Configuring FOCUS for National Language Support (NLS) Services
In this section: Reference: |
NLS services enable FOCUS to support many different
languages. Each supported language has an associated code page.
In FOCUS, the mapping of graphic characters from one code page into
the graphic characters of another is managed by the FOCUS NLS translation component.
FOCUS comes with the Transcoding Services Generation Utility
(TSGU) program that you execute to generate the NLS transcoding
table file based on the code page list of your site.
Note: NLS is only supported if your terminal emulator
is IBM Personal Communications (PC3270).
You can customize your NLS FOCUS configuration
to:
Note: Customization of your NLS configuration is only
necessary if your enterprise requires support for alternate or additional
code pages, or custom monocasing and sorting.
x
Reference: Overview of Steps for Configuring Code Page Settings
You must perform the following steps
to change your code page configuration:
- Review your current code
page list and decide whether you need alternate or additional code
pages.
- Update the code page generation list of your site with the code
page information required for those alternate or additional code
pages.
- If you need to change any of the code pages to conform to the
requirements of your site or for the purpose of monocasing or sorting,
edit the appropriate code page definition files.
- Add an allocation for DDNAME NLS to the FOCUS CLIST, and start
FOCUS.
- Generate the new transcoding tables based on the updated code
page generation list.
- If you generated a new FOCUS code page in step 5, configure
FOCUS to use the new code page and/or language.
x
Reference: NLS Configuration Files
The
following table describes the NLS configuration files distributed with
FOCUS 7.7:
|
Member
|
Data Set
|
Description and Use
|
|---|
|
CPCODEPG
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Description: Code page generation
list. This file is a list of currently active code pages.
Use: You
must update this file in order to change your NLS configuration.
|
|
CPCPALL
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Description: List of language codes
and associated code pages.
Use: This file is a reference
file containing a list of language codes and code pages for all
languages supported for use with FOCUS.
|
|
CPnnnnn
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Description: Code page definition file.
This file contains information on each code point value in the code
page. There is a code page definition file for every code page listed
in the known code page file (cpxcptbl).
Use: This
file will not be updated unless you want to change any character
within the code page character definitions.
|
|
CPXCPTBL
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Description: Known code page list.
This file contains a list of enabled code pages for Information
Builders products.
Use: This file is a reference file
for finding alternate or additional code pages to add to CPCODEPG.
|
|
NLSCFG
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Description: NLS configuration file.
Use: This
file will be updated if you change the FOCUS code page setting and
the language FOCUS uses for error messages.
|
The following table describes the NLS configuration
files created by the TSGU (the utility that generates the tables
required for your NLS configuration):
|
Member
|
Data Set
|
Description
|
|---|
|
CASETBL
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Monocasing table. This file contains the
monocasing tables, which are generated using the TSGU and are based
on the code page generation list (CPCODEPG).
|
|
SORTTBL
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Sorting table. This file contains
the sorting tables, which are generated using the TSGU and are based
on the contents of the code page generation list (CPCODEPG).
|
|
TRANTBL
|
Alias Lib. install_hlq.ERRNLS.DATA
Physical
Lib. install_hlq.HOME.ERR
|
Transcoding table. This file contains the
transcoding tables, which are generated using the TSGU and are based
on the contents of the code page generation list (CPCODEPG).
|
xConfiguring New or Alternate Code Pages for FOCUS
Code page settings are reflected in the code page generation
list file install_hlq.ERRNLS.DATA(CPCODEPG). This file contains
code page settings for FOCUS and it is used by the TSGU to generate
the transcoding tables. To identify your current code page settings,
view the code page generation list file (CPCODEPG).
During the FOCUS installation, FOCUS is set up by default with
the US EBCDIC code page 37. The code page configuration for FOCUS
is set up to support the following default code pages:
- CP00037 E SBCS US IBM MF EBCDIC code
- CP00437 A SBCS US PC ASCII code
- CP00137 A SBCS ANSI Character Set for MS-Windows
- CP01047 E SBCS IBM MF Open Systems (Latin 1)
- CP65001 A UTF8 Unicode (UTF-8)
You can add additional code pages to this configuration, replace
existing code pages with alternates, or change the properties in
a code page file to conform to the standards of your site or to modify
the monocasing or sorting properties of the code page.
x
Procedure: How to Configure a New Code Page for FOCUS
The code page generation list file, install_hlq.ERRNLS.DATA(CPCODEPG),
is a list of code pages to generate with the TSGU. You must change
this file manually, using an editor, to contain the additional or
alternate set of code page numbers you need. You copy the code page
information from the list in the known code page file, install_hlq.ERRNLS.DATA(CPXCPTBL).
-
Review your code page configuration requirements.
-
Copy additional or alternate code pages into CPCODEPG
from the known code page file, CPXCPTBL.
Add the information for each additional or alternate code
page on a separate line. Note that only the characters CP and the
code page number (for example, CP00280) are required to generate
the new transcoding tables. The maximum number of code page entries
in the file is 16.
-
Open the known code page file, member CPXCPTBL in
the alias library install_hlq.ERRNLS.DATA.
The following is a portion of the CPXCPTBL file that contains
the code page information for the Italian code page 280 (CP00280):
CP00280 E SBCS IBM MF Italy
CP00281 E SBCS IBM MF Japanese English
CP00284 E SBCS IBM MF Spain/Latin America
CP00285 E SBCS IBM MF United Kingdom
For
a description of all of the fields in CPXCPTBL, see Structure of the Known Code Page File (CPXCPTBL).
-
Copy the lines for the additional or alternate code
pages you need from member CPXCPTBL to member CPCODEPG.
For example, to add the Italian code page 280 to your configuration,
copy the following line from CPXCPTBL to CPCODEPG:
CP00280 E SBCS IBM MF Italy
If
you started with the default CPCODEPG FILE, the new version will
contain the following information:
CP00037 E SBCS US IBM MF EBCDIC cod
CP00437 A SBCS US PC ASCII code
CP00137 A SBCS ANSI Character Set for MS-Windows
CP01047 E SBCS IBM MF Open Systems (Latin 1)
CP65001 A UTF8 Unicode (UTF-8)
CP00280 E SBCS IBM MF Italy
Note: If
the desired code page is not listed in the known code page file (CPXCPTBL),
refer to the appropriate IBM Character Data Representation Architecture (CDRA)
document and create your own, or contact your local Information
Builders representative for information about additional code pages.
-
If you require customized monocasing or sorting for one
or more of your configured code pages, edit the code page definition
file for those code pages as described in Configuring Customized FOCUS NLS Monocasing and Configuring Customized FOCUS NLS Sort Sequences.
-
Add the allocation for the NLS DDNAME to the FOCUS 7.7
CLIST that was created during the ISETUP installation process, and
start FOCUS.
-
Add the allocation for DDNAME NLS to the
FOCUSC CLIST.
ISETUP creates a CLIST named FOCUSC in the install_hlq.CONF.DATA
library. This CLIST allocates all of the required libraries for
executing FOCUS using the high-level qualifier you chose during the
installation process. In order to execute the TSGU, you must add
an allocation for DDNAME NLS to the CLIST:
ALLOC F(NLS) DA('install_hlq.ERRNLS.DATA') SHR REU
-
Execute the FOCUSC CLIST to start FOCUS.
-
At the FOCUS command prompt, issue the TSGU command to
generate the necessary tables.
The tables are created as members in the install_hlq.ERRNLS.DATA
alias library.
For example, to generate
the transcoding table (TRANTBL) that adds the new or alternate code
pages from the CPCODEPG file, issue the following command:
TSGU
If you modified the monocasing information
in any of the code page definition files, issue the following command
to generate the monocasing table (CASETBL):
TSGU CASE
If you modified the sorting sequence
in any of the code page definition files, issue the following command
to generate the sorting table (SORTTBL):
TSGU SORT
To create all three types of tables
(transcoding, monocasing, and sort tables), issue the following
command:
TSGU GEN
For
complete information about TSGU command syntax, see Generating New Transcoding Tables.
-
Configure the FOCUS default code page and language.
If you generated a new FOCUS code page in step 5 and want
FOCUS to use this new code page, you must modify the NLS configuration
file, install_hlq.ERRNLS.DATA(NLSCFG), to identify the new
FOCUS code page and language used by FOCUS for error messages. This
step is only necessary if you generated a new FOCUS code page in
step 5.
You
change the FOCUS code page and language for FOCUS by editing the
LANG setting in the NLS configuration file. Changing the LANG setting
sets all other parameters to valid values. for complete information
about parameters in the NLSCFG file, see The NLS Configuration File.
Note: The LANG setting should
match the three-character language abbreviation (language ID) or
the language name.
You can find the appropriate language abbreviation
for each code page in member CPCPALL in the alias library install_hlq.ERRNLS.DATA.
The following shows a portion of the CPCPALL file, which includes
the language setting for code page 280:
* LANG=ITA
cp280
cp850
cp137
cp65001
BR
* LANG=JPN
cp939
cp942
cp65001
BR
The following example illustrates how
you can change the default language from English to Italian. Change:
LANG = AMENGLISH
to
LANG = ITA
Error
messages are only translated for German, Spanish, French, Dutch,
and Japanese. Error messages for all other languages are translated
to English.
Note: Swedish and some other languages
may only be partially translated.
x
Reference: Structure of the Known Code Page File (CPXCPTBL)
CPnnnnn b dbcs-id description
where:
- CP
-
Is the code page prefix (always CP).
-
nnnnn
-
Is the code page number.
-
b
-
Is the character type. Possible values are:
A for
ASCII.
E for EBCDIC.
-
dbcs-id
-
Is the DBCS identifier (DBCSID).
-
description
-
Is a description of the code page.
xConfiguring Customized FOCUS NLS Monocasing
Monocasing (also called Case Conversion) is the conversion
of a letter from its lowercase to uppercase form (or vice versa).
As part of the basic FOCUS initialization, FOCUS is set up with
standard monocasing where all requests, except for data between
single quotes, are converted to uppercase according to the monocasing
table (CASETBL). The monocasing table file install_hlq.ERRNLS.DATA(CASETBL)
converts a-z to A-Z only. If you require customized monocasing,
such as special upper/lowercase accented characters, then you must
modify the code page definition file (CPnnnnn) and then generate
a new NLS monocasing table file (CASETBL) using the TSGU. The new
monocasing table is based on the changes made to the code page definition
file (CPnnnnn).
Note: The Information Builders functions LOCASE and UPCASE
respect the NLS monocasing table file (CASETBL).
x
Procedure: How to Customize Your NLS Monocasing Table
Note: As
part of the basic initialization, monocasing tables are provided
for most of the common European languages. You will only need to
customize the monocasing tables if you require a special monocasing
configuration.
NLS monocasing involves
language-sensitive (code page sensitive) uppercase and lowercase conversion.
You can customize the attributes of each character by completing
the following steps:
-
Edit the code page definition file (CPnnnnn), which
is named by the code page number. For example, CP00037 contains
the monocasing information for US English code page 37. For more
information on the code page definition file (CPnnnnn), see Use
the Known Code Page File (CPXCPTBL) for z/OS.
Note: You can reference the known code page file
(CPXCPTBL) to find the name of the code page definition file.
The
code page definition file (CPnnnnn) contains the Code Point
and Graphic Character Global Identifier (GCGID). Make the appropriate
changes to GCGID uppercase in the third column and Character type
in the fifth column.
The following is a chart of a sample
code page definition file layout:
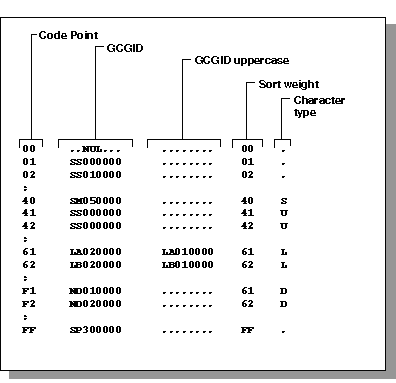
-
Edit the code page generation list file (CPCODEPG) and add
the code page definition information as described in Configuring New or Alternate Code Pages for FOCUS. The updated code page
generation list (CPCODEPG) is used to regenerate the custom monocasing
table file (CASETBL).
-
Execute the TSGU with the parameter CASE.
The TSGU generates the updated NLS monocasing table file install_hlq.ERRNLS.DATA
(CASETBL).
Note: For
additional information on modifying monocasing values in the code
page definition file, refer to the IBM CDRA Library SC09-9391-00
Level 1 Registry or contact your local Information Builders representative.
xConfiguring Customized FOCUS NLS Sort Sequences
As part of the basic FOCUS initialization, FOCUS is
set up with standard sorting where FOCUS uses sort sequences of
the binary representation of a character string according to the sorting
table install_hlq.ERRNLS.DATA(SORTTBL). If you require customized
sorting, such as changing your sort order to account for Swedish
umlauts (Ü), then you must modify the NLS sorting table file (SORTTBL).
x
Procedure: How to Customize Your NLS Sort Tables
Note: As
part of the basic initialization, sorting tables are provided for
most of the common European languages. You will only need to customize
the sorting tables if you require a special sorting sequence.
If
you want to use a weighted sort that accounts for characters that
are out of binary sequence, you can customize the sort tables by
completing the following steps.
-
Edit the code page definition file install_hlq.ERRNLS.DATA(CPnnnnn),
which is named by the code page number. For example, CP00037 contains
the sorting information for US English code page 37. For more information
on the code page definition file (CPnnnnn), see Use
the Code Page Definition File (CPnnnnn) for z/OS.
Note: You can reference the known code page file
(CPXCPTBL) to find the name of the code page definition file.
The
code page definition file (CPnnnnn) contains the Code Point
and Graphic Character Global Identifier (GCGID). Make the appropriate
changes to the Sort weight listed in the fourth column. The following
is a chart of a sample code page definition file layout:
-
Edit the code page generation list file (CPCODEPG) and add
the code page definition information as described in Configuring New or Alternate Code Pages for FOCUS. The updated code page
generation list (CPCODEPG) is used to regenerate the custom sorting
table file (SORTTBL).
-
Execute the TSGU from FOCUS with the parameter SORT.
The TSGU generates the updated NLS sorting table file install_hlq.ERRNLS.DATA
(SORTTBL).
Note: For
additional information on modifying monocasing values in the code
page definition file, refer to the IBM CDRA Library SC09-9391-00
Level 1 Registry or contact your local Information Builders representative.
x
Syntax: How to Use the Code Page Definition File (CPnnnnn)
The
code page definition file install_hlq.ERRNLA.DATA(CPnnnnn)
contains information on the characters for each code point value
in the code page.
dd aaaaaaaa aaaaaaaa xx h
where:
-
dd
-
Is the hexadecimal code point value (00 through FF).
-
aaaaaaaa
-
Is the Graphic Character Global IDentifier (GCGID).
-
xx
-
Is the Sort weight. Consists of a hexadecimal code point
value (00 through FF).
-
h
-
Is the character type. Possible values are:
L for
Lower-case alphabet.
U for Upper-case alphabet.
A for
Asian (non-alphabet) character.
D for Digit.
S for
Special character.
C for Control (non-printable) character.
xGenerating New Transcoding Tables
The TSGU is a multi-functional utility that is used
to create the transcoding table (TRANTBL), sorting table (SORTTBL),
and monocasing table (CASETBL).
x
Syntax: How to Use the TSGU Command
TSGU
TSGU GEN
TSGU INFO info-command
TSGU CASE
TSGU SORT
where:
- no parameters
-
Generates the NLS transcoding table(TRANTBL).
- GEN
-
Generates all the tables (TRANTBL, CASETBL and SORTTBL).
- INFO
-
Displays information about the current NLS configuration.
- CASE
-
Generates the custom monocasing table (CASETBL) binary file.
- SORT
-
Generates the custom sort sequence table (SORTTBL) binary file.
x
Syntax: How to Use the TSGU Info-Commands
TSGU INFO CP [DBCS] [nnn [nnn [...]]] [MAT [DES]]
TSGU INFO CP [SBCS] [nnn [nnn [...]]] [MAT [DES]]
TSGU INFO TRAN [idx [idx [...]]] [M] [V]
TSGU INFO CASE [nnn [nnn [...]]] [M] [V]
TSGU INFO SORT [nnn [nnn [...]]] [M] [V]
TSGU INFO SET
where:
- CP
-
Lists transcoding tables.
- DBCS
-
Lists only DBCS transcodings.
- SBCS
-
Lists only SBCS transcodings.
-
nnn
-
Code page which only shows given code page transcodings (no
leading zeros necessary).
-
idx
-
Index which only shows given index transcodings.
- MAT
-
Creates a matrix report for transcoding tables.
- DES
-
Reverses an order of code pages in a matrix report.
- TRAN
-
Shows transcoding table contents (trantbl.err).
- CASE
-
Shows uppercase/lowercase table contents (casetbl.err).
- SORT
-
Shows sort table contents (sorttbl.err).
- M
-
Masks null transcode values in tables.
- V
-
Shows tables in vertical layout.
- SET
-
Shows the list of available languages.
x
Syntax: How to Use the TSGU ? Command
To
see the online help information for the TSGU command, issue the following
command:
TSGU ?
The
output is:
TSGU : GEN : cpcodepg-id ::
: TRAN : cpcodepg-id :: (default)
: CASE : cpcodepg-id ::
: SORT : cpcodepg-id ::
: INFO : info-command ::
: XLAT : infile : outfile :::
: XLAT TEMPLATE : cp1 cp2 ::
: KTBL : ktbl-command : : xxxx : xxxx : ... ::::
: ERR err-command : GEN : generate all necessary tables (binary files)
TRAN : generate a TRANTBL and KTBL binary files
CASE : generate a CASETBL binary file
SORT : generate a SORTTBL binary file
INFO : display info of the current Translation Services (? LANG)
XLAT : convert a file by specified Code Pages in config file (tsgu.nls)
TEMPLATE shows a sample batch file/unix shell script for multi-
files to be XLATed. (tsgult only)
KTBL : generate individual KTBL binary files
ERR : convert EDAHOME/nls/*.err file (UNIX and Windows NT only)
xxxx : DBCS translation table identifier cpcodepg-id:
Max 4 characters. To use customized and saved CPCODEPG.NLS
If specified, a file named 'cpcp:cpcodepg-id:.nls' is used instead.
cpcpall.nls and cpcpucs.nls are provided as samples. info-command:
CP :| DBCS |: : nnn | nnn | ... : : MAT : DES ::
| SBCS |
TRAN : idx : idx : ... :: : M : : V ::
CASE : nnn : nnn : ... :: : M : : V ::
SORT : nnn : nnn : ... :: : M : : V ::
ALL
CP : Show TRTIDX
DBCS : Show only DBCS translations
SBCS : Show only SBCS translations
idx : Index, show only given indexes translations
nnn : Code Page, show only given Code Pages translations
MAT : Make a matrix report for TRTIDX
DES : Reverses an order of Code Pages in a matrix report
TRAN : Show translation tables (TRANTBL)
CASE : Show upcase/lowcase tables (CASETBL)
SORT : Show sort tables (SORTTBL)
M : Mask null translate values in tables
V : Show tables vertical layout against horizontal
ALL : Show intlcm info for debugging ktbl-command:
CHK
FMT
CNV : UDC : : nn | CPU | MEM :
RVS : UDC : : nn | CPU | MEM :
LST : FFFF :
ADD
CHK : Check the KTBLs translation integrity
FMT : Format the KTBLs
CNV : Convert the KTBLs
RVS : Make a reverse translation table for the KTBLs
LST : List the DBCS translation
ADD : Make a new DBCS translation from two KTBLs
UDC : Remove Unused UDC code translation
nn : Threshold level for indexing the ranges
CPU : nn = 65536, to make only one index range
MEM : nn = 4, to make the smallest size format for the KTBLs
FFFF: Produce entries for source code even they are translated
to invalid codes err-command:
GEN aaa
UCS aaa
GEN : Create *:aaa:.err files in the directory EDACONF/etc.
(JPE and GE5 only)
UCS : Create *(aaa).err files in Unicode (utf-8) into the
directory EDACONF/etc.
aaa : Language abbreviation
xThe NLS Configuration File
The NLS configuration file (NLSCFG) controls the code
page and the language used for error messages for FOCUS and is located
in install_hlq.ERRNLS.DATA.
x
Syntax: How to Use the NLS Configuration File (NLSCFG)
The
following is a reference of keywords in the NLSCFG file and their associated
values:
- LANG=
-
Is the language. The list of known languages file (LANGTBL),
located in install_hlq.ERRNLS.DATA, contains a list of valid
values. The value of LANG determines the defaults for other parameters
in FOCUS. The default value is AMENGLISH (American English).
- CODE_PAGE=
-
Is the FOCUS code page. For z/OS, the hard-coded default
value is 37.
- CDN=
-
Is Continental Decimal Notation. Possible values are a comma
(,) or a period (.). The default value is a period (.).
- DATETIME=
-
Is the DATE/TIME format for SQL. Possible values are:
EDA for
EDA type (default). On z/OS, the default is HYYMDs.
ISO for
yyyy-mm-dd hh.mm.ss.
USA for mm/dd/yyyy hh:mm
AM or PM.
EUR for dd.mm.yyyy hh.mm.ss.
JIS for
yyyy-mm-dd hh:mm:ss.
LOCAL for any site-defined
form.