B'1111',AIDLACEE CALLER PASSED ACEE ADDRESS? @KYL0108 <-COMMENT
* BZ SATH024 NO, USE ADDRESS SPACE ACEE @KYL0108 <-COMMENT
* CLC ACEEACEE,EYEACEE IS IT REALLY AN ACEE? @KYL0108 <-COMMENT
* BE SATH027 YES, PROCEED NORMALLY @KYL0108 <-COMMENT
SPACE 1
SATH024 DS 0H USE ADDRESS SPACE ACEE @KYL0108
.
.
.3. Search for the SATH025 label - replace
sath025 and add sath026 (FOCDSN4):
SATH025 DS 0H
CALL FOCDSN4 GO GET THE IBI EXIT (4=GROUP AUTH) <--ADD
LTR R6,R6 DOES AN ACEE EXIST? IF NOT, <--ADD
BZ SATH026 CHECK ACEE IN ADDRESS SPACE <--ADD
CLC ACEEACEE,EYEACEE DOES IT LOOK LIKE AN ACEE? <--ADD
BE SATH027 YES, GO DO GROUPS <--ADD
SATH026 DS 0H <--ADD
L R6,ASCBASXB GET ADDRESS SPACE EXTENSION BLOCK <--ADD
L R6,ASXBSENV-ASXB(,R6) GET ACEE ADDRESS <--ADD
CLC ACEEACEE,EYEACEE DOES IT LOOK LIKE AN ACEE? <--ADD
BNE SATH049 NO, THEN CAN'T DO GROUPS <--ADD
DROP R8 DROP ASCB BASE REG <--ADD
SPACE 1 <--ADDSATH027 DS 0H CHECK LIST OF GROUPS OPTION
TM RCVTOPTX,RCVTLGRP IS LIST OF GROUPS CHECKING ACTIVE
BZ SATH040 SKIP TO SINGLE GROUP COPY IF NOT
DROP R7 DROP RCVT BASE REG
SPACE 1
* RACF LIST OF GROUPS OPTION IS ACTIVE
EJECT
.
.
.
xCAF Support for SQL Statements With Lengths Greater Than 32K
The adapter supports the increased length of SQL statements
from 32K to 2MB. This feature is supported on z/OS for DB2 Version
8 and higher and AS400 Version 5.4 and higher, with the maximum
length 2MB. On AS400 Version 5.3, the maximum length is set to 64K.
xSupport for DB2 Change Data Capture on z/OS
Change Data Capture allows loading of data targets using
only the rows that have changed since the last load. This approach
is useful when dealing with large databases that would take too
much time and too many resources to reload completely. This capability
is supported for DataMigrator and for DB2 data sources on the z/OS
platform.
xPassing the SUBSTR Character Function to SQL
The SUBSTR character function can be passed to SQL for
optimized processing that takes advantage of RDBMS substring functions,
thus improving performance and response time.
xSupport of Multirow-Fetch for DB2 (CAF)
The FETCHSIZE value is the number of rows to be retrieved
at once using array retrieval techniques for the CLI adapter or
a cursor with Rowset positioning and multi row Fetch for the CAF
adapter. Accepted values are 1 to 32000. The default is 100. If
the result set contains a column that has to be processed as a CLOB
or a BLOB, the FETCHSIZE value used for that result set is 1.
xSupport for Oracle BIGINT Data Type
The BIGINT data type is supported. It can be a signed,
binary integer value from -9,223,372,036,854,775,808 to
9,223,372,036,854,775,807.
The data type should be mapped as USAGE=P20, ACTUAL=P10.
xSupport for Oracle Change Data Capture (CDC)
The Adapter for Oracle now supports Change Data Capture
(CDC). It provides the ability to capture incremental changes in
the database, making them available to FOCUS and utilizing them
for different purposes, including data replication and forensics.
xEnhanced DECIMAL Data Type Support for Oracle
The Decimal/Numeric(n,m) data type is
supported in a wider range. The supported precision length has been
increased from 18 up to 31 digits.