This section provides detailed descriptions of new features for all SQL adapters.
A synonym for a table in a relational data source can contain declarations in the Access File specifying which columns should have indexes.
When you issue a CREATE FILE command for a table, an index is created in the relational DBMS for the primary key and for each index specified in the Access File.
If you want to create a table without creating all of the indexes at that time, you can omit the index declarations from the Access File and issue the CREATE FILE command to create only the table and the index on the primary key. Then, at a later time, you can add the index declarations to the Access File and issue the CREATE FILE command with the INDEXESONLY phrase. The option of adding the indexes later makes loading data into a relational table much faster.
CREATE FILE app/synonym INDEXESONLY
where:
- app
Is the application folder in which the synonym resides.
- synonym
Is the synonym for the existing table.
The WebFOCUS join command and conditional join command have a FULL OUTER join option.
A full outer join returns all rows from the source data source and all rows from the target data source. Where values do not exist for the rows in either data source, null values are returned. WebFOCUS substitutes default values on the report output (blanks for alphanumeric columns, the NODATA symbol for numeric columns).
The full outer join is only supported for use with those relational data sources that support this type of join, in which case the WebFOCUS join syntax is optimized (translated to the full outer join SQL syntax supported by the RDBMS). Use of this syntax for any data source that does not support a full outer join, or the failure of the request to be optimized to the engine, produces an error message.
The following syntax generates a full outer equijoin based on real fields:
JOIN FULL_OUTER hfld1 [AND hfld2 ...] IN table1 [TAG tag1] TO {UNIQUE|MULTIPLE} cfld [AND cfld2 ...] IN table2 [TAG tag2] [AS joinname] END
where:
- hfld1
Is the name of a field in the host table containing values shared with a field in the cross-referenced table. This field is called the host field.
- AND hfld2...
Can be an additional field in the host table. The phrase beginning with AND is required when specifying multiple fields.
- For relational adapters that support multi-field and concatenated joins, you can specify up to 16 fields. See your adapter documentation for specific information about supported join features.
- IN table1
Is the name of the host table.
- TAG tag1
Is a tag name of up to 66 characters (usually the name of the Master File), which is used as a unique qualifier for fields and aliases in the host table.
The tag name for the host table must be the same in all the JOIN commands of a joined structure.
- TO [UNIQUE|MULTIPLE] crfld1
Is the name of a field in the cross-referenced table containing values that match those of hfld1 (or of concatenated host fields). This field is called the cross-referenced field.
Note: UNIQUE returns only one instance and, if there is no matching instance in the cross-referenced table, it returns null values.
Use the MULTIPLE parameter when crfld1 may have multiple instances in common with one value in hfld1. Note that ALL is a synonym for MULTIPLE, and omitting this parameter entirely is a synonym for UNIQUE.
- AND crfld2...
Is the name of a field in the cross-referenced table with values in common with hfld2.
Note: crfld2 may be qualified. This field is only available for adapters that support multi-field joins.
- IN crfile
Is the name of the cross-referenced table.
- TAG tag2
Is a tag name of up to 66 characters (usually the name of the Master File), which is used as a unique qualifier for fields and aliases in cross-referenced tables. In a recursive join structure, if no tag name is provided, all field names and aliases are prefixed with the first four characters of the join name.
The tag name for the host table must be the same in all the JOIN commands of a joined structure.
- AS joinname
Is an optional name of up to eight characters that you may assign to the join structure. You must assign a unique name to a join structure if:
- You want to ensure that a subsequent JOIN command does not overwrite it.
- You want to clear it selectively later.
- The structure is recursive.
Note: If you do not assign a name to the join structure with the AS phrase, the name is assumed to be blank. A join without a name overwrites an existing join without a name.
- END
Required when the JOIN command is longer than one line. It terminates the command and must be on a line by itself.
The following syntax generates a DEFINE-based full outer join:
JOIN FULL_OUTER deffld WITH host_field ... IN table1 [TAG tag1] TO [UNIQUE|MULTIPLE] cr_field IN table2 [TAG tag2] [AS joinname] END
where:
- deffld
Is the name of a virtual field for the host file (the host field). The virtual field can be defined in the Master File or with a DEFINE command.
- WITH host_field
Is the name of any real field in the host segment with which you want to associate the virtual field. This association is required to locate the virtual field.
The WITH phrase is required unless the KEEPDEFINES parameter is set to ON and deffld was defined prior to issuing the JOIN command.
To determine which segment contains the virtual field, use the ? DEFINE query after issuing the DEFINE command.
- IN table1
Is the name of the host table.
- TAG tag1
Is a tag name of up to 66 characters (usually the name of the Master File), which is used as a unique qualifier for fields and aliases in host tables.
The tag name for the host table must be the same in all JOIN commands of a joined structure.
- TO [UNIQUE|MULTIPLE] crfld1
Is the name of a real field in the cross-referenced table whose values match those of the virtual field. This must be a real field declared in the Master File.
Note: UNIQUE returns only one instance and, if there is no matching instance in the cross-referenced table, it returns null values.
Use the MULTIPLE parameter when crfld1 may have multiple instances in common with one value in hfld1. Note that ALL is a synonym for MULTIPLE, and omitting this parameter entirely is a synonym for UNIQUE.
- IN crfile
Is the name of the cross-referenced table.
- TAG tag2
Is a tag name of up to 66 characters (usually the name of the Master File), which is used as a unique qualifier for fields and aliases in cross-referenced tables. In a recursive joined structure, if no tag name is provided, all field names and aliases are prefixed with the first four characters of the join name.
The tag name for the host file must be the same in all JOIN commands of a joined structure.
- AS joinname
Is an optional name of up to eight characters that you may assign to the joined structure. You must assign a unique name to a join structure if:
- You want to ensure that a subsequent JOIN command does not overwrite it.
- You want to clear it selectively later.
- The structure is recursive, and you do not specify tag names.
If you do not assign a name to the joined structure with the AS phrase, the name is assumed to be blank. A join without a name overwrites an existing join without a name.
- END
Required when the JOIN command is longer than one line. It terminates the command and must be on a line by itself.
The following syntax generates a full outer conditional join:
JOIN FULL_OUTER FILE table1 AT hfld1 [WITH hfld2] [TAG tag1] TO {UNIQUE|MULTIPLE} FILE table2 AT crfld [TAG tag2] [AS joinname] [WHERE expression1; [WHERE expression2; ...] END
where:
- table1
Is the host Master File.
- AT
Links the correct parent segment or host to the correct child or cross-referenced segment. The field values used as the AT parameter are not used to cause the link. They are used as segment references.
- hfld1
Is the field name in the host Master File whose segment will be joined to the cross-referenced table. The field name must be at the lowest level segment in its data source that is referenced.
- tag1
Is the optional tag name that is used as a unique qualifier for fields and aliases in the host table.
- hfld2
Is a table column with which to associate a DEFINE-based conditional JOIN. For a DEFINE-based conditional join, the KEEPDEFINES setting must be ON, and you must create the virtual fields before issuing the JOIN command.
- MULTIPLE
Specifies a one-to-many relationship between table1 and table2. Note that ALL is a synonym for MULTIPLE.
- UNIQUE
Specifies a one-to-one relationship between table1 and table2. Note that ONE is a synonym for UNIQUE.
Note: The join to UNIQUE will return only one instance of the cross-referenced table, and if this instance does not match based on the evaluation of the WHERE expression, null values are returned.
- crfile
Is the cross-referenced Master File.
- crfld
Is the join field name in the cross-referenced Master File. It can be any field in the segment.
- tag2
Is the optional tag name that is used as a unique qualifier for fields and aliases in the cross-referenced table.
- joinname
Is the name associated with the joined structure.
- expression1, expression2
Are any expressions that are acceptable in a DEFINE FILE command. All fields used in the expressions must lie on a single path.
- END
The END command is required to terminate the command and must be on a line by itself.
The following requests generate two Microsoft SQL Server tables to join, and then issues a request against the join. The tables are generated using the wf_retail sample that you can create using the WebFOCUS - Retail Demo tutorial in the server Web Console.
The following request generates the WF_SALES table. The field ID_PRODUCT will be used in the full outer join command. The generated table will contain ID_PRODUCT values from 2150 to 4000:
TABLE FILE WF_RETAIL_LITE SUM GROSS_PROFIT_US PRODUCT_CATEGORY PRODUCT_SUBCATEG BY ID_PRODUCT WHERE ID_PRODUCT FROM 2150 TO 4000 ON TABLE HOLD AS WF_SALES FORMAT SQLMSS END
The following request generates the WF_PRODUCT table. The field ID_PRODUCT will be used in the full outer join command. The generated table will contain ID_PRODUCT values from 3000 to 5000:
TABLE FILE WF_RETAIL_LITE SUM PRICE_DOLLARS PRODUCT_CATEGORY PRODUCT_SUBCATEG PRODUCT_NAME BY ID_PRODUCT WHERE ID_PRODUCT FROM 3000 TO 5000 ON TABLE HOLD AS WF_PRODUCT FORMAT SQLMSS END
The following request issues the JOIN command and displays values from the joined tables:
SET TRACEUSER=ON SET TRACESTAMP=OFF SET TRACEOFF=ALL SET TRACEON = STMTRACE//CLIENT JOIN FULL_OUTER ID_PRODUCT IN WF_PRODUCT TAG T1 TO ALL ID_PRODUCT IN WF_SALES TAG T2 TABLE FILE WF_PRODUCT PRINT T1.ID_PRODUCT AS 'Product ID' PRICE_DOLLARS AS Price T2.ID_PRODUCT AS 'Sales ID' GROSS_PROFIT_US BY T1.ID_PRODUCT NOPRINT ON TABLE SET PAGE NOPAGE END
The trace shows that the full outer join was optimized (translated to SQL) so that SQL Server could process the join:
SELECT T1."ID_PRODUCT", T1."PRICE_DOLLARS", T2."ID_PRODUCT", T2."GROSS_PROFIT_US" FROM ( WF_PRODUCT T1 FULL OUTER JOIN WF_SALES T2 ON T2."ID_PRODUCT" = T1."ID_PRODUCT" ) ORDER BY T1."ID_PRODUCT";
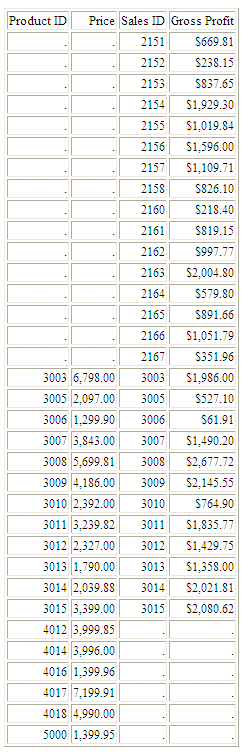
The output has a row for each ID_PRODUCT value that is in either table. Rows with ID_PRODUCT values from 2150 to 2167 are only in the WF_SALES table, so the columns from WF_PRODUCT display the NODATA symbol. Rows with ID_PRODUCT values above 4000 are only in the WF_PRODUCT table, so the columns from WF_SALES display the NODATA symbol. Rows with ID_PRODUCT values from 2000 to 4000 are in both tables, so all columns have values, as shown in the following image.
The JOIN AS_ROOT command adds a new fact table as an additional root to an existing fact-based cluster (star schema). The source Master File has a parent fact segment and at least one child dimension segment. The JOIN AS_ROOT command supports a unique join from a child dimension segment (at any level) to an additional fact parent.
JOIN AS_ROOT sfld1 [AND sfld2 ...] IN [app1/]sfile TO UNIQUE tfld1 [AND tfld2 ...] IN [app2/]tfile AS jname END
where:
- sfld1 [AND sfld2 ...]
Are fields in the child (dimension) segment of the source file that match values of fields in the target file.
- [app1/]sfile
Is the source file.
- TO UNIQUE tfld1 [AND tfld2 ...]
Are fields in the target file that match values of fields in the child segment of the source file. The join must be unique.
- [app2/]tfile
Is the target file.
- jname
Is the join name.
- END
Is required to end the JOIN command.
The following request joins the product category and product subcategory fields in the WebFOCUS Retail data source to an Excel file named PROJECTED.
To generate the WebFOCUS Retail data source in the Web Console, click Tutorials from the Applications page.
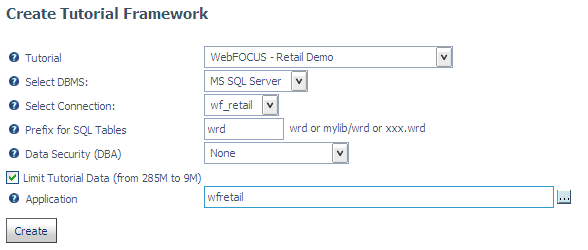
Select WebFOCUS - Retail Demo. Select your configured relational adapter (or select the flat file option if you do not have a relational adapter configured), check Limit Tutorial Data, and then click Create.
The Master File for the Excel File is:
FILENAME=PROJECTED, SUFFIX=DIREXCEL,
DATASET=app2/projected.xlsx, $
SEGMENT=PROJECTED, SEGTYPE=S0, $
FIELDNAME=PRODUCT_CATEGORY, ALIAS='Product Category', USAGE=A16V, ACTUAL=A16V,
MISSING=ON,
TITLE='Product Category',
WITHIN='*PRODUCT', $
FIELDNAME=PRODUCT_SUBCATEGORY, ALIAS='Product Subcategory', USAGE=A25V, ACTUAL=A25V,
MISSING=ON,
TITLE='Product Subcategory',
WITHIN=PRODUCT_CATEGORY, $
FIELDNAME=PROJECTED_COG, ALIAS=' Projected COG', USAGE=P15.2C, ACTUAL=A15,
MISSING=ON,
TITLE=' Projected COG', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
FIELDNAME=PROJECTED_SALE_UNITS, ALIAS=' Projected Sale Units', USAGE=I9, ACTUAL=A11,
MISSING=ON,
TITLE=' Projected Sale Units', MEASURE_GROUP=PROJECTED,
PROPERTY=MEASURE, $
MEASUREGROUP=PROJECTED, CAPTION='PROJECTED', $
DIMENSION=PRODUCT, CAPTION='Product', $
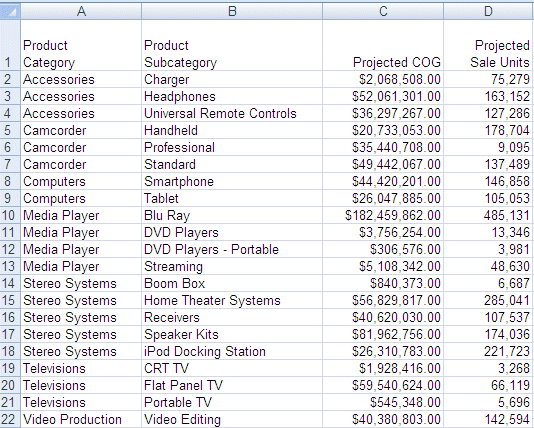
HIERARCHY=PRODUCT, CAPTION='Product', HRY_DIMENSION=PRODUCT, HRY_STRUCTURE=STANDARD, $The following image shows the data in the Excel file.
The following request joins from the wf_retail_product segment of the wf_retail data source to the excel file as a new root and reports from both parent segments:
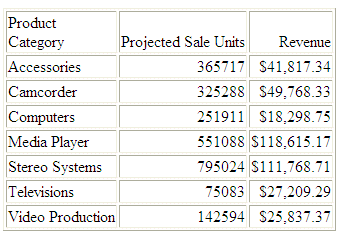
JOIN AS_ROOT PRODUCT_CATEGORY AND PRODUCT_SUBCATEG IN WF_RETAIL TO UNIQUE PRODUCT_CATEGORY AND PRODUCT_SUBCATEGORY IN PROJECTED AS J1. END TABLE FILE WF_RETAIL SUM PROJECTED_SALE_UNITS REVENUE_US BY PRODUCT_CATEGORY ON TABLE SET PAGE NOPAGE END
The output is:
Multi-parent synonyms are now supported as the source for a join to a single segment in a target synonym.
A join from a multi-parent synonym is subject to the following conditions:
- Conditional joins are not supported (JOIN WHERE).
- The join must be unique. That is, the TO ALL or TO MULTIPLE phrase is not supported.
- The target of the join cannot be a multi-parent synonym.
- The target of the JOIN must be a single segment, either in a single segment synonym or one segment in a single parent, multi-segment synonym.
- All fields in the JOIN must be FROM/TO a single segment. Any single segment in the source synonym can be used in the join.
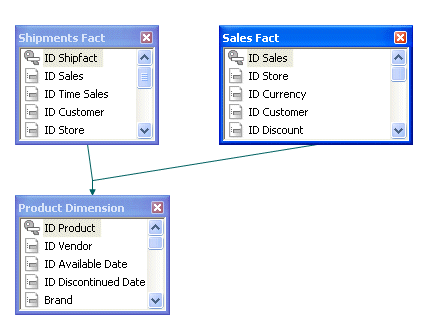
The following Master File describes a multi-parent structure based on the WebFOCUS Retail tutorial. The two fact tables wf_retail_sales and wf_retail_shipments are parents of the dimension table wf_retail_product.
FILENAME=WF_RETAIL_MULTI_PARENT, $
SEGMENT=WF_RETAIL_SHIPMENTS, CRFILE=WFRETAIL/FACTS/WF_RETAIL_SHIPMENTS, CRINCLUDE=ALL,
DESCRIPTION='Shipments Fact', $
SEGMENT=WF_RETAIL_SALES, PARENT=., CRFILE=WFRETAIL/FACTS/WF_RETAIL_SALES, CRINCLUDE=ALL,
DESCRIPTION='Sales Fact', $
SEGMENT=WF_RETAIL_PRODUCT, CRFILE=WFRETAIL/DIMENSIONS/WF_RETAIL_PRODUCT, CRINCLUDE=ALL,
DESCRIPTION='Product Dimension', $
PARENT=WF_RETAIL_SHIPMENTS, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SHIPMENTS.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $
PARENT=WF_RETAIL_SALES, SEGTYPE=KU,
JOIN_WHERE=WF_RETAIL_SALES.ID_PRODUCT EQ WF_RETAIL_PRODUCT.ID_PRODUCT;, $The following image shows the joins between these tables in the Synonym Editor of the Data Management Console (DMC).
The following request joins the product segment to the dimension table wf_retail_vendor based on the vendor ID and issues a request against the joined structure:
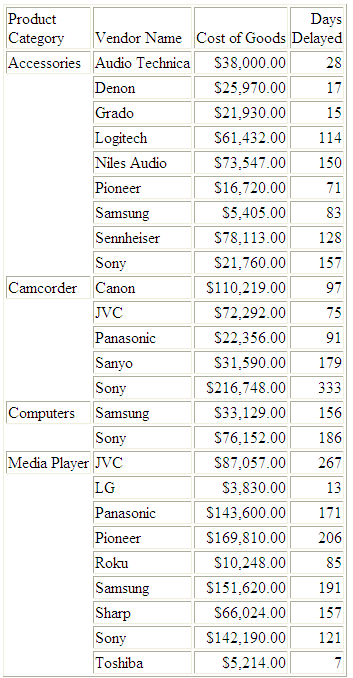
JOIN ID_VENDOR IN WF_RETAIL_MULTI_PARENT TO ID_VENDOR IN WF_RETAIL_VENDOR AS J1 TABLE FILE WF_RETAIL_MULTI_PARENT SUM COGS_US DAYSDELAYED BY PRODUCT_CATEGORY BY VENDOR_NAME WHERE PRODUCT_CATEGORY LT 'S' ON TABLE SET PAGE NOPAGE END
The output is:
When a star schema contains a segment with aggregated facts and a lower-level segment with the related detail-level facts, a request that performs aggregation on both levels and returns them sorted by the higher level can experience the multiplicative effect. This means that the fact values that are already aggregated may be re-aggregated and, therefore, return multiplied values.
When the adapter detects the multiplicative effect, it turns optimization off in order to handle the request processing and circumvent the multiplicative effect. However, performance is degraded when a request is not optimized.
A new context analysis process has been introduced in this release that detects the multiplicative effect and generates SQL script commands that retrieve the correct values for each segment context. These scripts are then passed to the RDBMS as subqueries in an optimized SQL statement.
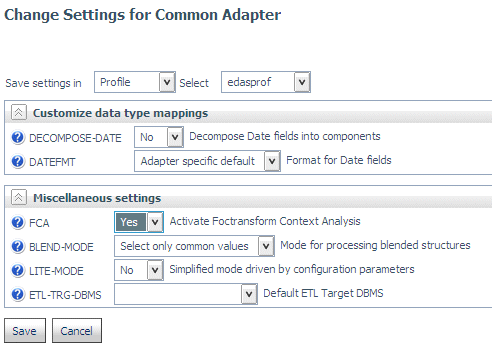
To activate the context analysis feature, click Change Common Adapter Settings on the Adapters page of the Web Console. Then select Yes for the FCA parameter in the Miscellaneous Settings section and click Save, as shown in the following image.
In prior releases, fields participating in the key to a table had to be described first in the Master File. The number of key fields was identified by the KEYS=n attribute in the Access File, where n is the number of key fields.
While this method is still supported by the relational adapters, it has been deprecated. In Version 7 Release 7.06, new syntax is available that does not require any reordering of the fields in the Master File. If an Access File with the KEYS=n syntax is opened in the Synonym Editor, the Synonym Editor will convert it to the new syntax.
Key fields in the Master File can be listed in the order established by the relational DBMS or in any order that is convenient. In the Access File, identify the key fields with the following syntax:
KEY=fld1/fld2/.../fldn
where:
- fld1, fld2,...,fldn
Are the fields that participate in the key.
The following is a Master File for an Oracle table:
FILENAME=BMKEY, SUFFIX=SQLORA , $
SEGMENT=BMKEY, SEGTYPE=S0, $
FIELDNAME=F1INT, ALIAS=F1INT, USAGE=I11, ACTUAL=I4, $
FIELDNAME=F2CHAR4, ALIAS=F2CHAR4, USAGE=A4, ACTUAL=A4,
MISSING=ON, $
FIELDNAME=F3INT, ALIAS=F3INT, USAGE=I11, ACTUAL=I4,
MISSING=ON, $
FIELDNAME=F4CHAR6, ALIAS=F4CHAR6, USAGE=A6, ACTUAL=A6,
MISSING=ON, $The following Access File identifies F4CHAR6 and F1INT as the key fields, with F4CHAR6 as the high-order portion of the key, even though it is not first in the Master File:
SEGNAME=BMDKEY_KEY_FLDLST,
TABLENAME=R729999D.BMDKEY,
CONNECTION=<local>,
KEY=F4CHAR6/F1INT, $
Simplified character functions have streamlined parameter lists, similar to those used by SQL functions. They are optimized against a wide variety of Relational data sources. The simplified character functions introduced in this release are:
- SUBSTRING - Extracts a substring from a source character string.
- TOKEN - Extracts a token from a string.
- LTRIM - Removes all blanks from the left end of a character string.
- RTRIM - Removes all blanks from the right end of a character string.
- TRIM_ - Removes leading characters, trailing characters, or both from a character string.
- CHAR_LENGTH - Returns the character length of a source string.
- LOWER - Returns the character string with all letters lowercase.
- UPPER - Returns the character string with all letters uppercase.
- POSITION - Returns the position of the first occurrence of a specified sample string in a source string.
The SQL Optimization Report provides optimization information for each function by adapter.
Simplified date and date-time functions have streamlined parameter lists, similar to those used by SQL functions. They are optimized against a wide variety of Relational data sources. The simplified date and date-time functions introduced in this release are:
- DTRUNC - given a date or timestamp and a component, DTRUNC returns the first date within the period specified by that component.
- DTADD - given a date in standard date or date-time format, DTADD returns a new date after adding the specified number of a supported component. The returned date format is the same as the input date format.
- DTPART - given a date in standard date or date-time format and a component, DTPART returns the component value in integer format.
- DTDIFF - given two dates in standard date or date-time formats, DTDIFF returns the number of given component boundaries between the two dates. The returned value has integer format for calendar components or double precision floating point format for time components.
The SQL Optimization Report provides optimization information for each function by adapter.
The following functions have been optimized for most SQL adapters, as reflected in the SQL Optimization Report.
- TRIMV with the options L or B (left or both).
- TRIM.
- POWER (fld ** exponent).
- ARGLEN.
The following functions are optimized as reflected in the SQL Optimization Report.
- DATEADD. With YEAR, MONTH, and DAY parameters.
- DATECVT. Optimized for DB2 with 6-digit legacy date formats I6YMD, I6MDY, I6DMY, P6YMD, P6MDY, P6DMY, A6YMD, A6MDY, and A6DMY.
- DATEDIFF. With YEAR, MONTH, and DAY parameters.
- DATEMOV. With BOW, EOW, BOM, EOM, BOQ, EOQ, BOY, and EOY parameters.
- DPART. With YEAR, MONTH, DAY, QUARTER, and WEEKDAY parameters.
- HADD. With YEAR, MONTH, DAY, HOUR, MINUTE, and SECOND parameters.
- HDATE.
- HDIFF. With YEAR, MONTH, DAY, HOUR, MINUTE, and SECOND parameters.
- HDTTM. With the following parameter combinations: "8,'HYYMDS'", "8,'HYYMDs'", and "10,'HYYMDm'".
- HGETC.
- HPART. With YEAR, MONTH, DAY, QUARTER, WEEKDAY, DAY-OF-YEAR, WEEK, HOUR, MINUTE, SECOND, MILLISECOND, and MICROSECOND parameters. The optimized HPART function with the WEEK parameter is compatible with FOCUS only in the presence of the WEEKFIRST=ISO2 setting.
- TODAY.
This feature implements a SET command that generates HOLD files as SQL_SCRIPT files when no format is specified on the ON TABLE HOLD command.
Note: If the adapter cannot generate SQL requests for a complex TABLE request (due to expression complexity or other reasons), the system automatically downgrades the HOLDFORMAT setting to BINARY for that request only. The procedure will run, but more slowly (with extract to disk). This can be used for application conversions to SQL_SCRIPT, such as BCEE-generated or MFACT-generated procedures.
The Web Console adapter configuration page for SQL-based adapters features a button that enables you to test the case-sensitivity setting of the targeted DBMS.
Variables that hold the values of SQLTAG and ABORTREPORT settings are available. You can use the following commands to find their values:
-TYPE &engine SQLTAG -TYPE &engine ABORTREPORT
where:
- engine
Is the adapter engine tag. For example, DB2 for DB2, ORA for Oracle, MSS for Microsoft SQL Server, DBC for Teradata, and so on.
When using HOLD with an SQLengine FORMAT, a new option enables you to use a bulk load procedure to load the table.
The following simplified functions are optimized to SQL:
- SUBSTRING
- LTRIM
- RTRIM
- TRIM_
- CHAR_LENGTH
- LOWER
- UPPER
The SQL Optimization Report provides optimization information for each function by adapter.
Note: Simplified functions are easier to use and are likely to be optimized in a wider range of engines than legacy functions.