x
Procedure: How to Identify Current z/OS Code Page Settings (Step 1 of 5)
Code
page settings are reflected in the code page generation list file qualif.FOCCTL.DATA(CPCODEPG).
This file contains code page settings for FOCUS and it is used to
generate the transcoding tables with the TSGU. To identify your current
code page settings, view the code page generation list file (cpcodepg).
During
the FOCUS installation, FOCUS is setup by default with the US EBCDIC
code page 37. The code page setting for FOCUS is set up to support
the following default code pages:
- US Mainframe
EBCDIC CP 37
- US PC ASCII
CP 437
- PC Windows
ANSI CP 137
- Mainframe
Latin-1 1047
Example: Using the Code Page Generation List File (CPCODEPG) for z/OS
The
following is an example of a code page generation list file (CPCODEPG).
CP00037 E SBCS US IBM MF EBCDIC code
CP00437 A SBCS US PC ASCII code
CP00137 A SBCS ANSI Character Set for MS-Windows
CP01047 E SBCS IBM MF Open Systems (Latin 1)
x
Procedure: How to Identify Alternate or Additional z/OS Code Pages (Step 2 of 5)
If
FOCUS requires support for alternate or additional code pages, you
can identify the code pages by referencing the known code page file qualif.FOCCTL.DATA
(CPXCPTBL).
Note: If the
desired code page is not listed in the known code page file (CPXCPTBL),
refer to the appropriate IBM Character Data Representation Architecture (CDRA)
document and create your own, or contact your local Information
Builders representative for information about additional code pages.
x
Syntax: How to Use the Known Code Page File (CPXCPTBL) for z/OS
CPnnnnn b dbcs-id description
where:
- CP
-
Is the code page prefix (always CP).
-
nnnnn
-
Is the code page number.
-
b
-
Is the character type. Possible values are:
A for
ASCII.
E for EBCDIC.
-
dbcs-id
-
Is the DBCS identifier (DBCSID).
-
description
-
Is a description of the code page.
Example: Using the Known Code Page File (CPXCPTBL) for z/OS
The following is a listing of the contents
of the known code page file (CPXCPTBL):
* The active Code Page information is represented by lines whose first 2
* columns are 'CP'.
* Valid DBCSID : SOSI,SJIS,EUC,KPC,KKS,TPC,TBIG5,SOSIF,SOSIH
* C - Character type : E = EBCDIC
* A = ASCII
* DBCS - DBCS ID : SBCS = Single Byte Character Set
* SOSI = IBM MF
* SJIS,EUC,SOSIF,SOSIH = Japanese
* KPC,KKS = Korean
* TPC,TBIG5,TNS,TTEL = Taiwanese
*
* note: NRC Set = National Replacement Character Set
* MF = Mainframe
*
Codepage C DBCS Description
-------- - ---- ------------------------------------------------------
CP00037 E SBCS US IBM MF EBCDIC code
CP00437 A SBCS US PC ASCII code
CP00137 A SBCS ANSI character set for MS-Windows
CP00500 E SBCS IBM MF International European
CP00273 E SBCS IBM MF Germany F.R./Austria
CP00277 E SBCS IBM MF Denmark, Norway
CP00278 E SBCS IBM MF Finland, Sweden
CP00280 E SBCS IBM MF Italy
CP00281 E SBCS IBM MF Japanese English
CP00284 E SBCS IBM MF Spain/Latin America
CP00285 E SBCS IBM MF United Kingdom
CP00297 E SBCS IBM MF France
CP00420 E SBCS IBM MF Arabic Bilingual
CP00424 E EBCH IBM MF Israel(Hebrew)
CP00850 A SBCS IBM PC Multinational
CP00856 A SBCS IBM PC Hebrew
CP00860 A SBCS IBM PC Portugal
CP00861 A SBCS IBM PC Iceland
CP00862 A ASCH IBM PC Israel
CP00863 A SBCS IBM PC Canadian French
CP00864 A SBCS IBM PC Arabic
CP00865 A SBCS IBM PC Nordic
CP00869 A ASCG IBM PC Greece
CP00871 E SBCS IBM MF Iceland
CP00875 E EBCG IBM MF Greece
CP00637 A SBCS DEC Multinational Character Set
CP00600 A SBCS DEC German NRC Set
CP00604 A SBCS DEC British ( United Kingdom ) NRC Set
CP00608 A SBCS DEC Dutch ( Netherland ) NRC Set
CP00612 A SBCS DEC Finnish ( Finland ) NRC Set
CP00616 A SBCS DEC French ( Flemish and French/Belgian ) NRC Set
CP00620 A SBCS DEC French Canadian NRC Set
CP00624 A SBCS DEC Italian ( Italy ) NRC Set
CP00628 A SBCS DEC Norwegian/Danish ( Norway,Denmark ) NRC Set
CP00632 A SBCS DEC Portugal NRC Set
CP00636 A SBCS DEC Spanish ( Spain ) NRC Set
CP00640 A SBCS DEC Swedish ( Sweden ) NRC Set
CP00644 A SBCS DEC Swiss ( Swiss/French and Swiss/German ) NRC Set
CP00930 E SOSI Japanese IBM MF Katakana Code Page (cp290+cp300)
CP00939 E SOSI Japanese IBM MF Latin Extended (cp1027+cp300)
CP00932 A SJIS Japanese PC Shift-JIS (cp897+cp301)
CP00942 A SJIS Japanese PC Shift-JIS Extended (cp1041+cp301)
CP10942 A EUC Japanese PC EUC
CP10930 E SOSIF Japanese Mainframe ( Fujitsu )
CP20930 E SOSIH Japanese Mainframe ( Hitachi )
CP00933 E SOSI Korean IBM MF Extended (cp833+cp834)
CP00934 A KPC Korean IBM PC (cp891+cp926)
CP00944 A KPC Korean IBM PC Extended (cp1040+cp926)
CP00949 A KKS Korean KS5601 code (cp1088+cp951)
CP00935 E SOSI PRC IBM MF Extended (cp836+cp837)
CP00946 A CPC PRC IBM PC Extended (cp1042+cp928)
CP00937 E SOSI Taiwanese IBM MF (cp37+cp835)
CP00948 A TPC Taiwanese IBM PC Extended (cp1043+cp927)
CP10948 A TBIG5 Taiwanese PC BIG-5 code (cp950 ?)
CP20948 A TNS Taiwanese PC National Standard code
CP30948 A TTEL Taiwanese PC Telephone code
CP00857 A ASCR IBM PC Turkish (Latin 5)
CP00920 A ISO9 ISO-8859-9 (Latin 5, Turkish)
CP01026 E EBCR IBM MF Turkish
CP01252 A SBCS Windows, Latin 1
CP00819 A SBCS ISO-8859-1 (Latin 1, IBM Version 8X/9X undef'ed)
CP00912 A ISO2 ISO-8859-2 (Latin 2)
CP01047 E SBCS IBM MF Open Systems (Latin 1)
CP65001 A UTF8 Unicode (UTF-8)
CP00916 A ISO8 ISO-8859-8 (Hebrew)
CP00813 A ISO7 ISO-8859-7 (Greek)
CP00870 E EBCE IBM MF Multilingual (Latin 2, East European)
CP00852 A ASCE IBM PC Multilingual (Latin 2, East European)
CP01250 A WINE Windows, Latin 2 (East European)
CP01253 A WING Windows, Greek
CP01254 A WINR Windows, Turkish
CP01255 A WINH Windows, Hebrew
CP01025 E EBCY IBM MF Cyrillic, Multilingual
CP00866 A ASCY IBM PC Cyrillic #2
CP00915 A ISO5 ISO-8859-5 (Cyrillic, 8-bit)
CP01251 A WINY Windows, Cyrillic
CP01112 E EBCB IBM MF Baltic Multilanguage
CP00921 A ISO3 ISO-8859-13 (Latin 7, Baltic Multilanguage)
CP01257 A WINB Windows, Baltic
CP01089 A ISO6 ISO-8859-6 (Arabic)
CP01256 A WINA Windows, Arabic
CP00838 E EBCI IBM MF Thai
CP00874 A WINI IBM PC Thailand
CP90278 E SBCS IBM MF Finland, Sweden (Internal Use, zapped)
CP00914 A ISO4 ISO-8859-4 (Latin 4, Baltic Multilanguage)
CP65002 E UTFE Unicode (UTF-EBCDIC)
CP00923 A ISOF ISO-8859-15 (Latin 9)
CP30930 E SOSI Japanese IBM MF Dollar-Yen exchanged CP00930
CP11026 E EBCR IBM MF Turkish DoubleQuote-U-umlaut exchanged CP01026
x
Procedure: How to Add Alternate or Additional z/OS Code Pages (Step 3 of 5)
The
code page generation list file qualif.FOCCTL.DATA(CPCODEPG)
is a list of code pages to generate with the TSGU and must be changed
manually, using an editor, to contain the additional or alternate
set of code page numbers identified in the known code page file
(CPXCPTBL) (step 2 of 5).
Add
the information for each additional or alternate code page on a
separate line, You can copy the code page information from the known
code page file (CPXCPTBL) into the code page generation list file
(CPCODEPG). Note that only CP and the code page number (for example,
CP00037) is required to generate the new transcoding tables. The
maximum number of code page entries in the file is sixteen.
x
Procedure: How to Generate z/OS Transcoding Tables Using the TSGU (Step 4 of 5)
The
Transcoding Services Generation Utility (TSGU) program is used to
generate the NLS transcoding table file qualif.ERRNLS.DATA(trantbl),
based on the list of code pages defined in the code page generation
list file (CPCODEPG). The transcoding table file (trantbl) contains
the transcoding tables for all the possible code page combinations.
You can generate a new transcoding table with the TSGU by completing
the following steps:
-
The sample JCL to execute TSGU is located in qualif.FOCCTL.DATA(TSGUJCL).
Edit this JCL stream to conform to your site requirements:
- Replace qualif with
the appropriate high-level qualifier value.
- Supply a
valid JOB card.
- Comment the
following line in the JCL:
//TSGU PROC CTL=EDA,ERRORS=EDAMSG
- Uncomment
the following line in the JCL:
//TSGU PROC CTL=FOC,ERRORS=ERRORS
The
output of TSGU is the transcoding table file (TRANTBL), which is
based on the contents of the code page generation list file (CPCODEPG).
The TRANTBL is generated in qualif.ERRNLS.DATA. This data
set must be allocated to ddname ERRORS in the FOCUS JCL or CLIST.
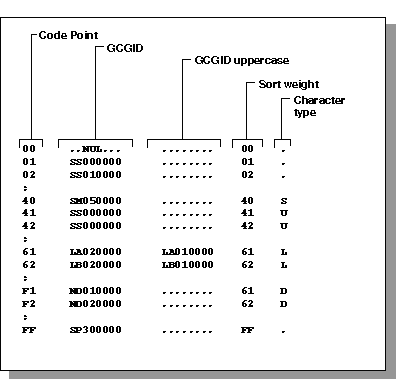
-
If you get a duplicate GCGID, choose which one to discard and
replace it with eight periods as follows:
........
-
The following confirms the generated information:
- INFO shows
NLS basic information.
- INFO CP shows
a list of transcoding tables.
x
Procedure: How to Change the z/OS FOCUS Code Page Setting (Step 5 of 5)
If
you generate a new FOCUS code page in step 4 and want FOCUS to recognize
this new code page, you will need to modify the NLS configuration
file qualif.ERRORS.DATA(NLSCFG) to identify the new FOCUS
code page and language used by FOCUS for error messages. This step
is only necessary if you generated a new FOCUS code page in step
4. For details on changing the NLS configuration file, see Configuring z/OS FOCUS NLS Default Characteristics.