Features Added in FOCUS 7.7.06
The following features were added as of FOCUS 7.7.06.
xRolling Up Calculations on Summary Rows
Using SUMMARIZE
and RECOMPUTE, you can recalculate values at sort field breaks,
but these calculations use the detail data to calculate the value
for the summary line.
Using the ROLL. operator in conjunction with another prefix operator
on a summary line recalculates the sort break values using the values
from summary lines generated for the lower level sort break.
The operator combinations supported are:
- ROLL.SUM. (same as ROLL.). Alphanumeric fields are supported
with SUM. This returns either the first or last value according
to the SUMPREFIX parameter.
- ROLL.AVE.
- ROLL.MAX. (supported with alphanumeric fields as well as numeric
fields)
- ROLL.MIN. (supported with alphanumeric fields as well as numeric
fields)
- ROLL.FST. (supported with alphanumeric fields as well as numeric
fields)
- ROLL.LST. (supported with alphanumeric fields as well as numeric
fields)
- ROLL.CNT.
- ROLL.ASQ.
ROLL.prefix on a summary line indicates
that the prefix operation will be performed on the summary values
from the next lowest level of summary command.
If the ROLL. operator is used without another prefix operator,
it is treated as a SUM. Therefore, if the summary command for the
lowest BY field specifies AVE., and the next higher specifies ROLL.,
the result will be the sum of the averages. To get the average of
the averages, you would use ROLL.AVE at the higher level.
Note: With SUMMARIZE and SUB-TOTAL, the same calculations
are propagated to all higher level sort breaks.
x
Syntax: How to Roll Up Summary Values
BY field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} [ROLL.][prefix1.]
[field1 field2 ...|*] [ROLL.][prefix2.] [fieldn ...]Or:
BY field
ON field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} ROLL.[prefix.]
[field1 field2 ...|*]where:
- ROLL.
Indicates that the summary values should be calculated using
the summary values from the next lowest level summary command.
- field
Is a BY field in the request.
- prefix1, prefix2
Are prefix operators to use for the summary values. Can be
one of the following operators: SUM. (the default operator if none
is specified), AVE., MAX., MIN., FST., LST., CNT., ASQ.
- field1 field2 fieldn
Are fields to be summarized.
- *
Indicates that all fields, numeric and alphanumeric, should
be included on the summary lines. You can either use the asterisk
to display all columns or reference the specific columns you want
to display.
Example: Rolling Up an Average Calculation
The
following request against the GGSALES data source contains two sort
fields, REGION and ST. The summary command for REGION applies the
AVE. operator to the sum of the units value for each state.
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SET PAGE NOPAGE
END On the
output, the UNITS values for each state are averaged to calculate
the subtotal for each region. The UNITS values for each state are
also used to calculate the average for the grand total row.
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
TOTAL 45144The following version
of the request adds a summary command for the grand total line that
includes the ROLL. operator:
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SUBTOTAL ROLL.AVE.
ON TABLE SET PAGE NOPAGE
END On the
output, the UNITS values for each state are averaged to calculate
the subtotal for each region, and those region subtotal values are
used to calculate the average for the grand total row:
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
TOTAL 47330
Example: Propagating Rollups to Higher Level Sort Breaks
The
following request against the GGSALES data source has three BY fields.
The SUBTOTAL command for the PRODUCT sort field specifies AVE.,
and the SUMMARIZE command for the higher level sort field, REGION,
specifies ROLL.AVE.
TABLE FILE GGSALES
SUM UNITS
BY REGION
BY PRODUCT
BY HIGHEST DATE
WHERE DATE GE 19971001
WHERE REGION EQ 'Midwest' OR 'Northeast'
WHERE PRODUCT LIKE 'C%'
ON PRODUCT SUBTOTAL AVE.
ON REGION SUMMARIZE ROLL.AVE.
ON TABLE SET PAGE NOPAGE
END
On the output, the detail rows for each
date are used to calculate the average for each product. Because
of the ROLL.AVE. at the region level, the averages for each product
are used to calculate the averages for each region, and the region
averages are used to calculate the average for the grand total line:
Region Product Date Unit Sales
------ ------- ---- ----------
Midwest Coffee Grinder 1997/12/01 4648
1997/11/01 3144
1997/10/01 1597
*TOTAL PRODUCT Coffee Grinder 3129
Coffee Pot 1997/12/01 1769
1997/11/01 1462
1997/10/01 2346
*TOTAL PRODUCT Coffee Pot 1859
Croissant 1997/12/01 7436
1997/11/01 5528
1997/10/01 6060
*TOTAL PRODUCT Croissant 6341
*TOTAL REGION Midwest 3776
Northeast Capuccino 1997/12/01 1188
1997/11/01 2282
1997/10/01 3675
*TOTAL PRODUCT Capuccino 2381
Coffee Grinder 1997/12/01 1536
1997/11/01 1399
1997/10/01 1315
*TOTAL PRODUCT Coffee Grinder 1416
Coffee Pot 1997/12/01 1442
1997/11/01 2129
1997/10/01 2082
*TOTAL PRODUCT Coffee Pot 1884
Croissant 1997/12/01 4291
1997/11/01 6978
1997/10/01 4741
*TOTAL PRODUCT Croissant 5336
*TOTAL REGION Northeast 2754
TOTAL 3265
x
Reference: Usage Notes for ROLL.
- ROLL.prefix on a summary line indicates
that the prefix operation will be performed on the summary values
from the next lowest level of summary command.
- If no summary command was issued at the level below the ROLL.,
and no other operator was used in conjunction with the ROLL., a
SUM. will be calculated. If the lower level had no summary command
and ROLL. was used with another prefix operator (for example, ROLL.AVE.),
the specified prefix operator will be used. For example, ROLL.AVE. will
become AVE.
- CNT. prefix shows the number of data
lines displayed, which is not affected by MULTILINES.
- ROLL.CNT. prefix shows the number of
summary lines displayed, which is affected by MULTILINES.
xUsing Multiple Prefix Operators on the Same Measure in SUBTOTAL
You can now reference a field with multiple prefix operators
in a summary command using the prefix operator to differentiate
between the fields with multiple operators.
Using prefix operators on summary lines requires the setting
SET SUMMARYLINES=NEW. This is now the default setting.
Example: Differentiating Between Fields With Multiple Prefix Operators
The following request uses both the
MAX. and MIN. prefix operators with the UNITS field. On the summary
commands, these are differentiated by referencing them as MAX.UNITS
and MIN.UNITS.
TABLE FILE GGSALES
SUM MAX.UNITS MIN.UNITS
BY REGION
BY ST
ON REGION RECOMPUTE MAX. MAX.UNITS MIN. MIN.UNITS
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE RECOMPUTE MIN. MAX.UNITS MAX. MIN.UNITS
ON TABLE SET PAGE NOPAGE
END
On the report output, the summary for
each region displays the maximum of the state maximum values and
the minimum of the state minimum values. The summary for the entire report
displays the minimum of the state maximum values and the maximum
of the state minimum values. The report output is shown in the following
image:
MAX MIN
Region State Unit Sales Unit Sales
------ ----- ---------- ----------
Northeast CT 3015 101
MA 1780 146
NY 1797 73
*TOTAL Northeast 3015 73
West CA 1794 72
WA 1787 257
*TOTAL West 1794 72
TOTAL 1780 257
xAdding DBA Restrictions to the Join Condition
When DBA restrictions are applied to a request on a
multi-segment structure, by default the restrictions are added as
WHERE conditions in the report request. When the DBAJOIN parameter
is set ON, DBA restrictions are treated as internal to the file or
segment for which they are specified, and are added to the join
syntax.
Note: DBA restrictions with DBAJOIN OFF apply to the entire
record instance that is being retrieved. Therefore, the entire record
instance is suppressed when any part of that instance is restricted.
DBAJOIN ON applies the DBA only to the segment where the data value
appears, allowing the rest of the record instance to be displayed,
if applicable.
This difference is important when the file or segment being restricted
has a parent in the structure and the join is an outer or unique
join.
When restrictions are treated as report filters, lower-level
segment instances that do not satisfy them are omitted from the
report output, along with their host segments. Since host segments
are omitted, the output does not reflect a true outer or unique
join.
When the restrictions are treated as join conditions, lower-level
values from segment instances that do not satisfy them are displayed
as missing values, and the report output displays all host rows.
DBA VALUE_WHERE restrictions are not supported for SET DBAJOIN.
x
Syntax: How to Add DBA Restrictions to the Join Condition
SET DBAJOIN = {OFF|ON}where:
- OFF
-
Treats DBA restrictions as IF filters in the report request.
OFF is the default value.
- ON
-
Treats DBA restrictions as join conditions.
Example: Using the DBAJOIN Setting With Relational Tables
The following request creates two tables,
EMPINFOSQL and EDINFOSQL:
TABLE FILE EMPLOYEE
SUM LAST_NAME FIRST_NAME CURR_JOBCODE
BY EMP_ID
ON TABLE HOLD AS EMPINFOSQL FORMAT SQLMSS
END
-RUN
TABLE FILE EDUCFILE
SUM COURSE_CODE COURSE_NAME
BY EMP_ID
ON TABLE HOLD AS EDINFOSQL FORMAT SQLMSS
END
Add the following DBA attributes to the end of
the generated EMPINFOSQL Master File. With the restrictions listed,
USER2 cannot retrieve course codes of 300 or above:
END
DBA=USER1,$
USER=USER2, ACCESS = R, $
FILENAME=EDINFOSQL,$
USER=USER2, ACCESS = R, RESTRICT = VALUE, NAME=SYSTEM, VALUE=COURSE_CODE LT 300;,$
Add the following DBA attributes to
the end of the generated EDINFOSQL Master File:
END
DBA=USER1,DBAFILE=EMPINFOSQL,$
Issue
the following request:
SET USER=USER2
SET DBAJOIN=OFF
JOIN LEFT_OUTER EMP_ID IN EMPINFOSQL TO MULTIPLE EMP_ID IN EDINFOSQL AS J1
TABLE FILE EMPINFOSQL
PRINT LAST_NAME FIRST_NAME COURSE_CODE COURSE_NAME
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
END
On the report output,
all host and child rows with course codes 300 or above have been omitted,
as shown in the following image:

In the generated SQL the DBA restriction
has been added to the WHERE predicate in the SELECT statement:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."CC",
T2."CD"
FROM
EMPINFOSQL T1,
EDINFOSQL T2
WHERE
(T2."EID" = T1."EID") AND
(T2."CC" < '300;');
Rerun
the request with SET DBAJOIN=ON. The output now displays all host
rows, with missing values substituted for lower-level segment instances
that did not satisfy the DBA restriction, as shown on the following
image:
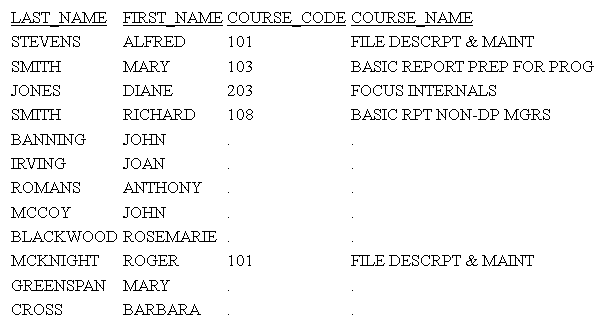
In the generated SQL, the DBA restriction
has been added to the join, and there is no WHERE predicate:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."EID",
T2."CC",
T2."CD"
FROM
( EMPINFOSQL T1
LEFT OUTER JOIN EDINFOSQL T2
ON T2."EID" = T1."EID" AND
(T2."CC" < '300;') );
xCalculating the Median and Mode of a Field
You can use the MDN. (median) and MDE. (mode) prefix
operators, in conjunction with an aggregation display command (SUM,
WRITE) and a numeric or smart date field, to calculate the statistical
median and mode of the values in a field.
These calculations are not supported in a DEFINE command, in
WHERE or IF expressions, or on a summary line. If used in a multi-verb
request, they must be used at the lowest level of aggregation.
The median is the middle value (50th percentile). If there are
an even number of values, the median is the average of the middle
two values. The mode is the value that occurs most frequently within
the set of values. If no value occurs more frequently than the others,
MDE. returns the lowest value.
Example: Calculating the Median and Mode
The following request against the EMPLOYEE
data source displays the current salaries and calculates the average
(mean), median, and mode within each department.
TABLE FILE EMPLOYEE
SUM CURR_SAL AS 'INDIVIDUAL,SALARIES'
AVE.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,AVERAGE'
MDN.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,MEDIAN'
MDE.CURR_SAL WITHIN DEPARTMENT AS 'DEPARTMENT,MODE'
BY DEPARTMENT
BY CURR_SAL NOPRINT
BY LAST_NAME NOPRINT BY FIRST_NAME NOPRINT
ON TABLE SET PAGE NOPAGE
END
Both departments have
an even number of employees. For the MIS department, the two middle
values are the same, making that value ($18,480.00) both the median
and the mode. For the PRODUCTION department, the median is the average
of the two middle values ($16,100.00 and $21,120.00) and, since
there are no duplicate values, the mode is the lowest value ($9,500.00).
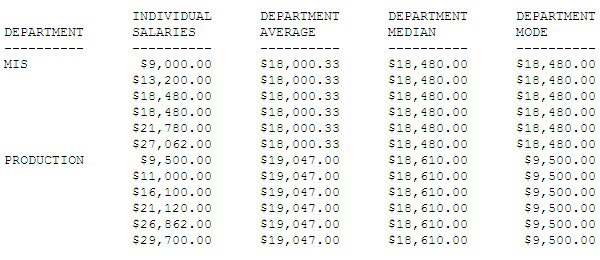
xControlling Display of an ACROSS Title for a Single Field
By default, when there is only one field displayed for
an ACROSS sort group, no column title displays above that field.
Using the SET ACRSVRBTITL command, you can control the display of
ACROSS column titles when there is one displayed field for an ACROSS
group. The field count that determines whether the ACROSS title
displays is affected by certain components in the report request,
such as calculated fields or fields in headings.
The output is unaffected by SET commands that adjust underlines
with titles, adjust the space between columns, or eliminate unpopulated
ACROSS columns on the page. The size of the title and the number
of lines it occupies also do not affect the output.
x
Syntax: How to Control Display of an ACROSS Title for a Single Field
SET ACRSVRBTITL = {OFF|ON|HIDEONE}
ON TABLE SET ACRSVRBTITL {OFF|ON|HIDEONE}where:
- OFF
Suppresses the title when there is only one display field.
- ON
Displays the title when there is only one display field.
- HIDEONE
Suppresses the title when there is only one display field,
but the request contains one or more of the following components:
- Fields in a heading or footing.
- Fields whose display is suppressed with the NOPRINT phrase.
- Reformatted fields (which are normally counted twice).
- A COMPUTE command referencing multiple fields.
This
is the default value
Example: Displaying or Suppressing a Single ACROSS Column Title
The
following request against the GGSALES data source has one display
field, DOLLARS. The ACRSVRBTITL parameter is OFF:
SET ACRSVRBTITL=OFF
TABLE FILE GGSALES
SUM DOLLARS AS Sales
ACROSS REGION
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
ENDSTYLE
END
On the output, there is no column title that indicates
what the number in each column represents:
Region
Midwest Northeast Southeast West
----------------------------------------------------
11514345 11494543 11781285 11674908
The
following is the same request with ACRSVRBTITL=ON:
SET ACRSVRBTITL=ON
TABLE FILE GGSALES
SUM DOLLARS AS Sales
ACROSS REGION
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
ENDSTYLE
END
On the output, the title Sales appears above each
field value in the ACROSS group:
Region
Midwest Northeast Southeast West
Sales Sales Sales Sales
----------------------------------------------------
11514345 11494543 11781285 11674908
Example: Hiding an ACROSS Title With HIDEONE
The
following request against the GGSALES data source has a display
field in the heading:
SET ACRSVRBTITL=OFF
TABLE FILE GGSALES
HEADING
"Sales Report for <CATEGORY with ACRSVRBTITL=OFF"
" "
SUM DOLLARS AS Sales
BY CATEGORY
ACROSS REGION
WHERE CATEGORY EQ 'Food'
ON TABLE SET PAGE NOPAGE
END
With the setting ACRSVRBTITL=OFF,
the field in the heading counts and the ACROSS title Sales is
not suppressed:
Sales Report for Food with ACRSVRBTITL=OFF
Region
Midwest Northeast Southeast West
Category Sales Sales Sales Sales
-------------------------------------------------------------
Food 4404483 4445197 4308731 4204333 Changing
ACRSVRBTITL to ON produces the same report:
Sales Report for Food with ACRSVRBTITL=ON
Region
Midwest Northeast Southeast West
Category Sales Sales Sales Sales
-------------------------------------------------------------
Food 4404483 4445197 4308731 4204333 Changing
ACRSVRBTITL to HIDEONE suppresses the ACROSS title Sales:
Sales Report for Food with ACRSVRBTITL=HIDEONE
Region
Midwest Northeast Southeast West
Category
-------------------------------------------------------------
Food 4404483 4445197 4308731 4204333
xSelecting and Assigning Column Titles to ACROSS Values
When you use the ACROSS COLUMNS phrase to select and
order the columns that display on the report output for an ACROSS
sort field, you can assign each selected column a new column title
using an AS phrase. This new column name will be for display only.
x
Syntax: How to Assign Column Titles to ACROSS Values
ACROSS sortfield [AS title]
COLUMNS aval1 [AS val1title] [{AND|OR} aval2 [AS val2title] [... {AND|OR} avaln [AS valntitle]]]where:
- sortfield
Is the ACROSS field name.
- title
Is the title for the ACROSS field name.
- AND|OR
Is required to separate the selected ACROSS values. AND and
OR are synonyms for this purpose.
- aval1, aval2,
... avaln
Are the selected ACROSS values to display on the report output.
- val1title, val2title,
...valntitle
Are the column titles for the selected ACROSS values.
x
Reference: Usage Notes for Assigning Column Titles to ACROSS Values
Example: Selecting and Assigning Column Titles to ACROSS Values
The following request against the GGSALES
data source selects the columns Coffee Grinder, Latte,
and Coffee Pot for the ACROSS field PRODUCT,
and assigns each of them a new column title.
TABLE FILE GGSALES
SUM
DOLLARS/I8M AS ''
BY REGION
ACROSS PRODUCT AS 'Products'
COLUMNS 'Coffee Grinder' AS 'Grinder'
OR Latte AS 'caffellatte'
AND 'Coffee Pot' AS 'Carafe'
ON TABLE SET PAGE NOPAGE
END
The output is:
Products
Region Grinder caffellatte Carafe
---------------------------------------------------------
Midwest $666,622 $2,883,566 $599,878
Northeast $509,200 $2,808,855 $590,780
Southeast $656,957 $2,637,562 $645,303
West $603,436 $2,670,405 $613,624
xApplying Summary Commands to Selected Fields in ACROSS Groups
When a request has multiple display fields and an ACROSS
sort field, the report output has multiple columns under each ACROSS
value. If you want to apply a summary field to some of the columns
for each ACROSS value, but not others, you can specify the field
names you want summarized. This technique is most useful for report requests
that use the OVER phrase to place the fields on separate rows.
x
Syntax: How to Apply Summary Commands to Selected Fields in ACROSS Groups
ACROSS acrossfield {SUBTOTAL|SUB-TOTAL|SUMMARIZE|RECOMPUTE} [field1 field2 ... fieldn]or
ACROSS acrossfield
ON acrossfield {SUBTOTAL|SUB-TOTAL|SUMMARIZE|RECOMPUTE} [field1 field2 ... fieldn]where:
- acrossfield
Is the sort field name.
- field1 field2 ... fieldn
Are the fields that will have the summary command applied.
If no fields are listed, all fields will be summarized.
x
Reference: Usage Notes for ACROSS Summary Commands
- Alphanumeric fields cannot be summarized.
- With ACROSS, summary columns only display at the end of the
ACROSS group (when the higher-level ACROSS field changes value).
- SUMMARIZE and SUB-TOTAL propagate their calculations to each
higher-level ACROSS field in the request.
- Different operations from two ON phrases for the same sort break
display in the same summary column, and allow a mixture of operations
on summary columns.
- If the same field is referenced in more than one ON phrase for
the same sort break, the last summary command specified is applied.
- You can specify a different summary operation for each sort
break.
- The SUMMARYLINES parameter does not affect processing for ACROSS
fields.
- When used with OVERs, the rows containing fields not to be summarized
will be blank.
- Prefix operators are supported on summary lines:
- The following prefix operators are supported for numeric fields:
ASQ., AVE., CNT., FST., LST., MAX., MIN., SUM.
- Prefix operators PCT., RPCT., and TOT. are not supported.
- Double prefix operators (such as PCT.CNT.) are not supported.
- The SUM. prefix operator produces the same summary values as
a summary phrase with no prefix operator.
- SUMMARIZE and RECOMPUTE apply the calculations defined in the
associated COMPUTE command to the summary values. Therefore, in
order to perform the necessary calculations, the SUMMARIZE or RECOMPUTE
command must specify all of the fields referenced in the COMPUTE
command.
- If the same field has summary operations with different prefix
operators at each level, the appropriate calculation is done at
each level for the prefix operator specified.
- SUB-TOTAL and SUMMARIZE propagate their operations to all higher-level
sort fields. If a request uses SUB-TOTAL or SUMMARIZE at multiple
sort levels, more than one prefix operator may apply to the same
field. When a SUB-TOTAL or SUMMARIZE command on a lower-level sort
field propagates up to the higher levels, it applies its prefix
operators only to those fields that did not already have a prefix operator
specified at the higher level. For any field that had a prefix operator specified
at a higher level, the original prefix operator is applied at the
level at which it was first specified.
- Prefix operators on summary lines result in the same values
whether the command is RECOMPUTE/SUMMARIZE or SUBTOTAL/SUB-TOTAL.
For a computed field, the prefix operator is not applied, and the
value is recalculated using the expression in the COMPUTE command
and the values from the summary line.
- If an ACROSS field has an ACROSS-TOTAL phrase and a summary
command with a prefix operator, the prefix operator is applied,
not the ACROSS-TOTAL.
Example: Subtotaling One Field Within an ACROSS Group
The following request against the GGSALES
data source sums the DOLLARS and UNITS fields by CATEGORY and across
REGION, but subtotals only the UNITS field.
TABLE FILE GGSALES
SUM DOLLARS AS 'Dollars' OVER
UNITS AS 'Units'
BY CATEGORY
ACROSS REGION SUBTOTAL UNITS
WHERE REGION EQ 'Midwest' OR 'West'
ON TABLE SET PAGE NOPAGE
END
The output shows that
only the rows with the UNITS values are subtotaled.
Region
Category Midwest West TOTAL
-------------------------------------------------------------
Coffee Dollars 4178513 4473517
Units 332777 356763 689540
Food Dollars 4338271 4202337
Units 341414 340234 681648
Gifts Dollars 2883881 2977092
Units 230854 235042 465896
Example: Summarizing a Calculated Value in an ACROSS Group
The
following request against the GGSALES data source sums the DOLLARS
and UNITS fields and calculates the dollars per unit (the DPERU
calculated value) across REGION. The request also has a higher-level
ACROSS field, CATEGORY, so the SUMMARIZE command propagates to both
ACROSS fields.
SET BYPANEL = ON
TABLE FILE GGSALES
SUM DOLLARS AS 'Dollars' UNITS AS 'Units'
AND COMPUTE DPERU/D9.2 = DOLLARS/UNITS;
ACROSS CATEGORY
ACROSS REGION
ON REGION SUMMARIZE DPERU
WHERE REGION EQ 'Midwest' OR 'West'
WHERE CATEGORY EQ 'Food' OR 'Gifts'
ON TABLE HOLD FORMAT PDF
END
The first panel of output shows:
- The values of DOLLARS, UNITS, and DPERU for the Midwest and
West regions under the Food category.
- The summary column, which has a value just for the DPERU row.
Note that for ACROSS, the summary column for REGION appears only
after the higher-level ACROSS field, CATEGORY, changes value.
- The values of DOLLARS, UNITS, and DPERU for the Midwest and
West regions under the Gifts category.
PAGE 1.1
Category
Food Gifts
Region
Midwest West TOTAL Midwest West
-------------------------------------------------------------------------
Dollars 4338271 4202337 2883881 2977092
Units 341414 340234 230854 235042
DPERU 12.71 12.35 12.53 12.49 12.67The second panel has the total column
for the Gifts category and the grand total column. Each of those
only has a value in the DPERU row.
PAGE 1.2
Category
TOTAL
Region
TOTAL
----------------------------------
Dollars
Units
DPERU 12.58 12.55
Example: Using Prefix Operators in a Summary Command With ACROSS
The
following request against the GGSALES data source sums the DOLLARS
and UNITS fields across CATEGORY and REGION, with a SUMMARIZE command
on the REGION field. The request also has a higher-level ACROSS
field, CATEGORY, so the SUMMARIZE command propagates to both ACROSS
fields. The SUMMARIZE command specifies the AVE. prefix operator
for the DOLLARS field.
SET BYPANEL = ON
TABLE FILE GGSALES
SUM DOLLARS AS 'Dollars' OVER
UNITS AS 'Units'
ACROSS CATEGORY
ACROSS REGION
ON REGION SUMMARIZE AVE. DOLLARS
WHERE REGION EQ 'Midwest' OR 'West'
WHERE CATEGORY EQ 'Food' OR 'Gifts'
ON TABLE HOLD FORMAT PDF
END
The first panel of output shows:
- The values of DOLLARS and UNITS for the Midwest and West regions
under the Food category.
- The summary column, which has a value just for the DOLLARS row.
Note that for ACROSS, the summary column for REGION appears only
after the higher-level ACROSS field, CATEGORY, changes value.
- The values of DOLLARS and UNITS for the Midwest and West regions
under the Gifts category.
PAGE 1.1
Category
Food Gifts
Region
Midwest West TOTAL Midwest West
-------------------------------------------------------------------------
Dollars 4338271 4202337 4270304 2883881 2977092
Units 341414 340234 230854 235042The second panel has the total column
for the Gifts category and the grand total column. Each of those
only has a value in the DOLLARS row.
PAGE 1.2
Category
TOTAL
Region
TOTAL
----------------------------------
Dollars 2930486 3600395
Units
Example: Using Combinations of ACROSS Summary Commands
The
following request against the GGSALES data source sums the DOLLARS
and UNITS fields across CATEGORY and REGION, with a SUMMARIZE command
on the REGION field and a SUBTOTAL command on the CATEGORY field.
The SUMMARIZE command specifies average DOLLARS and minimum UNITS.
The SUBTOTAL command specifies minimum DOLLARS.
SET BYPANEL = ON
TABLE FILE GGSALES
SUM DOLLARS AS 'Dollars' OVER
UNITS AS 'Units'
ACROSS CATEGORY
ACROSS REGION
ON CATEGORY SUBTOTAL MIN.DOLLARS
ON REGION SUMMARIZE AVE.DOLLARS MIN.UNITS
WHERE REGION EQ 'Midwest' OR 'West'
WHERE CATEGORY EQ 'Food' OR 'Gifts'
ENDOn the output, all of the TOTAL columns have the
minimum UNITS. The TOTAL columns associated with the REGION sort
field have the average DOLLARS, but the TOTAL column associated
with the CATEGORY sort field has the minimum DOLLARS because SUMMARIZE does
not change the prefix operator associated with a higher-level sort
field.
PAGE 1.1
Category
Food Gifts
Region
Midwest West TOTAL Midwest West
-------------------------------------------------------------------------
Dollars 4338271 4202337 4270304 2883881 2977092
Units 341414 340234 340234 230854 235042PAGE 1.2
Category
TOTAL
Region
TOTAL
----------------------------------
Dollars 2930486 2883881
Units 230854 230854
xDENSE and SPARSE Ranking of Sort Field Values
The FOCUS sort phrases
RANK BY and BY {HIGHEST|LOWEST} n sort the
report output and assign rank numbers to the sequence of data values.
When assigning a rank to a data value, by default, FOCUS does not skip rank numbers.
This means that even when multiple data values are assigned the
same rank, the rank number for the next group of values is the next
sequential integer. This method of assigning rank numbers is called dense.
Some of the relational engines assign rank numbers using a method
called sparse. With sparse ranking, if multiple
data values are assigned the same rank number, the next rank number
will be the previous rank number plus the number of multiples.
You can use the FOCUS RANK parameter
to control the type of ranking done by FOCUS.
In addition, if you are accessing a relational data source, you
can set the ranking method to the type of ranking done by your relational
engine so that the rank calculation can be optimized. Some relational
engines have functions for both dense and sparse ranking. In this
case, either setting can be optimized.
x
Reference: Optimizing Ranking
In
order to pass rank processing to a relational engine your request
must:
- Use the SUM (or WRITE or ADD) command to aggregate
values.
- Specify the number of rank categories to be displayed. That
is, you must specify a value for n:
[RANKED] BY [HIGHEST] n
x
Syntax: How to Control the Ranking Method
SET RANK={DENSE|SPARSE}where:
- DENSE
Specifies dense ranking. With this method, each rank number
is the next sequential integer, even when the same rank is assigned
to multiple data values. DENSE is the default value.
- SPARSE
Specifies sparse ranking. With this method, if the same rank
number is assigned to multiple data values, the next rank number
will be the previous rank number plus the number of multiples.
Then,
in your request, use one of the following forms of the BY phrase:
RANKED BY {HIGHEST|LOWEST} [n] sortfield [AS 'text']or
BY {HIGHEST|LOWEST} n sortfield [AS 'text']where:
- n
Is the highest rank number to display on the report output
when the RANKED BY phrase is used. When RANKED is not used, it is
the number of distinct sort field values to display on the report
output when SET RANK=DENSE, and the total number of lines of output
for the sort field when SET RANK=SPARSE.
- sortfield
Is the name of the sort field.
- text
Is the column heading to be used for the sort field column
on the report output.
x
Reference: Usage Notes for SET RANK
- The RNK. prefix operator is not affected by the RANK parameter.
- The rank numbers propagated to a HOLD file depend on the RANK
parameter setting.
Example: Ranking Values in a FOCUS Data Source
The following request against the EMPDATA
data source ranks salaries in descending order by division. The
RANK parameter is set to DENSE (the default).
SET RANK = DENSE
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME
RANKED BY HIGHEST 12 SALARY
BY DIV
ON TABLE SET PAGE NOPAGE
END
On the output, six employees
are included in rank number 6. With dense ranking, the next rank
number is the next highest integer, 7.
RANK SALARY DIV LASTNAME FIRSTNAME
---- ------ --- -------- ---------
1 $115,000.00 CE LASTRA KAREN
2 $83,000.00 CORP SANCHEZ EVELYN
3 $80,500.00 SE NOZAWA JIM
4 $79,000.00 CORP SOPENA BEN
5 $70,000.00 WE CASSANOVA LOIS
6 $62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
7 $58,800.00 WE GOTLIEB CHRIS
8 $55,500.00 CORP VALINO DANIEL
NE PATEL DORINA
9 $54,100.00 CE ADDAMS PETER
WE FERNSTEIN ERWIN
10 $52,000.00 NE LIEBER JEFF
11 $50,500.00 SE LEWIS CASSANDRA
12 $49,500.00 CE ROSENTHAL KATRINA
SE WANG KATERunning the same request with SET RANK=SPARSE
produces the following output. Since rank category 6 includes six
employees, the next rank number is 6 + 6.
RANK SALARY DIV LASTNAME FIRSTNAME
---- ------ --- -------- ---------
1 $115,000.00 CE LASTRA KAREN
2 $83,000.00 CORP SANCHEZ EVELYN
3 $80,500.00 SE NOZAWA JIM
4 $79,000.00 CORP SOPENA BEN
5 $70,000.00 WE CASSANOVA LOIS
6 $62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
12 $58,800.00 WE GOTLIEB CHRIS
Example: Limiting the Number of Sort Field Values
The following request against the EMPDATA
data source sorts salaries in descending order by division and prints
the 12 highest salaries. The RANK parameter is set to DENSE (the
default).
SET RANK = DENSE
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME
BY HIGHEST 12 SALARY
BY DIV
ON TABLE SET PAGE NOPAGE
END
On the output, 12 distinct
salary values are displayed, even though some of the employees have
the same salaries.
SALARY DIV LASTNAME FIRSTNAME
------ --- -------- ---------
$115,000.00 CE LASTRA KAREN
$83,000.00 CORP SANCHEZ EVELYN
$80,500.00 SE NOZAWA JIM
$79,000.00 CORP SOPENA BEN
$70,000.00 WE CASSANOVA LOIS
$62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
$58,800.00 WE GOTLIEB CHRIS
$55,500.00 CORP VALINO DANIEL
NE PATEL DORINA
$54,100.00 CE ADDAMS PETER
WE FERNSTEIN ERWIN
$52,000.00 NE LIEBER JEFF
$50,500.00 SE LEWIS CASSANDRA
$49,500.00 CE ROSENTHAL KATRINA
SE WANG KATERunning the same request with SET RANK=SPARSE
produces the following output. Since six employees have salary $62,500,
that value is counted 6 times so that only 12 lines (seven distinct
salary values) display on the output.
SALARY DIV LASTNAME FIRSTNAME
------ --- -------- ---------
$115,000.00 CE LASTRA KAREN
$83,000.00 CORP SANCHEZ EVELYN
$80,500.00 SE NOZAWA JIM
$79,000.00 CORP SOPENA BEN
$70,000.00 WE CASSANOVA LOIS
$62,500.00 CE ADAMS RUTH
CORP CVEK MARCUS
WANG JOHN
NE WHITE VERONICA
SE BELLA MICHAEL
HIRSCHMAN ROSE
$58,800.00 WE GOTLIEB CHRIS
Example: Optimizing RANK Processing
This
example will show that the RANKED BY phrase can be passed to DB2
for processing in a request. It uses the WebFOCUS Retail Demo database.
The following request contains a RANKED
BY phrase and a SET RANK=SPARSE command:
SET TRACEUSER = ON
SET TRACEOFF = ALL
SET TRACEON = STMTRACE//CLIENT
SET TRACESTAMP=OFF
SET XRETRIEVAL = OFF
SET RANK = SPARSE
TABLE FILE WFLITE
SUM REVENUE_US
RANKED BY HIGHEST 12 TIME_DATE
BY PRODUCT_CATEGORY
END
The trace output shows that the RANKED BY phrase
was passed to DB2 as a call to the DB2 RANK function.
SELECT
SK001,
SK002,
VB001
FROM (
SELECT
T4."TIME_DATE" AS SK001,
T7."PRODUCT_CATEGORY" AS SK002,
SUM(T1."REVENUE_US") AS VB001,
RANK() OVER( ORDER BY T4."TIME_DATE" DESC NULLS LAST) AS
RANK001
FROM
( ( USER1.w_wf_retail_sales T1
LEFT OUTER JOIN user1.w_wf_retail_time_lite T4
ON T4."ID_TIME" = T1."ID_TIME" )
LEFT OUTER JOIN USER1.w_wf_retail_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T4."TIME_DATE",
T7."PRODUCT_CATEGORY"
) X
WHERE
RANK001 <= 12
SELECT
SK001,
SK002,
VB001
FROM (
SELECT
T4."TIME_DATE" AS SK001,
T7."PRODUCT_CATEGORY" AS SK002,
SUM(T1."REVENUE_US") AS VB001,
RANK() OVER( ORDER BY T4."TIME_DATE" DESC NULLS LAST) AS
RANK001
FROM
( ( USER1.w_wf_retail_sales T1
LEFT OUTER JOIN user1.w_wf_retail_time_lite T4
ON T4."ID_TIME" = T1."ID_TIME" )
LEFT OUTER JOIN USER1.w_wf_retail_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T4."TIME_DATE",
T7."PRODUCT_CATEGORY"
) X
WHERE
RANK001 <= 12
FOR FETCH ONLY;
Running the
same request with a SET RANK=DENSE command produces the following trace
output. Since DB2 has a DENSE RANK function, the RANKED BY phrase
is passed as a call to this function.
SELECT
SK001,
SK002,
VB001
FROM (
SELECT
T4."TIME_DATE" AS SK001,
T7."PRODUCT_CATEGORY" AS SK002,
SUM(T1."REVENUE_US") AS VB001,
DENSE_RANK() OVER( ORDER BY T4."TIME_DATE" DESC NULLS LAST) AS
RANK001
FROM
( ( USER1.w_wf_retail_sales T1
LEFT OUTER JOIN user1.w_wf_retail_time_lite T4
ON T4."ID_TIME" = T1."ID_TIME" )
LEFT OUTER JOIN USER1.w_wf_retail_product T7
ON T7."ID_PRODUCT" = T1."ID_PRODUCT" )
GROUP BY
T4."TIME_DATE",
T7."PRODUCT_CATEGORY"
) X
WHERE
RANK001 <= 12
FOR FETCH ONLY;
xAdding a New Fact To Multi-Fact Synonyms: JOIN AS_ROOT
The JOIN AS_ROOT command adds a new fact table as an
additional root to an existing fact-based cluster (star schema).
The source Master File has a parent fact segment and at least one
child dimension segment. The JOIN AS_ROOT command supports a unique
join from a child dimension segment (at any level) to an additional
fact parent.
x
Syntax: How to Add an Additional Parent Segment
JOIN AS_ROOT sfld1 [AND sfld2 ...] IN [app1/]sfile TO UNIQUE tfld1 [AND tfld2 ...] IN [app2/]tfile AS jname
END
where:
- sfld1 [AND sfld2 ...]
Are fields in the child (dimension) segment of the source
file that match values of fields in the target file.
- [app1/]sfile
Is the source file.
- TO UNIQUE tfld1 [AND tfld2 ...]
Are fields in the target file that match values of fields
in the child segment of the source file. The join must be unique.
- [app2/]tfile
Is the target file.
- jname
Is the join name.
- END
Is required to end the JOIN command.
Example: Joining AS_ROOT From the WebFOCUS Retail Data Source to an Excel File
The
following request joins the product category and product subcategory
fields in the WebFOCUS Retail data source to a table named PROJECTD.
The Master File for the PROJECTD table
is:
FILENAME=PROJDB2 , SUFFIX=DB2 , $
SEGMENT=SEG01, SEGTYPE=S0, $
FIELDNAME=PRODUCT_CATEGORY, ALIAS='Product Category', USAGE=A16,
ACTUAL=A16, MISSING=ON, TITLE='Product Category',
WITHIN='*PRODUCT',$
FIELDNAME=PRODUCT_SUBCATEGORY, ALIAS='Product Subcategory',USAGE=A25,
ACTUAL=A25, MISSING=ON, TITLE='Product Subcategory',
WITHIN=PRODUCT_CATEGORY, $
FIELDNAME=PROJECTED_COG, ALIAS=' Projected COG', USAGE=D12,
ACTUAL=D8, MISSING=ON,
TITLE=' Projected COG', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
FIELDNAME=PROJECTED_SALE_UNITS, ALIAS=' Projected Sale.Units',
USAGE=I9, ACTUAL=I4, MISSING=ON,
TITLE=' Projected Sale Units', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
DIMENSION=PRODUCT, CAPTION='Product', $
HIERARCHY=PRODUCT, CAPTION='Product', HRY_DIMENSION=PRODUCT, $
MEASUREGROUP=PROJECTED, $ The following image shows the data in
the PROJECTD table.
Product Category Product Subcategory Projected COG Projected
Sale_Units
---------------- ------------------- -------------- -----------
Accessories Charger 2,068,508 75279
Accessories Headphones 52,061,301 163152
Accessories Universal Remote Controls 36,297,267 127286
Camcorder Handheld 20,733,053 178704
Camcorder Professional 35,440,708 9095
Camcorder Standard 49,442,067 137489
Computers Smartphone 44,420,201 146858
Computers Tablet 26,047,885 105053
Media Player Blu Ray 182,459,862 485131
Media Player DVD Players 3,756,254 13346
Media Player DVD Players - Portable 306,576 3981
Media Player Streaming 5,108,342 48630
Stereo Systems iPod Docking Station 26,310,783 221723
Stereo Systems Boom Box 840,373 6687
Stereo Systems Home Theater Systems 56,829,817 285041
Stereo Systems Receivers 40,620,030 107537
Stereo Systems Speaker Kits 81,962,756 174036
Televisions CRT TV 1,928,416 3268
Televisions Flat Panel TV 59,540,624 66119
Televisions Portable TV 545,348 5696
Video Production Video Editing 40,380,803 142594The following request joins from the
WF_RETAIL_PRODUCT segment of the WFLITE data source to the PROJECTD
table as a new root and reports from both parent segments:
JOIN AS_ROOT PRODUCT_CATEGORY AND PRODUCT_SUBCATEG IN WFLITE
TO UNIQUE PRODUCT_CATEGORY AND PRODUCT_SUBCATEGORY IN PROJECTD
AS J1.
END
TABLE FILE WFLITE
SUM PROJECTED_SALE_UNITS REVENUE_US
BY PRODUCT_CATEGORY
ON TABLE SET PAGE NOPAGE
END
The output is:
Product
Category Projected Sale Units Revenue
-------- --------------------- -------
Accessories 365717 $499,551.40
Camcorder 325288 $667,254.48
Computers 251911 $179,761.46
Media Player 551088 $1,009,790.56
Stereo Systems 795024 $1,216,393.89
Televisions 75083 $286,160.68
Video Production 142594 $259,179.84
xJoining From a Multi-Fact Synonym
Multi-parent synonyms are now supported as the source
for a join to a single segment in a target synonym.
A join from a multi-parent synonym is
subject to the following conditions:
- Conditional joins are not supported (JOIN WHERE).
- The join must be unique. That is, the TO ALL phrase is not supported.
- The target of the join cannot be a multi-parent synonym.
- The target of the JOIN must be a single segment, either in a
single segment synonym or one segment in a single parent, multi-segment
synonym.
- All fields in the JOIN must be FROM/TO a single segment. Any
single segment in the source synonym can be used in the join.
Example: Joining From a Multi-Fact Synonym
The following Master File describes
a multi-parent structure based on the WebFOCUS Retail tutorial.
The two fact tables wf_retail_sales and wf_retail_shipments are
parents of the dimension table wf_retail_product.
FILENAME=WFMULTI, $
SEGMENT=WF_RETAIL_SHIPMENTS, CRFILE=SHIPMENT, CRINCLUDE=ALL,
DESCRIPTION='Shipments Fact', $
SEGMENT=WF_RETAIL_SALES, PARENT=., CRFILE=SALES, CRINCLUDE=ALL,
DESCRIPTION='Sales Fact', $
SEGMENT=WF_RETAIL_PRODUCT, CRFILE=PRODUCT, CRINCLUDE=ALL,
DESCRIPTION='Product Dimension', $
PARENT=WF_RETAIL_SHIPMENTS, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SHIPMENTS.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $
PARENT=WF_RETAIL_SALES, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SALES.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $The following request joins the product
segment to the dimension table wf_retail_vendor based on the vendor
ID and issues a request against the joined structure:
JOIN ID_VENDOR IN WFMULTI TO ID_VENDOR IN WF_RETAIL_VENDOR AS J1
TABLE FILE WFMULTISUM COGS_US DAYSDELAYED
BY PRODUCT_CATEGORY
BY VENDOR_NAME
WHERE PRODUCT_CATEGORY LT 'S'
ON TABLE SET PAGE NOPAGE
END
The output is:
Product Days
Category Vendor Name Cost of Goods Delayed
-------- ----------- ------------- -------
Accessories Audio Tech $38,000.00 28
Denon $25,970.00 17
Grado $21,930.00 15
Logitech $61,432.00 114
Niles Audi $73,547.00 150
Pioneer $16,720.00 71
Samsung $5,405.00 83
Sennheiser $78,113.00 128
Sony $21,760.00 157
Camcorder Canon $110,219.00 97
JVC $72,292.00 75
Panasonic $22,356.00 91
Sanyo $31,590.00 179
Sony $216,748.00 333
Computers Samsung $33,129.00 156
Sony $76,152.00 186
Media Player JVC $87,057.00 267
LG $3,830.00 13
Panasonic $143,600.00 171
Pioneer $169,810.00 206
Roku $10,248.00 85
Samsung $151,620.00 191
Sharp $66,024.00 157
Sony $142,190.00 121
Toshiba $5,214.00 7
xImproved Handling of a Star Schema With Fan Trap
When a star schema contains a segment with aggregated
facts and a lower-level segment with the related detail-level facts,
a request that performs aggregation on both levels and returns them
sorted by the higher level can experience the multiplicative effect.
This means that the fact values that are already aggregated may
be re-aggregated and, therefore, return multiplied values.
When the adapter detects the multiplicative effect, it turns
optimization off in order to handle the request processing and circumvent
the multiplicative effect. However, performance is degraded when
a request is not optimized.
A new context analysis process has been introduced in this release
that detects the multiplicative effect and generates SQL script
commands that retrieve the correct values for each segment context.
These scripts are then passed to the RDBMS as subqueries in an optimized
SQL statement.
To activate the context analysis feature, issue the following
command:
ENGINE INT SET FCA = ON
xHierarchical Reporting: BY HIERARCHY
Cube data sources such as Essbase or SAP BW are organized
into dimensions and facts. Dimensions are often organized into hierarchies.
The synonyms for cube data sources have attributes that describe
the dimension hierarchies, and FOCUS
has hierarchical reporting syntax that can automatically report against
these hierarchies and display the results indented to show the hierarchical relationships.
FOCUS also supports defining
dimension hierarchies in synonyms for non-cube data sources that
have hierarchical data. Once hierarchical dimensions are defined
in a synonym, you can issue hierarchical reporting requests against
them. Non-cube synonyms with hierarchical attributes are called virtual
cubes.
Dimensions are categories of data, such as Region or Time, that
you use to analyze and compare business performance. Dimensions
consist of data elements that are called members. For example, a
Region dimension could have members England and France.
Dimension members are usually organized into hierarchies. Hierarchies
can be viewed as tree-like structures where members are the nodes.
For example, the Region dimension may have the element World at
its top level (the root node). The World element may have children
nodes (members) representing continents. Continents, in turn, can
have children nodes that represent countries, and countries can
have children nodes representing states or cities. Nodes with no
children are called leaf nodes.
Measures are numeric values, such as Sales Volume or Net Income,
that are used to quantify how your business is performing.
A cube consists of data derived from facts, which are records
about individual business transactions. For example, an individual
fact record reflects a sales transaction of a certain number of
items of a certain product at a certain price, which occurred in
a certain store at a certain moment in time. The cube contains summarized
fact values for all combinations of measures and members of different
dimensions.
A synonym describes a hierarchy using a set of fields that define
the hierarchical structure and the relationships between the hierarchy
members. FOCUS has special hierarchical
reporting syntax for reporting on hierarchies.
Hierarchical reporting requests have
several phases:
-
Phase 1, selecting hierarchy members to display.
The
hierarchical reporting phrase BY or ON HIERARCHY automatically sorts
and formats a hierarchy with appropriate indentations that show
the parent/child relationships. It also automatically rolls up the
measure values for child members to generate the measure values
for the parent members.
If you do not want to see the entire
hierarchy, you can use the WHEN phrase to select hierarchy members
for display. The expression in this WHEN phrase must reference only
hierarchy fields, not dimension properties or measures.
-
Phase 2, screening the retrieved dimension data.
WHERE
criteria are applied to the leaf nodes of the members selected during phase
1. Therefore, dimension properties can be used in WHERE tests. These
tests can also reference hierarchy fields. However, since the selection
criteria are always applied to the values at the leaf nodes, they
cannot select data based on values that occur at higher levels.
For example, in a dimension with Continents, Countries, and Cities,
your request will not display any rows if you use WHERE to select
at the Country level, but it may if you use it to select at the
City level. WHERE tests can also reference measures.
-
Phase 3, screening based on aggregated values.
Measures,
being summarized values, can be referenced in WHERE TOTAL tests and
COMPUTE commands because those commands are processed after the
hierarchy selection and aggregation phases of the request.
x
Syntax: How to Specify a Hierarchy in a Master File
The data source must have at least one
dimension that is organized hierarchically. The declaration for
a dimension is:
DIMENSION=dimname,CAPTION=dimcaption, $
where:
- dimname
Is a name for the dimension.
- dimcaption
Is a label for the dimension.
The declaration for a hierarchy within
the dimension is:
HIERARCHY=hname,CAPTION='hcaption',HRY_DIMENSION=dimname,
HRY_STRUCTURE=RECURSIVE, $
where:
- hname
Is a name for the hierarchy.
- hcaption
Is a label for the hierarchy.
- dimname
Is the name of the dimension for which this hierarchy is defined.
Several fields are used to define a
parent/child hierarchy. Each has a PROPERTY attribute that describes
which hierarchy property it represents. Each hierarchy must have
a unique identifier field. This field is called the hierarchy field.
If the synonym represents a FOCUS data source, this field must be
indexed (FIELDTYPE=I). The declaration for the hierarchy field is:
FIELD=hfield,ALIAS=halias,USAGE= An, [ACTUAL=Am,] WITHIN='*hierarchy',PROPERTY=UID, [TITLE='title1',] [FIELDTYPE=I,] $
where:
- hfield
Is the field name for the hierarchy field.
- halias
Is the alias for the hierarchy field. If the data source
is relational, this must be the name of the column in the Relational
DBMS.
- hierarchy
Is the name of the hierarchy to which this field belongs.
- USAGE= An, [ACTUAL=Am,]
Are the USAGE format and, if the data source is not a FOCUS
data source, the ACTUAL format of the field.
- title1
Is an optional title for the field.
Other
fields defined for the hierarchy include the parent field and the
caption field. Each of these fields has the same name as the hierarchy
field with a suffix added. Each has a PROPERTY attribute that specifies
its role in the hierarchy and a REFERENCE attribute that points
to the corresponding hierarchy field.
The
following is the declaration for the parent field. The parent field
is needed to define the parent/child relationships in the hierarchy:
FIELD=hfield_PARENT,ALIAS=parentalias,USAGE=An,[ACTUAL=Am,] [TITLE=ptitle,]
PROPERTY=PARENT_OF, REFERENCE=hfield, $where:
- hfield
Is the hierarchy field.
- parentalias
Is the alias for the parent field. If the data source is
relational, this must be the name of the column in the relational
DBMS.
- USAGE= An, [ACTUAL=Am,]
Are the USAGE format and, if the data source is not a FOCUS
data source, the ACTUAL format of the field.
- ptitle
Is a column title for the parent field.
The
following is the declaration for the caption field. A caption is
a descriptive title for each value of the hierarchy field. It is
part of the data and, therefore, is different from a TITLE attribute
in the Master File, which is a literal title for the column on the
report output.
FIELD=hfield_CAPTION,ALIAS=capalias,USAGE=Ann,[ACTUAL=Amm,] [TITLE=captitle,]
PROPERTY=CAPTION, REFERENCE=hfield, $where:
- hfield
Is the hierarchy field.
- capalias
Is the alias for the caption field. If the data source is
relational, this must be the name of the column in the relational
DBMS.
- USAGE= Ann, [ACTUAL=Amm,]
Are the USAGE format and, if the data source is not a FOCUS
data source, the ACTUAL format of the field.
- captitle
Is a column title for the caption field.
Example: Sample Master File With a Dimension Hierarchy
The following Master File is based on
the CENTGL Master File, which has an FML hierarchy defined. This
version is named NEWGL and it has a dimension hierarchy of accounts
in which GL_ACCOUNT is the hierarchy field, GL_ACCOUNT_PARENT is
the parent field, and GL_ACCOUNT_CAPTION is the caption field. There
are other fields based on the hierarchy (GL_ACCOUNT_LEVEL, GL_ROLLUP_OP,
and GL_ACCOUNT_TYPE). In addition, there is a measure field (GL_ACCOUNT_AMOUNT):
FILE=NEWGL ,SUFFIX=FOC,$
SEGNAME=ACCOUNTS ,SEGTYPE=S01
DIMENSION=Accnt,CAPTION=Accnt, $
HIERARCHY=Accnt,CAPTION='Accnt',HRY_DIMENSION=Accnt,
HRY_STRUCTURE=RECURSIVE, $
FIELD=GL_ACCOUNT,GLACCT,A7,WITHIN='*Accnt',PROPERTY=UID,
TITLE='Ledger,Account', FIELDTYPE=I, $
FIELD=GL_ACCOUNT_PARENT,GLPAR,A7, TITLE=Parent,
PROPERTY=PARENT_OF, REFERENCE=GL_ACCOUNT, $
FIELD=GL_ACCOUNT_TYPE,GLTYPE,A1, TITLE=Type,$
FIELD=GL_ROLLUP_OP,ROLL,A1, TITLE=Op, $
FIELD=GL_ACCOUNT_LEVEL,GLLEVEL,I3, TITLE=Lev, $
FIELDNAME=GL_ACCOUNT_AMOUNT,GLAMT,D12.2, TITLE=Amount, $
FIELD=GL_ACCOUNT_CAPTION,GLCAP,A30, TITLE=Caption,
PROPERTY=CAPTION, REFERENCE=GL_ACCOUNT, $
FIELD=SYS_ACCOUNT,ALINE,A6, TITLE='System,Account,Line', MISSING=ON, $The following procedure loads data into
this data source, as long as the Master File is available to FOCUS (on the path or allocated):
CREATE FILE NEWGL NOMSG
-RUN
MODIFY FILE NEWGL
COMPUTE TGL_ACCOUNT_LEVEL/A3=;
COMPUTE TGL_ACCOUNT_AMOUNT/A12=;
FIXFORM GL_ACCOUNT/A4B X3 GL_ACCOUNT_PARENT/A4B X3 GL_ACCOUNT_TYPE/A1B
FIXFORM SYS_ACCOUNT/A4B GL_ROLLUP_OP/A1B
FIXFORM TGL_ACCOUNT_LEVEL/A3B GL_ACCOUNT_CAPTION/A30B
FIXFORM TGL_ACCOUNT_AMOUNT/A12B
COMPUTE GL_ACCOUNT_LEVEL = EDIT(TGL_ACCOUNT_LEVEL);
COMPUTE GL_ACCOUNT_AMOUNT = ATODBL(TGL_ACCOUNT_AMOUNT , '12', GL_ACCOUNT_AMOUNT);
MATCH GL_ACCOUNT
ON MATCH REJECT
ON NOMATCH INCLUDE
DATA
1000 R. + 1Profit Before Tax
2000 1000 R. + 2Gross Margin
2100 2000 R. + 3Sales Revenue
2200 2100 R. + 4Retail Sales
2210 2200 R7001+ 5Retail - Television 505.00
2220 2200 R7002+ 5Retail - Stereo 505.00
2230 2200 R7003+ 5Retail - Video Player 505.00
2240 2200 R7004+ 5Retail - Computer 505.00
2250 2200 R7005+ 5Retail - Video Camera 505.00
2300 2100 R. + 4Mail Order Sales
2310 2300 R7011+ 5Mail Order - Television 505.00
2320 2300 R7012+ 5Mail Order - Stereo 505.00
2330 2300 R7013+ 5Mail Order - Video Player 505.00
2340 2300 R7014+ 5Mail Order - Computer 505.00
2350 2300 R7015+ 5Mail Order - Video Camera 505.00
2400 2100 R. + 4Internet Sales
2410 2400 R7021+ 5Internet - Television 505.00
2420 2400 R7022+ 5Internet - Stereo 505.00
2430 2400 R7023+ 5Internet - Video Player 505.00
2440 2400 R7024+ 5Internet - Computer 505.00
2450 2400 R7025+ 5Internet - Video Camera 505.00
2500 2000 E. - 3Cost Of Goods Sold
2600 2500 E. + 4Variable Material Costs
2610 2600 E7101+ 5Television COGS 505.00
2620 2600 E7102+ 5Stereo COGS 505.00
2630 2600 E7103+ 5Video COGS 505.00
2640 2600 E7104+ 5Computer COGS 505.00
2650 2600 E7105+ 5Video Camera COGS 505.00
2700 2500 E7111+ 4Direct Labor 404.00
2800 2500 E7112+ 4Fixed Costs 404.00
3000 1000 E. - 2Total Operating Expenses
3100 3000 E. + 3Selling Expenses
3110 3100 E. + 4Advertising
3112 3110 E7202+ 5TV/Radio 505.00
3114 3110 E7203+ 5Print Media 505.00
3116 3110 E7206+ 5Internet Advertising 505.00
3120 3100 E7212+ 4Promotional Expenses 404.00
3130 3100 E7213+ 4Joint Marketing 404.00
3140 3100 E7214+ 4Bonuses/Commisions 404.00
3200 3000 E. + 3General + Admin Expenses
3300 3200 E. + 4Salaries-Corporate
3310 3300 E7301+ 5Salaries-Corp Mgmt 505.00
3320 3300 E7302+ 5Salaries-Administration 505.00
3330 3300 E7303+ 5IT Contractors 505.00
3400 3200 E. + 4Company Benefits
3410 3400 E7311+ 5Social Security 505.00
3420 3400 E7312+ 5Unemployment 505.00
3430 3400 E7313+ 5Vacation Pay 505.00
3440 3400 E7314+ 5Sick Pay 505.00
3450 3400 E. + 5Insurances
3451 3450 E7321+ 6Medical Insurance 606.00
3452 3450 E7322+ 6Dental Insurance 606.00
3453 3450 E7323+ 6Pharmacy Insurance 606.00
3454 3450 E7324+ 6Disability Insurance 606.00
3455 3450 E7325+ 6Life Insurance 606.00
3500 3200 E. + 4Depreciation Expenses
3510 3500 E7411+ 5Equipment 505.00
3520 3500 E7412+ 5Building 505.00
3530 3500 E7413+ 5Vehicles 505.00
3600 3200 R7414- 4Gain/(Loss) Sale of Equipment 404.00
3700 3200 E. + 4Leasehold Expenses
3710 3700 E7421+ 5Equipment 505.00
3720 3700 E7422+ 5Buildings 505.00
3730 3700 R7429- 5Sub-Lease Income 505.00
3800 3200 E7440+ 4Interest Expenses 404.00
3900 3200 E. + 4Utilities
3910 3900 E7451+ 5Electric 505.00
3920 3900 E7452+ 5Gas 505.00
3930 3900 E7453+ 5Telephone 505.00
3940 3900 E7454+ 5Water 505.00
3950 3900 E7455+ 5Internet Access 505.00
5000 1000 E. - 2Total R+D Costs
5100 5000 E7511+ 3Salaries 303.00
5200 5000 E7521+ 3Misc. Equipment 303.00
END
x
Syntax: How to Report on a HIerarchy
In hierarchical reporting, measure values
for child dimension members will be rolled up to generate the parent
values. In the data source, the parent members should not have values
for the measures.
SUM measure_field ...
BY hierarchy_field [HIERARCHY [WHEN expression_using_hierarchy_fields;]
[SHOW [TOP|UP n] [TO {BOTTOM|DOWN m}] [byoption [WHEN condition] ...] ]
[WHERE expression_using_dimension_data]
[ON hierarchy_field HIERARCHY [WHEN expression_using_hierarchy_fields;]
[SHOW [TOP|UP n] [TO BOTTOM|DOWN m] [byoption [WHEN condition] ...]]where:
- measure_field
Is the field name of a measure.
- BY hierarchy_field HIERARCHY
Identifies the hierarchy used for sorting. The field must
be a hierarchy field.
- ON hierarchy_field HIERARCHY
Identifies the hierarchy used for sorting. The field must
be a hierarchy field. The request must include either a BY phrase
or a BY HIERARCHY phrase for this field name.
- WHEN expression_using_hierarchy_fields;
Selects hierarchy members. The WHEN phrase must immediately
follow the word HIERARCHY to distinguish it from a WHEN phrase associated
with a BY option (such as SUBFOOT). Any expression using only hierarchy
fields is supported. The WHEN phrase can be on the BY HIERARCHY
command or the ON HIERARCHY command, but not both.
- SHOW
Specifies which levels to show on the report output relative
to the levels selected by the WHEN phrase. If there is no WHEN phrase,
the SHOW option is applied to the root node of the hierarchy. The
SHOW option can be specified on the BY HIERARCHY phrase or the ON
HIERARCHY phrase, but not both.
- n
Is the number of ascendants above the set of selected members
that will have measure values. All ascendants appear on the report
to show the hierarchical context of the selected members. However,
ascendants that are not included in the SHOW phrase appear on the
report with missing data symbols in the report columns that display
measures. The default for n is 0.
- TOP
Specifies that ascendant levels to the root node of the hierarchy
will be populated with measure values.
- TO
Is required when specifying a SHOW option for descendant
levels.
- BOTTOM
Specifies all descendants to the leaf nodes of the hierarchy
will be populated with measure values. This is the default value.
- m
Is the number of descendants of each selected level that
will display. The default for m is BOTTOM, which displays
all descendants.
- byoption
Is one of the following sort-based options: PAGE-BREAK, REPAGE,
RECAP, RECOMPUTE, SKIP-LINE, SUBFOOT, SUBHEAD, SUBTOTAL, SUB-TOTAL,
SUMMARIZE, UNDER-LINE. If you specify SUBHEAD or SUBFOOT, you must
place the WHEN phrase on the line following the heading or footing
text.
- condition
Is a logical expression.
- expression_using_dimension_data
Screens the rows selected in the BY/ON HIERARCHY and WHEN
phrases based on dimension data. The expression can use dimension
properties and hierarchy fields. However, the selection criteria
are always applied to the values at the leaf nodes. Therefore, you
cannot use WHERE to select rows based on hierarchy field values
that occur at higher levels. For example, in a dimension with Continents,
Countries, and Cities, your request will not display any rows if
you use WHERE to select a Country name, but it may if you use it
to select a City name.
Example: Reporting on a Dimension HIerarchy
The following request reports on the
entire GL_ACCOUNT hierarchy for the CENTGL2 data source created
in How to Specify a Hierarchy in a Master File.
TABLE FILE NEWGL
SUM GL_ACCOUNT_AMOUNT
BY GL_ACCOUNT HIERARCHY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=REPORT,GRID=OFF,$
ENDSTYLE
END
Partial output is shown
in the following image. The accounts are indented to show the hierarchical
relationships:

The
following is the same request using the GL_ACCOUNT_CAPTION field:
TABLE FILE NEWGL
SUM GL_ACCOUNT_AMOUNT
BY GL_ACCOUNT_CAPTION HIERARCHY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=REPORT,GRID=OFF,$
ENDSTYLE
END
Partial output is shown
in the following image:

Example: Using WHEN to Select Hierarchy Members
The following request selects certain
accounts using the WHEN phrase and populates one level up and one
level down from the selected nodes with values. Note that all levels
to the root node display on the output for context, but if they
are not in the members selected, they are not populated with measure
values:
TABLE FILE NEWGL
SUM GL_ACCOUNT_AMOUNT
BY GL_ACCOUNT_CAPTION HIERARCHY
WHEN GL_ACCOUNT GT '2000' AND GL_ACCOUNT LT '3000';
SHOW UP 1 TO DOWN 1
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=REPORT,GRID=OFF,$
ENDSTYLE
END
The output is shown in
the following image:

Example: Using WHERE to Screen Selected Hierarchy Members
The following request selects members
using the WHEN phrase and then screens the output by applying a
WHERE phrase to the selected members:
TABLE FILE NEWGL
SUM GL_ACCOUNT_AMOUNT GL_ACCOUNT_TYPE
BY GL_ACCOUNT HIERARCHY
WHEN GL_ACCOUNT NE '3000';
SHOW UP 0 TO DOWN 0
WHERE GL_ACCOUNT_TYPE NE 'E' ;
ON TABLE SET PAGE NOLEAD
ON TABLE SET STYLE *
TYPE=REPORT, GRID=OFF,$
ENDSTYLE
END
The output is shown in
the following image:
