Miglioramenti Linguaggio di Reporting
WebFOCUS è un sistema di controllo di informazioni completo con funzioni esaustive per il recupero e l'analisi dei dati. Questo sistema consente di creare prospetti facilmente e velocemente. Questo sistema fornisce inoltre funzioni per la creazione di prospetti altamente complessi, ma la sua forza risiede nella semplicità del linguaggio di richiesta. È possibile iniziare con query semplici e progredire a prospetti complessi, nella scoperta di ulteriori funzioni.
Il Release 8.1 include le nuove funzioni del linguaggio di Reporting, disponibili in Server Release 7.7 Versione 06.
xSpecificazione dell'ordine in elenchi dinamici di singola e multipla selezione della richiesta "e" commerciale
Nel Release 8.1 Versione 05, negli elenchi dinamici di singola e multi-selezione, è possibile specificare l'ordine dei valori recuperati dalle origini dati, usando l'opzione di elaborazione del parametro SORT. L'ordine predefinito è ascendente.
x
Sintassi: Come aggiungere un elenco a selezione singola dinamico di valori
'&variable.(FIND return_fieldname [,display_fieldname] IN datasource[|SORT=sortoption]).[description.]'
dove:
- &variabile
La variabile, inclusa la "e" commerciale (&), per cui si fornisce un elenco di valori.
- return_fieldname
Nome del campo contenente i possibili valori restituiti da FOCEXEC per le variabili.
- display_fieldname
Nome del campo contenente i possibili valori delle variabili visualizzati nel modulo di richiesta automatica.
- datasource
L'origine dati che contiene i campi specificati in return_fieldname e display_fieldname Se i campi si trovano in un file di riferimento incrociato di una origine dati usata in una unione, usare il nome dell'origine dati che contiene i campi.
- sortoption
Fornisce l'abilità di specificare come ordinare i valori restituiti per un elenco dinamico. I valori validi sono:
- ASCENDING, che ordina in ordine da basso a alto. Si tratta del valore predefinito quando non si specifica l'elaborazione di ordine.
- DESCENDING, che ordina l'ordine da alto a basso.
- description
Una descrizione opzionale della variabile.
Esempio: Aggiunta di un elenco dinamico di valori di sigola selezione in ordine descendente
La seguente procedura fornisce un elenco di valori validi per il campo del nome prodotto. Questo elenco viene popolato con valori dall'origine dati CENTORD. L'utente è in grado di selezione solo un valore dall'elenco.
-<description>This procedure reports on Inventory </description>
-<description>by state, storename and product number. </description>
-<heading> Please specify a state, storename and product name: </heading>
-DEFAULT &STATE=NY
TABLE FILE CENTORD
SUM QTY_IN_STOCK BY STATE BY STORENAME BY PROD_NUM
ON TABLE SUBHEAD
"Inventory Report"
WHERE STATE EQ '&STATE.2 letters for US State.'
WHERE STORENAME EQ '&STORENAME.(eMart,TV City,Web Sales).Store Name.'
WHERE PROD_NUM EQ '&PROD_NUM.(FIND PROD_NUM,PRODNAME IN CENTORD|SORT=DESCENDING).Product Name.'
END
x
Sintassi: Come aggiungere un elenco multiselezione dinamico di valori
&variable.({AND|OR}(FIND return_fieldname [,display_fieldname] IN datasource[|SORT=sortoption])).[description.]dove:
- &variabile
La variabile, inclusa la "e" commerciale (&), per cui si fornisce un elenco di valori.
- return_fieldname
Nome del campo contenente i possibili valori restituiti da FOCEXEC per le variabili.
- display_fieldname
Nome del campo contenente i possibili valori delle variabili visualizzati nel modulo di richiesta automatica.
- datasource
L'origine dati che contiene i campi specificati in return_fieldname e display_fieldname Se i campi si trovano in un file di riferimento incrociato di una origine dati usata in una unione, usare il nome dell'origine dati che contiene i campi.
- sortoption
Fornisce l'abilità di specificare come ordinare i valori restituiti per un elenco dinamico. I valori validi sono:
- ASCENDING, che ordina in ordine da basso a alto. Si tratta del valore predefinito quando non si specifica l'elaborazione di ordine.
- DESCENDING, che ordina l'ordine da alto a basso.
- descrizione
Una descrizione opzionale della variabile.
Esempio: Aggiunta di un elenco dinamico di valori di multiselezione in ordine discendente
La seguente procedura fornisce un elenco di valori validi per il campo stato. Questo elenco viene popolato con valori dall'origine dati CENTORD. L'utente è in grado di selezionare più di un valore dall'elenco.
-<description>This procedure reports on Inventory </description>
-<description>by store code, state and product name. </description>
-<heading> Please specify a storename, state and product name: </heading>
TABLE FILE CENTORD
SUM QTY_IN_STOCK BY STORE_CODE BY STATE BY PRODNAME
ON TABLE SUBHEAD
"Inventory Report"
WHERE STORE_CODE EQ &STORE_CODE.(OR(FIND STORE_CODE,STORENAME
IN CENTORD|SORT=DESCENDING)).Store Name.
WHERE STATE EQ &STATE.(OR(CA,IL,MA,NY,NJ,FL,TX)).2 letters for US State.
WHERE PRODNAME EQ '&PRODNAME.(FIND PRODNAME IN CENTORD).Product Name.'
END
xControllo della sottolineatura del titolo di colonna usando un attributo StyleSheet
Nel Release 8.1 Versione 05, l'attributo TITLELINE consente di controllare se i titoli di colonna sono sottolineati per l'emissione di prospetto.
x
Sintassi: Come controllare la sottolineatura del titolo di colonna usando un attributo StyleSheet
TYPE={REPORT|TITLE}, TITLELINE = (ON|OFF|SKIP)dove:
- ON
- Sottolinea i titoli di colonna. ON - È il valore predefinito.
- OFF
- Sostituisce la parte sottolineata con una riga vuota.
- SKIP
- Omette sia la sottolineatura che la riga in cui si sarebbe visualizza la sottolineatura.
Esempio: Controllo della sottolineatura del titolo di colonna usando un attributo StyleSheet
La seguente richiesta presenta un campo BY e ACROSS.
TABLE FILE GGSALES
SUM UNITS BY PRODUCT
ACROSS REGION
ON TABLE SET PAGE-NUM OFF
ON TABLE SET STYLE *
TYPE=REPORT, TITLELINE=ON, GRID=OFF, FONT=ARIAL,$
INCLUDE=endeflt.sty,$
END
Con il valore predefinito (ON) per TITLELINE, i titoli di colonna sono sottolineati.
Con TITLELINE=OFF, i titoli di colonna non sono sottolineati, ma la linea vuota, dove ci sarebbe dovuta essere la sottolineatura, è ancora presente.
Con TITLELINE=SKIP, sia la sottolineatura che la tiga vuota sono rimosse.
xImpedimento Flusso in Eccedenza Visuale
Delle volte, la dimensione definita per il formato USAGE di un campo potrebbe essere troppo piccola per aderire ai dati effettivi da visualizzare. Nei release precedenti, questo scenario comporta la visualizzazione di asterisci (***) nell'emissione di prospetto al posto del valore attuale. Le situazioni che causano uesto scenario includono:
- Se il valore di visualizzazione è superiore al formato di visualizzazione definito.
- Se si valore si aggrega, il valore sommato non aderisce nello spazio allocato per la colonna dal formato USAGE del campo.
x
Sintassi: Come impedire l'eccedenza della visuale
SET EXTENDNUM = {ON|OFF|AUTO}
dove:
- ON
-
Visualizza tutti i numeri completi, indipendentemente dal formato USAGE definito.
- INATTIVO
-
Visualizza asterisci quando il valore non aderisce allo spazio dedicato dal formato USAGE. Questo è il comportamento legacy.
- AUTO
-
Applica una impostazione ON o OFF, a seconda del formato di emissione e delle impostazioni SQUEEZE, come illustrato nella seguente tabella.
|
Formato
|
Impostazione SQUEEZE
|
EXTENDNUM
|
|---|
| PDF, PS, DHTML, PPT, PPTX | ON
INATTIVO | ON
INATTIVO |
| HTML, EXL2K, XLSX
| N/D
| ON
|
| BINARY, ALPHA
| N/D
| INATTIVO
|
| WP, altri formati delimitati
| N/D
| INATTIVO
|
AUTO è il valore predefinito.
x
Riferimento: Note per l'uso di SET EXTENDNUM=ON
Il richiamo di SET EXTENDNUM=ON potrebbe cambiare il layout di prospetto nei seguenti modi.
Modifiche nel layout di prospetto:
- Con formati stilizzati (PDF, PS, DHTML, HTML, EXL2K, XLSX, PPT, PPTX), la larghezza del prospetto si estende per accomodare la larghezza delle colonne dati. Questa situazione potrebbe cambiare la posizione del prospetto complessivo sulla pagina definita e, in alcune istanze, porta le colonne ad eccedere in una nuova pagina.
- Per PDF, DHTML, PPT e PPTX, l'impostazione SQUEEZE ON assicurerà il mantenimento dell'allineamento con ogni colonna.
- Per HTML, EXL2K e XLSX, l'allineamento verrà atomaticamente mantenuto, indipendentemente dalle impostazioni SQUEEZE.
- Con formati non stilizzati (WP), le colonne non si adattano per aderire ai nuovi valori, che potrebbe causare il disallineamento delle colonne dati.
Modifica di comportamento in sistemi operativi, dove il formato di numero definito non è supportato:
- I valori interi superiori a 2GB non possono essere visualizzati su computer di 32-bit. Quindi, questi valori interi su questi computer visualizzeranno valori scorretti.
- I numeri punto mobile (tipo F e D) che richiedono più di 31 cifre per la stamoa corretta continueranno a visualizzare asterischi. Per esempio, un campo con uso D33.30 e un valore di 10.0 si stamperà con asterisci, poiché necessita 30 zeri a destra del punto decimale e due cifre a sinistra.
xScalatura dinamica dell'emissione di prospetto HTML
È possibile attivare il parametro AUTOFIT per scalare automaticamente prospetti e grafici HTML a livello orizzontale, per riempire l'intero container (finestra o cornice) nelle proprie pagine del portale e HTML, come illustrato nella seguente immagine.
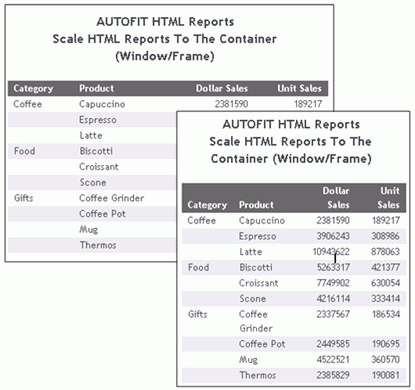
Per ulteriori informazioni sull'utilizzo del parametro AUTOFIT, vedere il manuale relativo a Sviluppo delle applicazioni di reporting.
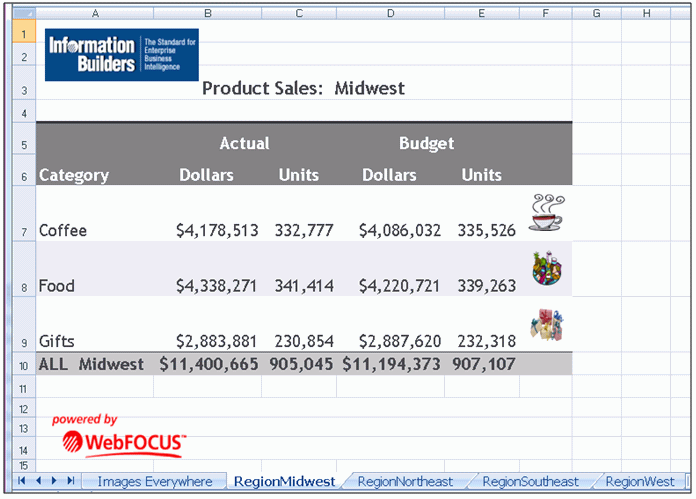
xImmagini incorporate in Workbook (XLSX) Microsoft Excel
I workbook XLSX sono in grado di contenere immagini incorporate in posizioni fisse in ogni area del prospetto WebFOCUS, incluse le intestazioni, piè di pagina e celle dati. Inoltre, è possibile posizionare i grafici su fogli elettronici individuali nei workbook composti, come illustrato nella seguente immagine.
xAbilità di cambiare lo stile font predefinito per FORMAT XLSX
I font disponibili e predefiniti per ogni formato di emissione sono definiti nel file fontmap.xml, gestito nel Reporting Server. Prima del Release 8.1 Versione 03, le definizioni per DHTML includevano anche i formati di Microsoft Office (XLSX, PPT, PPTX). Nel Release 8.1 Versione 03, è possibile definire definizioni font per il formato XLSX in modo separato, facilitando la personalizzazione dell'aspetto dei propri workbook XLSX. WebFOCUS usa Arial come font predefinito. Usare questa funzione per cambiare il font predefinito per corrispondere al font standard di Microsoft Office, Calibri, o al proprio standard aziendale. Per ulteriori informazioni su font maps, vedere il manuale Creazione di prospetti con il linguaggio di WebFOCUS.
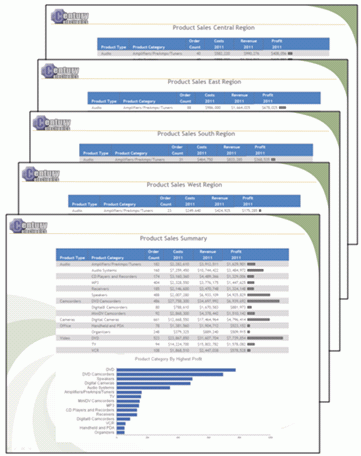
xFormato File Presentazione Microsoft PowerPoint (PPTX)
Il formato file PPTX è in grado di contenere prospetti, grafici ed immagini con le funzioni stile WebFOCUS, come anche popolare maschere PowerPoint contenenti Slide Master preimpostate e altro contenuto aziendale, come illustrato nella seguente immagine.
xUso del formato di visualizzazione PowerPoint PPTX
Con PowerPoint (PPTX), Microsoft® ha introdotto una migliore funzionalità in un nuovo formato file di presentazione. WebFOCUS Release 8.1 introduce la capacità di recuperare dati da qualsiasi origine dati WebFOCUS supportata e di generare una presentazione PPTX per l'analisi e distribuzione dati.
Il formato PPTX genera prospetti completamente stilizzati in formato di visualizzazione binario, che usa la stessa tecnologia binario usata per XLSL. Quando si specifica PPTX come formato di emissione, si crea una presentazione PowerPoint con una singola slide inclusiva del prospetto.
La procedura WebFOCUS genera una nuova presentazione, contenente i propri elementi di prospetto definiti, come intestazioni e subtotali, come anche la sintassi StyleSheet, come lo stile condizionale ed i drill down.
Inoltre, è possibile aggiungere multipli grafici e immagini ad una presentazione PowerPoint. Il formato di emissione PowerPoint è in grado di contenere una serie di grafici, posizionati ovunque su una slide per creare un layout visivo.
x
Uso di Maschere PowerPoint PPTX
È possibile posizionare l'emissione di prospetto su una slide specifica in una maschera PowerPoint. Questa azione consente di popolare presentazioni esistenti con Slide Master, stili e altro contenuto aziendale presente. Le maschere design PowerPoint (POTX) e le maschere con attivazione macro PowerPoint (POTM) sono memorizzate sul server ed è possibile distribuirle automaticamente con ReportCaster.
x
Sintassi: Come creare una emissione di prospetto PowerPoint PPTX
ON TABLE {PCHOLD|HOLD|SAVE} [AS name] FORMAT PPTX
[TEMPLATE {'template.potx'|'template.potm'} SLIDENUMBER n]
dove:
- nome
-
Nome del file di emissione PowerPoint.
- maschera
-
Nome del file maschera PowerPoint. Il file maschera deve avere almeno una slide vuota e deve essere salvato con o con l'estensione .POTX o .POTM, sulla propria directory di applicazione WebFOCUS Reporting Server.
Nota: Poiché estensioni diverse sono supportate per maschere PowerPoint, si consiglia di includere l'estensione nel nome della propria maschera.
- n
-
Il numero di slide in cui posizionare l'emissione di prospetto. Questo numero è opzionale se ma maschera ha solo una slide.
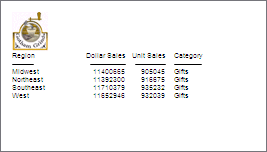
Esempio: Uso di una maschera PowerPoint PPTX
La seguente richiesta rispetto all'origine dati GGSALES inserisce un prospetto WebFOCUS nella maschera PowerPoint PPTX, chiamata mytemplate.potx, memorizzata nella directory dell'applicazione:
TABLE FILE GGSALES
HEADING
" "
" "
" "
" "
" "
SUM DOLLARS UNITS CATEGORY
BY REGION
ON TABLE SET PAGE-NUM NOLEAD
ON TABLE NOTOTAL
ON TABLE PCHOLD FORMAT PPTX TEMPLATE 'mytemplate.potx' SLIDENUMBER 3
ON TABLE SET HTMLCSS ON
ON TABLE SET STYLE *
TYPE=REPORT, FONT=ARIAL, SIZE=10,$
TYPE=HEADING, image=gglogo.gif, POSITION=(0.000000 0.000000),$
ENDSTYLE
END
L'emissione è:
xElaborazione interna delle richieste automatiche "e" commerciale di WebFOCUS Client
La prestazione e protezione della funzione Richiesta Automatica "E" Commerciale di WebFOCUS Release 8.1 è stata migliorata, poiché WebFOCUS Client non usa più maschere XSLT per creare JavaScript per la pagina Richiesta Automatica HTML.
In WebFOCUS Release 8.1, WebFOCUS Client usa l'XML restituito dal Reporting Server per creare JavaScript per la pagina HTML di Richiesta Automatica. Le maschere autoprompt_top.xslt e autoprompt_top_checked.xslt sono state convertite nella nuova implementazione del Release 8.1. Contattare i servizi di supporto clienti se, prima del Release 8.1, è stata creata e si sta usando una maschera XSLT personalizzata, o se si ha la necessità aziendale di richiedere la conversione di una delle maschere Richiesta Automatica legacy: autoprompt.xslt, autoprompt_checked.xslt, o autoprompt_simple.xslt.
xRidimensionamento automatico di un prospetto HTML HFREEZE
Una opzione AUTO è stata aggiunta al comando SCROLLHEIGHT con uso nella funzione di reporting HTML HFREEZE. L'opzione AUTO ridimensiona il prospetto HFREEZE nella pagina del browser o nella cornice della pagina.
Quando il browser viene ridimensionato manualmente, dopo la visualizzazione iniziale del prospetto HFREEZE, la dimensione del prospetto HFREEZE rimane la stessa. Selezionare l'opzione di aggiornamento di browser per ricaricare il prospetto HFREEZE, che eseguirà JavaScript, per calcolare la dimensione del prospetto HFREEZE all'interno della pagina o cornice corrente.
x
Sintassi: Come creare un'area scorrevole in un prospetto HTML
TYPE=REPORT,HFREEZE={OFF|ON|TOP|BOTTOM},[SCROLLHEIGHT={AUTO|nn[.n]}], $
dove:
- SCROLLHEIGHT=AUTO
-
Ridimensiona il prospetto HFREEZE nella pagina del browser o nella cornice della pagina.
- nn[.n]
-
L'altezza, in pollici, dell'area scorrevole. Il valore predefinito è 4 pollici.
xEsecuzione di rollup di calcoli su righe di riepilogo
Usando SUMMARIZE o RECOMPUTE, è possibile ricalcolare i valori alle interruzioni campo di ordinamento, ma questi calcoli usano il dati dettagliato per calcolare il valore della riga di riepilogo.
Uso di ROLL. operatore in congiuzione con un altro operatore prefisso su una riga di riepilogo ricalcola i valori di interruzione ordine, usando i valori dalle righe di riepilogo generate per l'interruzione ordine di livello inferiore.
Le combinazioni di operatore supportate sono:
- ROLL.SUM. (come ROLL). I campi alfanumerici sono supportati con SUM. Questo ritorna o il primo o l'ultimo valore, a seconda del parametro SUMPREFIX.
- ROLL.AVE.
- ROLL.MAX. (supportato con campi alfanumerici come anche campi numerici).
- ROLL.MIN. (supportato con campi alfanumerici come anche campi numerici).
- ROLL.FST. (supportato con campi alfanumerici come anche campi numerici).
- ROLL.LST. (supportato con campi alfanumerici come anche campi numerici).
- ROLL.CNT.
- ROLL.ASQ.
ROLL.prefisso su una riga di riepilogo indica che si eseguirà l'operazione prefisso sui valori di riepilogo dal comando di riepilogo del successivo livello inferiore.
Se ROLL. l'operatore da usare senza un altro operatore prefisso, si tratta come una SUM. Quindi, se il comando di riepilogo, per il campo BY inferiore, specifica AVE. e il campo successivo superiore specifica ROLL., il risultato sarà la somma della media. Per ottenere la media delle medie, si usa ROLL.AVE ad un livello superiore.
Nota: Con SUMMARIZE e SUB-TOTAL, gli stessi calcoli sono propagati a tutte le interruzioni di ordine di livello superiore.
x
Sintassi: Come Valori Riepilogo Roll Up
BY field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} [ROLL.][prefix1.]
[field1 field2 ...|*] [ROLL.][prefix2.] [fieldn ...]
O:
BY field
ON field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} ROLL.[prefix.]
[field1 field2 ...|*]
dove:
- ROLL.
-
Indica che i valori di riepilogo dovrebbero essere calcolati usando i valori di riepilogo dal successivo comando di riepilogo di livello inferiore.
- campo
-
Un campo BY nella richiesta.
- prefix1, prefix2
-
Operatori prefissi da usare per valori di riepilogo. Può essere uno dei seguenti operatori: SUM. (l'operatore predefinito se nessuno specificato), AVE., MAX., MIN., FST., LST., CNT., ASQ.
- field1 field2 fieldn
-
Campi da dover riepilogare.
- *
-
Indica che tutti i campi, numerici e alfanumerici, dovrebbero essere inclusi sulle righe di riepilogo. È possibile o usare l'asterisco per visualizzare tutte le colonne o fare riferimento a colonne specifiche che si desidera visualizzare.
Esempio: Roll up di un calcolo medio
La seguente richiesta rispetto all'origine dati GGSALES contiene due campi di ordinamento, REGION e ST. Il comando di riepilogo per REGION applica AVE. operatoe della somma dei valori di unità per ogni stato.
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SET PAGE NOPAGE
END
Sull'emissione, si esegue la media dei valori UNITS per ogni stato, per calcolare il subtotale per ogni regione. I valori UNITS per ogni stato, inoltre, si usano per calcolare la media della riga del totale complessivo.
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
TOTAL 45144 La seguente versione della richiesta aggiunge un comando di riepilogo per la riga del totale complessivo che include ROLL. operatore:
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SUBTOTAL ROLL.AVE. AS ROLL.AVE
ON TABLE SET PAGE NOPAGE
END
Sull'emissione, si esegue la media dei valori UNITS per ogni stato, per calcolare il subtotale di ogni regione e i valori del subtotale delle regioni si usa per calcolare la media della riga del totale complessivo:
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
ROLL.AVE 47330
Esempio: Propagazione di Rollup alle interruzione di ordine di livello superiore
La seguente richiesta rispetto all'origine dati GGSALES ha tre campi BY. Il comando SUBTOTAL per il campo di ordine PRODUCT specifica AVE. e il comando SUMMARIZE per il campo di ordine di livello superiore, REGION, specifica ROLL.AVE.
TABLE FILE GGSALES
SUM UNITS
BY REGION
BY PRODUCT
BY HIGHEST DATE
WHERE DATE GE 19971001
WHERE REGION EQ 'Midwest' OR 'Northeast'
WHERE PRODUCT LIKE 'C%'
ON PRODUCT SUBTOTAL AVE.
ON REGION SUMMARIZE ROLL.AVE. AS ROLL.AVE
ON TABLE SET PAGE NOPAGE
END
Sull'emissione, le righe dettagli per ogni stato si usano per calcolare la media per ogni prodotto. A causa di ROLL.AVE. al livello di regione, le medie per ogni prodotto sono usate per calcolare le medie per ogni regione e queste medie si usano per calcolare la media della riga del totale complessivo:
Region Product Date Unit Sales
------ ------- ---- ----------
Midwest Coffee Grinder 1997/12/01 4648
1997/11/01 3144
1997/10/01 1597
*TOTAL PRODUCT Coffee Grinder 3129
Coffee Pot 1997/12/01 1769
1997/11/01 1462
1997/10/01 2346
*TOTAL PRODUCT Coffee Pot 1859
Croissant 1997/12/01 7436
1997/11/01 5528
1997/10/01 6060
*TOTAL PRODUCT Croissant 6341
ROLL.AVE Midwest 3776
Northeast Capuccino 1997/12/01 1188
1997/11/01 2282
1997/10/01 3675
*TOTAL PRODUCT Capuccino 2381
Coffee Grinder 1997/12/01 1536
1997/11/01 1399
1997/10/01 1315
*TOTAL PRODUCT Coffee Grinder 1416
Coffee Pot 1997/12/01 1442
1997/11/01 2129
1997/10/01 2082
*TOTAL PRODUCT Coffee Pot 1884
Croissant 1997/12/01 4291
1997/11/01 6978
1997/10/01 4741
*TOTAL PRODUCT Croissant 5336
ROLL.AVE Northeast 2754
TOTAL 3265
x
Riferimento: Note per l'uso per ROLL.
- ROLL.prefisso su una riga di riepilogo indica che si eseguirà l'operazione prefisso sui valori di riepilogo dal comando di riepilogo del successivo livello inferiore.
- Se non si emette nessun comando di riepilogo al livello sotto a ROLL. e non si usa nessun'altro operatore in congiunzione con ROLL., si calcolerà un SUM. Se il livello inferiore aveva il comando di riepilogo ed è stato usato ROLL. con un altro operatore prefisso (per esempio, ROLL.AVE), si userà l'opratore prefisso specificato. Per esempio, ROLL.AVE. diventerà AVE.
- CNT. prefisso mostra il numero di righe dati visualizzate, non influenzato da MULTILINES.
- ROLL.CNT. prefisso mostra il numero di righe riepilogo visualizzate, non influenzato da MULTILINES.
xFunzioni Caratteri Semplificati
Sono state sviluppate nuove funzioni caratteri per facilitare la comprensione e per immettere gli argomenti richiesti. Queste funzioni presentano elenchi parametro semplificati, simili a quelli utilizzati dalle funzioni SQL. In alcuni casi, queste funzioni semplificate forniscono funzionalità leggermente diverse rispetto alle versioni precedenti o funzioni simili.
Le funzioni semplificate non presentano un argomento di emissione. Ciascuna funzione restituisce un valore con un tipo specifico di data.
Quando si utilizza questa funzione in una richiesta rispetto ad una origine dati relazionale, queste funzioni vengono ottimizzate (inoltrate a RDBMS per l'elaborazione).
Nota:
- Le funzioni di carattere semplificate sono supportate in Dialogue Manager.
- La funzioni dei caratteri semplificati non sono supportate in WebFOCUS Maintain.
x
CHAR_LENGTH: Restituzione della lunghezza dei caratteri di una stringa
La funzione CHAR_LENGTH restituisce la lunghezza, in caratteri, di una stringa. In ambienti Unicode, questa funzione usa la semantica dei caratteri, per far sì che la lunghezza in caratteri non sia la stessa della lunghezza in byte. Se la stringa include spazi finali, questi sono contanti nella lunghezza restituita. Quindi, se la stringa di origine del formato è di tipo An, il valore restituito sarà sempre n.
x
Sintassi: Come restituire la lunghezza in una stringa in caratteri
CHAR_LENGTH(source_string)
dove:
- source_string
-
Alfanumerico
La stringa, la quale lunghezza, viene restituita.
Il tipo di dati del valore della lunghezza restituita è Intero.
Esempio: Restituizione della lunghezza di una stringa
La seguente richiesta rispetto all'origine dati EMPLOYEE crea un campo virtuale chiamato LASTNAME di tipo A15V che contiene LAST_NAME con gli spazi finali rimossi. Questa richiesta usa, quindi, CHAR_LENGTH per restituire il numero di caratteri.
DEFINE FILE EMPLOYEE
LASTNAME/A15V = RTRIM(LAST_NAME);
END
TABLE FILE EMPLOYEE
SUM LAST_NAME NOPRINT AND COMPUTE
NAME_LEN/I3 = CHAR_LENGTH(LASTNAME);
BY LAST_NAME
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
LAST_NAME NAME_LEN
--------- --------
BANNING 7
BLACKWOOD 9
CROSS 5
GREENSPAN 9
IRVING 6
JONES 5
MCCOY 5
MCKNIGHT 8
ROMANS 6
SMITH 5
STEVENS 7
x
DIGITS: Conversione di un numero ad una stringa di caratteri
Dato un numero, DIGITS lo converte in una stringa di caratteri di lunghezza specifica Il formato del campo che contiene il numero deve essere intero.
x
Sintassi: Come convertire un numero in una stringa di caratteri
DIGITS(number,length)
dove:
- numero
-
Valore intero
Il numero da convertire, memorizzato in un campo con tipo dati Intero.
- length
-
Intero tra 1 e 10
Lunghezza della stringa di carattere restituita. Se lunghezza è più lunga del numero di cifre nel numero convertito, il valore restituito viene riempito sulla sinistra con dei zeri. Se lunghezza è più corta del numero di cifre nel numero convertito, il valore restituito viene troncato sulla sinistra.
Esempio: Conversione di un numero in una stringa di caratteri
La seguente richiesta rispetto all'origine dati WF_RETAIL_LITE converte -123.45 e ID_PRODUCT in stringhe di caratteri:
DEFINE FILE WF_RETAIL_LITE
MEAS1/I8=-123.45;
DIG1/A6=DIGITS(MEAS1,6) ;
DIG2/A6=DIGITS(ID_PRODUCT,6) ;
END
TABLE FILE WF_RETAIL_LITE
PRINT MEAS1 DIG1
ID_PRODUCT DIG2
BY PRODUCT_SUBCATEG
WHERE PRODUCT_SUBCATEG EQ 'Flat Panel TV'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
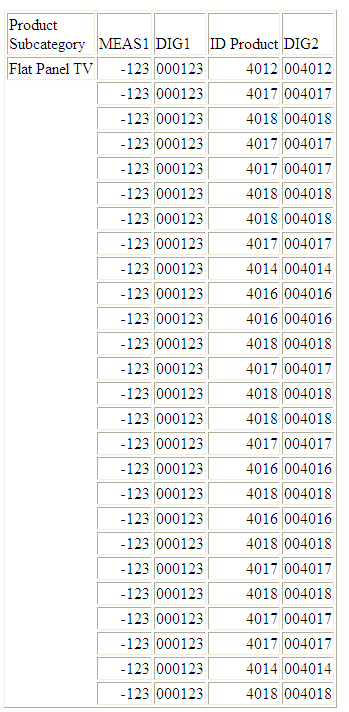
x
Riferimento: Note per l'uso per DIGITS
- Solo i numeri formato I verrano convertiti. I formati D, P e F generano messaggi di errore e dovrebbero essere convertiti in I prima dell'uso della funzione DIGITS. È possibile convertire il limite del numero in 2GB.
- Gli interi negativi sono convertiti in interi positivi.
- I formati interi con posizioni decimali sono troncati.
- DIGITS non è supportato in Dialogue Manager.
x
LPAD: Riempimento sinistro di una stringa di caratteri
LPAD usa un carattere e lunghezza di emissione specifici per restituire una stringa di caratteri riempita a sinistra con quel carattere.
x
Sintassi: Come riempire una stringa di carattere a sinistra
LPAD(string, out_length, pad_character)
dove:
- stringa
-
Alfanumerico di lunghezza fissa
Una stringa da riempire al lato sinistro.
- out_length
-
Valore intero
Lunghezza della stringa di emissione dopo il riempiemento.
- pad_character
-
Alfanumerico di lunghezza fissa
Carattere singolo per il riempimento.
Esempio: Riempimento sinistro di una stringa
Nella seguente richiesta rispetto all'origine dati WF_RETAIL, LPAD riempie a sinistra la colonna PRODUCT_CATEGORY con i simboli @:
DEFINE FILE WF_RETAIL
LPAD1/A25 = LPAD(PRODUCT_CATEGORY,25,'@');
DIG1/A4 = DIGITS(ID_PRODUCT,4);
END
TABLE FILE WF_RETAIL
SUM DIG1 LPAD1
BY PRODUCT_CATEGORY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=DATA,FONT=COURIER,SIZE=11,COLOR=BLUE,$
END
L'emissione è:

x
Riferimento: Note per l'uso per LPAD
- Per usare le virgolette singole come carattere di riempimento, è necessario raddoppiarla e racchiudere le due virgolette singole all'intero delle altre virgolette singole (LPAD(COUNTRY, 20,''''). È possibile usare una variabile "e" commerciale nelle virgolette per questo parametro, ma non è possibile usare un campo, virtuale o reale.
- È possibile avere una immissione alfanumerica di lunghezza variabile o fissa.
- L'emissione, quando ottimizzata a SQL, sarà sempre il tipo dati VARCHAR.
- Se l'emissione viene specificata come più corta dell'emissione originale, i dati originali verranno troncati, lasciando solo i caratteri di riempimento. La lunghezza di emissione può essere specificata come intero positivo o una &variabile senza quota (indicando un numero).
x
LOWER: Restituzione di una stringa con tutte le lettere minuscole
La funzione LOWER prende una stringa di origine e restituisce una stringa dello stesso tipo di dati con tutte le lettere tradotte in caratteri minuscoli.
x
Sintassi: Come restituire una stringa con tutte le lettere minuscole
LOWER(source_string)
dove:
- source_string
-
Alfanumerico
Stringa da convertire i caratteri minuscoli.
La stringa restituita è lo stesso tipo di dati e lunghezza della stringa di origine.
Esempio: Conversione di una stringa in caratteri minuscoli
Nella seguente richiesta rispetto all'origine dati EMPLOYEE, LOWER converte il campo LAST_NAME in caratteri minuscoli e memorizza il risultato in LOWER_NAME.
TABLE FILE EMPLOYEE
PRINT LAST_NAME AND COMPUTE
LOWER_NAME/A15 = LOWER(LAST_NAME);
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
LAST_NAME LOWER_NAME
--------- ----------
STEVENS stevens
SMITH smith
JONES jones
SMITH smith
BANNING banning
IRVING irving
ROMANS romans
MCCOY mccoy
BLACKWOOD blackwood
MCKNIGHT mcknight
GREENSPAN greenspan
CROSS cross
x
LTRIM: Rimozione di spazi dall'estremità sinistra di una stringa
La funzione TRIM rimuove tutti gli spazi dall'estremità sinistra di una stringa.
x
Sintassi: Come rimuovere gli spazi dall'estremità sinistra di una stringa
LTRIM(source_string)
dove:
- source_string
-
Alfanumerico
La stringa da ritagliare sulla sinistra.
Il tipo di dati della stringa restituita è AnV, con la stessa lunghezza massima della stringa di origine.
Esempio: Rimozione di spazi dall'estremità sinistra di una stringa
Nella seguente richiesta rispetto all'origine dati MOVIES, il campo DIRECTOR viene giustificato a destra e memorizzato nel campo virtuale RDIRECTOR. Quindi, LTRIM rimuove gli spazi iniziali dal campo RDIRECTOR:
DEFINE FILE MOVIES
RDIRECTOR/A17 = RJUST(17, DIRECTOR, 'A17');
END
TABLE FILE MOVIES
PRINT RDIRECTOR AND
COMPUTE
TRIMDIR/A17 = LTRIM(RDIRECTOR);
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
RDIRECTOR TRIMDIR
--------- -------
ABRAHAMS J. ABRAHAMS J.
BROOKS R. BROOKS R.
BROOKS J.L. BROOKS J.L.
x
POSITION: Restituzione della prima posizione di una sottostringa in una stringa d'origine
La funzione POSITION restiutisce la prima posizione (in caratteri) di una stringa secondaria in una stringa di origine.
x
Sintassi: Come ritornare alla prima posizione di una sottostringa in una stringa d'origine
POSITION(pattern, source_string)
dove:
- schema
-
Alfanumerico
La sottostringa la quale posizione si desidera localizzare. La stringa può essere corta quanto un solo carattere, incluso un singolo spazio.
- source_string
-
Alfanumerico
La stringa in cui trovare il modello.
Il tipo di dati del valore restituito è Intero.
Esempio: Restituizione della prima posizione di una stringa secondaria.
Nella seguente richiesta rispetto all'origine dati EMPLOYEE, POSITION determina la posizione della prima lettera I in LAST_NAME e memorizza il risultato in I_IN_NAME:
TABLE FILE EMPLOYEE
PRINT LAST_NAME AND COMPUTE
I_IN_NAME/I2 = POSITION('I', LAST_NAME);
ON TABLE SET PAGE NOPAGE
END L'emissione è:
LAST_NAME I_IN_NAME
--------- ---------
STEVENS 0
SMITH 3
JONES 0
SMITH 3
BANNING 5
IRVING 1
ROMANS 0
MCCOY 0
BLACKWOOD 0
MCKNIGHT 5
GREENSPAN 0
CROSS 0
x
RTRIM: Rimozione di spazi dall'estremità destra di una stringa
La funzione RTRIM rimuove tutti gli spazi dall'estremità destra di una stringa.
x
Sintassi: Come rimuovere gli spazi dall'estremità destra di una stringa
RTRIM(source_string)
dove:
- source_string
-
Alfanumerico
La stringa da ritagliare sulla destra.
Il tipo di dati della stringa restituita è AnV, con la stessa lunghezza massima della stringa di origine.
Esempio: Rimozione di spazi dall'estremità destra di una stringa
La seguente richiesta rispetto all'origine dati MOVIES crea il campo DIRSLASH, che contiene una sbarra alla fine del campo DIRECTOR. Quindi, tale richiesta crea il campo TRIMDIR, che ritaglia gli spazi finali dal campo DIRECTOR e posiziona una barra alla fine di quel campo:
TABLE FILE MOVIES
PRINT DIRECTOR NOPRINT AND
COMPUTE
DIRSLASH/A18 = DIRECTOR|'/';
TRIMDIR/A17V = RTRIM(DIRECTOR)|'/';
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
Sull'emissione, le sbarre mostrano che gli spazi finali nel campo DIRECTOR sono stati rimossi nel campo TRIMDIR:
DIRSLASH TRIMDIR
-------- -------
ABRAHAMS J. / ABRAHAMS J./
BROOKS R. / BROOKS R./
BROOKS J.L. / BROOKS J.L./
x
SUBSTRING: Estrazione una stringa secondaria da una stringa di origine
La funzione SUBSTRING estrae una stringa secondaria da una stringa di origine. Se la posizione finale specificata per la stringa secondaria supera la fine della stringa di origine, la posizione dell'ultimo carattere della stringa di origine diventa la posizone finale della stringa secondaria.
x
Sintassi: Come estrarre una stringa secondaria da una stringa di origine
SUBSTRING(source_string, start_position, length_limit)
dove:
- source_string
-
Alfanumerico
Stringa dalla quale estrarre una sottostringa. Si può trattare di un campo, un valore letterale in virgolette singole ('), o di una variabile.
- start_position
-
Valore intero
Posizione iniziale della sottostringa in source_string. Se la posizione è 0, si tratta come 1. Se la posizione è negativa, la posizione iniziale si conta all'indietro dalla fine di source_string.
- lenght_limit
-
Valore intero
Limite per la lunghezza della sottostringa. La posizione finale della stringa secondaria viene calcolata come start_position + lenght_limit - 1. Se la posizione calcolata oltre la fine della stringa di origine, la posizione dell'ultimo carattere di source_string diventa la posizione finale.
Il tipo di dati della stringa secondaria restituita è AnV.
Esempio: Estrazione di una stringa secondaria da una stringa di origine
Nella seguente richiesta, POSITION determina la posizione della prima lettera I in LAST_NAME e memorizza il risultato in I_IN_NAME. SUBSTRING quindi estrae tre caratteri che iniziano con la lettera I da LAST_NAME e memorizza i risultati in I_SUBSTR.
TABLE FILE EMPLOYEE
PRINT
COMPUTE
I_IN_NAME/I2 = POSITION('I', LAST_NAME); AND
COMPUTE
I_SUBSTR/A3 =
SUBSTRING(LAST_NAME, I_IN_NAME, I_IN_NAME+2);
BY LAST_NAME
ON TABLE SET PAGE NOPAGE
END L'emissione è:
LAST_NAME I_IN_NAME I_SUBSTR
--------- --------- --------
BANNING 5 ING
BLACKWOOD 0 BL
CROSS 0 CR
GREENSPAN 0 GR
IRVING 1 IRV
JONES 0 JO
MCCOY 0 MC
MCKNIGHT 5 IGH
ROMANS 0 RO
SMITH 3 ITH
3 ITH
STEVENS 0 ST
x
RPAD: Riempimento destro di una stringa di caratteri
RPAD usa un carattere e lunghezza di emissione specifiche per restituire una stringa di caratteri riempita sulla destra con quel carattere.
x
Sintassi: Come riempire una stringa di caratteri sulla destra
RPAD(string, out_length, pad_character)
dove:
- stringa
-
Alfanumerico
Una stringa da riempire sul lato destro.
- out_length
-
Valore intero
Lunghezza della stringa di emissione dopo il riempiemento.
- pad_character
-
Alfanumerico
Carattere singolo per il riempimento.
Esempio: Riempimento a destra di una stringa
Nella seguente richiesta rispetto all'origine dati WF_RETAIL, RPAD riempie a destra la colonna PRODUCT_CATEGORY con i simboli @:
DEFINE FILE WF_RETAIL
RPAD1/A25 = RPAD(PRODUCT_CATEGORY,25,'@');
DIG1/A4 = DIGITS(ID_PRODUCT,4);
END
TABLE FILE WF_RETAIL
SUM DIG1 RPAD1
BY PRODUCT_CATEGORY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=DATA,FONT=COURIER,SIZE=11,COLOR=BLUE,$
END
L'emissione è:
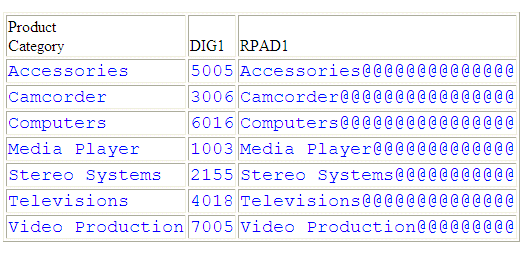
x
Riferimento: Note per l'uso per RPAD
- La stringa di emissione può essere il tipo di dati AnV, VARCHAR, TX e An.
- L'emissione può essere solo AnV o An.
- Quando si lavora con colonne VARCHAR relazionali, non c'è bisogno di troncare gli spazi finali dal campo, se non desiderati. Tuttavia, con i campi An e AnV derivati dai campi An, gli spazi finali sono parte dei dati e verranno inclusi nell'emissione, con il riempimento posizionato a destra di queste posizioni. È possibile usare TRIM e TRIMV per rimuovere questi spazi finali prima di applicare la funzione RPAD.
x
TOKEN: Estrazione di un token da una stringa
La funzione TOKEN estrae un token (stringa secondaria) basata su un numero token con un carattere delimitatore.
x
Sintassi: Come estrarre un token da una stringa
TOKEN(string, delimiter, number)
dove:
- stringa
-
Alfanumerico di lunghezza fissa
Stringa di caratteri dalla quale estrarre il token.
- delimitatore
-
Alfanumerico di lunghezza fissa
Un delimitatore di carattere singolo.
- numero
-
Valore intero
Numero di token da estrarre.
Esempio: Estrazione di un token da una stringa
TOKEN estrae il secondo token dalla colonna PRODUCT_SUBCATEG, dove il delimitatore è la lettera P:
DEFINE FILE WF_RETAIL_LITE
TOK1/A20 =TOKEN(PRODUCT_SUBCATEG,'P',2);
END
TABLE FILE WF_RETAIL_LITE
SUM TOK1 AS Token
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
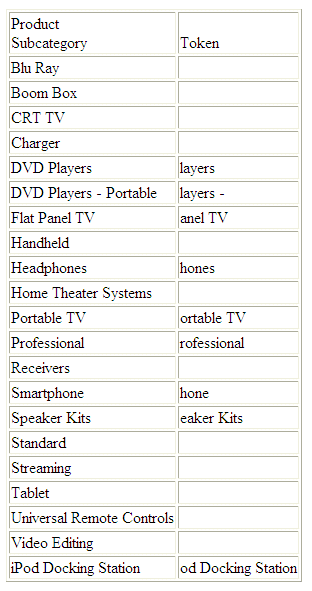
x
TRIM_: Rimozione di caratteri iniziali, caratteri finali o entrambi da una stringa
TRIM_function rimuove tutte le ricorrenze di una singolo carattere da o l'inizio di una stringa, la fine di una stringa o da entrambi.
x
Sintassi: Come rimuovere i caratteri iniziali, i caratteri finali o entrambi da una una stringa
TRIM_(trim_where, trim_character, source_string)
dove:
- trim_where
-
Parola chiave
Definisce dove ritagliare la stringa di origine. I valori validi sono:
-
LEADING, che rimuove ricorrenze iniziali.
-
TRAILING, che rimuove le ricorrenze finali.
-
BOTH, che rimuove le ricorrenze iniziali e finali.
- trim_character
-
Alfanumerico
Un carattere singolo, racchiuso tra virgolette ('), le quali ricorrenze devono essere rimosse da source_string. Per esempio, il carattere può essere uno spazio vuoto (‘ ‘).
- source_string
-
Alfanumerico
Stringa da tagliare.
Il tipo di dati della stringa secondaria restituita è AnV.
Esempio: Taglio di un carattere da una stringa
Nella seguente richiesta, TRIM_ rimuove le ricorrenze iniziali del carattere 'B' dal campo DIRECTOR:
TABLE FILE MOVIES
PRINT DIRECTOR AND
COMPUTE
TRIMDIR/A17 = TRIM_(LEADING, 'B', DIRECTOR);
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
DIRECTOR TRIMDIR
-------- -------
ABRAHAMS J. ABRAHAMS J.
BROOKS R. ROOKS R.
BROOKS J.L. ROOKS J.L.
x
UPPER: Restituzione di una stringa con tutte le lettere maiuscole
La funzione UPPER prende una stringa di origine e restituisce una stringa dello stesso tipo di dati con tutte le lettere tradotte in caratteri minuscoli.
x
Sintassi: Come restituire una stringa con tutte le lettere maiuscole
UPPER(source_string)
dove:
- source_string
-
Alfanumerico
Stringa da convertire in lettere maiuscole.
La stringa restituita è lo stesso tipo di dati e lunghezza della stringa di origine.
Esempio: Conversione di lettere in caratteri maiuscoli
Nella seguente richiesta, LCWORD converte LAST_NAME in caratteri misti. UPPER converte il campo LAST_NAME_MIXED in caratteri maiuscoli:
DEFINE FILE EMPLOYEE
LAST_NAME_MIXED/A15=LCWORD(15, LAST_NAME, 'A15');
LAST_NAME_UPPER/A15=UPPER(LAST_NAME_MIXED) ;
END
TABLE FILE EMPLOYEE
PRINT LAST_NAME_UPPER AND FIRST_NAME
BY LAST_NAME_MIXED
WHERE CURR_JOBCODE EQ 'B02' OR 'A17' OR 'B04';
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
LAST_NAME_MIXED LAST_NAME_UPPER FIRST_NAME
--------------- --------------- ----------
Banning BANNING JOHN
Blackwood BLACKWOOD ROSEMARIE
Cross CROSS BARBARA
Mccoy MCCOY JOHN
Mcknight MCKNIGHT ROGER
Romans ROMANS ANTHONY
xFunzioni data e data-ora semplificate
Sono state sviluppate nuove funzioni data e data-ora per facilitare la comprensione e per immettere gli argomenti richiesti. Queste funzioni presentano elenchi parametro semplificati, simili a quelli utilizzati dalle funzioni SQL. In alcuni casi, queste funzioni semplificate forniscono funzionalità leggermente diverse rispetto alle versioni precedenti o funzioni simili.
Le funzioni semplificate non presentano un argomento di emissione. Ciascuna funzione restituisce un valore con un tipo specifico di data.
Quando si utilizza questa funzione in una richiesta rispetto ad una origine dati relazionale, queste funzioni vengono ottimizzate (inoltrate a RDBMS per l'elaborazione).
I formati data standard e data-ora fanno riferimento alla sintassi YYMD e HYYMD (date non memorizzate in campi numerici o alfanumerici). Le date senza questi formati devono essere convertire prima di essere utilizzate nelle funzioni semplificate. È possibile usare i valori data-ora con la funzione DT.
Tutti gli argomenti possono essere o nomi campi, valori letterali o variabili "e" commerciale.
x
DTADD: Incremento di un componente data o data-ora
Data una data in formato data standard o data-ora, DTADD restituisce una nuova data dopo aver aggiunto il numero specificato o un componente supportato. Il formato data restituito è l stesso del formato data d'immissione.
x
Sintassi: Come incrementare un componente data o data-ora
DTADD(date, component, increment)
dove:
- data
-
Data o data-ora
Valore data-ora o data da incrementare.
- componente
-
Parola chiave
Il componente da incrementare. Componenti validi (e valori accettabili) sono:
- YEAR (1-9999)
- QUARTER (1-4)
- MONTH (1-12)
- WEEK (1-53). Questo elemento viene influenzato dall'impostazione WEEKFIRST.
- DAY (del mese, 1-31)
- HOUR (0-23)
- MINUTE (0-59)
- SECOND (0-59)
- incrementazione
-
Valore intero
Il valore (negativo o positivo) da aggiungere al componente.
Esempio: Incremento del componente DAY di una data
La seguente richiesta rispetto all'origine dati WF_RETAIL aggiunge tre giorni alla data di nascita dei dipendenti:
DEFINE FILE WF_RETAIL
NEWDATE/YYMD = DTADD(DATE_OF_BIRTH, DAY, 3);
MGR/A3 = DIGITS(ID_MANAGER, 3);
END
TABLE FILE WF_RETAIL
SUM MGR NOPRINT DATE_OF_BIRTH NEWDATE
BY MGR
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
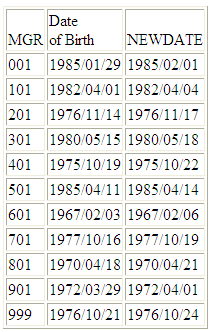
x
Riferimento: Note per l'uso per DTADD
- È possibile manipolare ogni elemento in modo separato. Quindi, se si desidera aggiungere 1 anno e 1 giorno ad una data, è necessario chiamare la funzione due volte, una per YEAR (è necessario eseguire l'anno bisestile) e uno per DAY. È possibile annidare le funzioni semplificate in una sola espressione, o crearle e applicarle in espressioni DEFINE O COMPUTE separate.
- Con riguardo alla convalida dei parametri, DTADD non consentirà nulla ma solamente l'uso di una data standard o data-ora nel primo parametro.
- L'incremento non è selezionato e l'utente dovrebbe essere a conoscenza che i numeri decimali non sono supportati e verranno troncati. Qualsiasi combinazione di valori che aumenta YEAR oltre a 9999 resituisce la data di immissione come il valor e senza messaggio. Se l'utente riceve la data di immissione quando si aspetta qualcos'altro, è possiible che ci sia stato un errore.
x
DTDIFF: Restituzione del numero di confini del componente tra valori data e data-ora.
Fornite due date in formati data standard e data-ora, DTDIFF restiutisce il numero dei confini del componente dato tra due date. Il valore restituito presenta formato intero per i componenti del calendario o formato punto mobile di precisione doppia per i componenti ora.
x
Sintassi: Come restituire il numero di confini del componente
DTDIFF(end_date, start_date, component)
dove:
-
end_date
-
Data o data-ora
La data finale in formato Data-Ora o data standard. Se questa data viene fornita in formato data standard, tutti componenti ora sono considerati di valore zero.
- start_date
-
Data o data-ora
La data iniziale in formato data ora o data standard. Se questa data viene fornita in formato data standard, tutti componenti ora sono considerati di valore zero.
- componente
-
Parola chiave
Il componente in cui si calcola il numero di confini. Per esempio, QUARTER trova la differenza in trimestri tra due date. Componenti validi (e valori accettabili) sono:
- YEAR (1-9999)
- QUARTER (1-4)
- MONTH (1-12)
- WEEK (1-53). Questo elemento viene influenzato dall'impostazione WEEKFIRST.
- DAY (del mese, 1-31)
- HOUR (0-23)
- MINUTE (0-59)
- SECOND (0-59)
Esempio: Ritorno del numero dei giorni della settimana tra due date
La seguente richiesta rispetto all'origine dati WF_RETAIL calcola la data dei dipendenti quando assunti:
DEFINE FILE WF_RETAIL
YEARS/I9 = DTDIFF(START_DATE, DATE_OF_BIRTH, YEAR);
END
TABLE FILE WF_RETAIL
PRINT START_DATE DATE_OF_BIRTH YEARS AS 'Hire,Age'
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AA'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
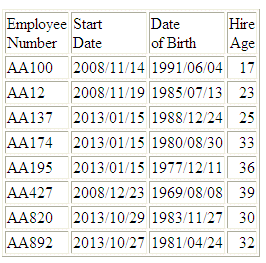
x
DTPART: Restituzione di un componente data o data-ora in formato intero
Data una data in formato data standard o data-ora ed un componente, DTPART restituisce il valore componente in formato intero.
x
Sintassi: Come restituire un componente data o data-ora in formato intero
DTPART(date, component)
dove:
- data
-
Data o data-ora
La data in formato data-ora o data standard.
- componente
-
Parola chiave
Il componente da estrarre in formato intero. Componenti validi (e valori) sono:
- YEAR (1-9999).
- QUARTER (1-4).
- MONTH (1-12).
- WEEK (dell'anno, 1-53). Questo elemento viene influenzato dall'impostazione WEEKFIRST.
- DAY (del mese, 1-31).
- DAY_OF_YEAR (1-366).
- WEEKDAY (giorno della settimana, 1-7). Questo elemento viene influenzato dall'impostazione WEEKFIRST.
- HOUR (0-23).
- MINUTE (0-59).
- SECOND (0-59.)
- MILLISECOND (0-999).
- MICROSECOND (0-999999).
Esempio: Estrazione del componente trimestre come valore intero
La seguente richiesta rispetto all'origine data WF_RETAIL estrae il componente QUARTER dalla data di inizio del dipendente:
DEFINE FILE WF_RETAIL
QTR/I2 =DTPART(START_DATE, QUARTER);
END
TABLE FILE WF_RETAIL
PRINT START_DATE QTR AS Quarter
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AH'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
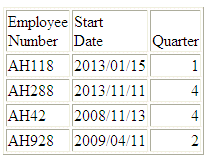
x
DTRUNC: Restituzione dell'inizio di un periodo per una certa data
Data una data o timestamp e un componente, DTRUNC restituisce la prima data all'interno del periodo specificato da quel componente.
x
Sintassi: Come restituire la prima data di un periodo
DTRUNC(date_or_timestamp, date_period)
dove:
- date_or_timestamp
-
Data o data-ora
Data dell'indicatore orario d'interesse.
- date_period
-
Il periodo la quale data di inizio si desidera trovare. Può essere una delle seguenti:
- DAY, restituisce il giorno del mese (1-31).
- YEAR. restituisce l'anno (1-9999).
- MONTH, restituisce il mese (1-12).
- QUARTER, restituisce il trimestre (1-4).
Esempio: Restituizione della prima data in un periodo di tempo
La seguente richiesta rispetto all'origine data WF_RETAIL, DTRUNC restituisce la prima data del trimestre, data la data d'inizio del dipendente:
DEFINE FILE WF_RETAIL
QTRSTART/YYMD = DTRUNC(START_DATE, QUARTER);
END
TABLE FILE WF_RETAIL
PRINT START_DATE QTRSTART AS 'Start,of Quarter'
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AH'
ON TABLE SET PAGE NOPAGE
END
L'emissione è:
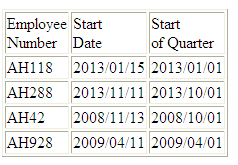
xCHECKPRIVS: Recupero dello stato di privilegio per l'utente connesso
Dato un codice di privilegio, CHECKPRIVS restituisce il valore Y, se l'utente connesso ha quel privilegio, o N se l'utente non ha il pivilegio o il privilegio non esiste.
Nota: È possibile visualizzare il proprio elenco di privilegi generali facendo clic sul pulsante Console (C), nell'angolo in alto a sinistra della finestra, selezionando Console Personale/Mostra i miei privilegi generali. Un utente con privilegi di Amministratore Server è inoltre in gardo di visualizzare l'elenco di privilegi generali sulla pagina di Controllo Accesso, facendo clic con il tasto destro del mouse su un ID utente, selezionando Proprietà dal menu contestuale e facendo clic sulla scheda Privilegi Generali sulla pagina Proprietà.
x
Sintassi: Come recuperare lo stato di privilegio per l'utente connesso
CHECKPRIVS(privcode, output)
dove:
- privcode
-
Il codice di privilegio per cui recuperare lo stato.
- emissione
-
Alfanumerico
Nome del campo che contiene il risultato o formato del valore di emissione racchiuso tra virgolette singole.
Esempio: Recupero dello stato di privilegio per l'utente connesso
La seguente richiesta recupera lo stato di privilegio ADPTP (Configurazione Adattatore Dati):
-SET &PRIVSTATE = CHECKPRIVS(ADPTP,'A1');
-TYPE Privilege State is: &PRIVSTATE
L'emissione è:
Privilege State is: Y
xAggiunta di una verifica valore in RESTRICT=NOPRINT
In release precedenti, una restrizione RESTRICT=NOPRINT DBA visualizzava tutti i valori o solo i valori predefiniti (vuoto, zero o MISSING).
Questa estensione opzionale in RESTRICT=NOPRINT DBA consente di usare una clausola espressione VALUE= nel comando RESTRICT. L'espressione verrà valutata e il valore si visualizzerà solo se l'espressione valuta true per quel valore. Qualsiasi valore, la cui espressione valuta false, sarà sostituito sull'emissione da un altro valore predefinito.
Quindi, un comando DBA che include la seguente restrizione visualizzerà solo il valore true di SEATS, quando COUNTRY ha il valore 'ENGLAND'. Altrimenti, i valori predefiniti sono visualizzati:
RESTRICT=NOPRINT, NAME=SEATS, VALUE= COUNTRY EQ 'ENGLAND';,$
xUso di ACCEPT=SYNONYM in un file master
La funzionalità di ACCEPT in un file master è stata estesa. Quando posizionata su una dichiarazione FIELD, è possibile usare questa funzionalità per controllare i valori che si visualizzano in una finestra di dialogo filtro (WHERE). Quando si usa una variabile "e" commerciale globale nel file master, è possibile usarla per controllare i valori visualizzati dalla funzione Richiesta Automatica "E" Commerciale.
L'attributo ACCEPT supporta i seguenti tipi di operazioni:
- ACCEPT = value1 OR value2 ...
Questa opzione si usa per specificare uno o multipli valori accettabili.
- ACCEPT = value1 TO value2
Questa opzione si usa per specificare una serie di valori accettabili.
- ACCEPT = FIND
Qusta opzione si usa per convalidare dati di transazione in entrata, rispetto ad un valore da una origine dati FOCUS, quando si eseguono operazioni di manutenzione su un'altra origine dati. FIND è solo supportato per origini dati FOCUS e non si applica a sinonimi abilitati OLAP. Notare inoltre che, nell'ambiente Maintain, FIND non è supportato quando si sviluppa un sinonimo.
- ACCEPT = DECODE
Questa opzione si usa per fornire coppie di valori per la richiesta "e" commerciale automatica. Ogni coppia consiste in un valore da poter ricercare nell'origine dati e ad un valore corrispondente per la visualizzazione.
- ACCEPT = FOCEXEC
Questa opzione si usa per recuperare coppie di valori, eseguendo un FOCEXEC. Ogni coppia consiste in un valore da poter ricercare nell'origine dati e ad un valore corrispondente per la visualizzazione.
- ACCEPT = SYNONYM
Questa opzione si usa per ricercare valori in un'altra origine dati e per recuperare un valore di visualizzazione corrispondente. I valori del campo di ricerca devono esistente in entrambe le origini dati, sebbene non devono avere nomi campo corrispondenti. Si fornisce il nome del sinonimo, il nome campo di ricerca e il nome campo di visualizzazione.
x
Sintassi: Come usare ACCEPT=SYNONYM in un file master
ACCEPT=SYNONYM(lookup_field AS display_field IN lookup_synonym)
dove:
- lookup_field
-
Il campo in lookup_synonym, il quale valore sarà usato nel filtro (dialogo WHERE) o dalla funzione di richiesta automatica "e" commerciale, che sarà paragonata al campo con l'attributo ACCEPT.
- display_field
-
Il campo in lookup_synonym, il quale valore si visualizzerà per la selezione nel dialogo filtro o nell'elenco a discesa di richiesta automatica "e" commerciale.
- lookup_synonym
-
Il nome del sinonimo che descrive i dati di ricerca.
xUso di multipli operatori prefissi sulla stessa misura in SUBTOTAL
È ora possibile fare riferimento ad un campo con più operatori prefissi in un comando di riepilogo, usando l'operatore prefisso per differenziare tra i campi con più operatori.
Usando operatori prefissi su righe di riepilogo richiede l'impostazione SET SUMMARYLINES=NEW. Questa è ora l'impostazione predefinita.
xConvalida di valori parametro senza l'accesso al file dati: REGEX
È ora possibile convalidare un valore di parametro senza accedere ai dati, usando la maschera REGEX. La maschera REGEX specifica una espressione regolare da usare come stringa di convalida. Una espressione regolare è una sequenza di caratteri speciali e litterali da poter combinare per formare un modello di ricerca.
Sono presenti molti riferimento a espressioni regolari nel web. Per un riepilogo di base, consultare la sezione Riepilogo di Espressioni Regolari nel Capitolo 2, Sicurezza, del manuale Gestione Server.
La sintassi per la convalida di una variabile usando la amschera REGEX è
&variable.(|VALIDATE=REGEX,REGEX='regexpression').
dove:
- &variabile
-
La variabile da convalidare.
- regexpression
-
L'espressione regolare che specifica i valori accettabili.
Per esempio, la seguente richiesta convalida un numero Social Security nel formato xxxxxxxxx o xxx-xx-xxxx:
-REPEAT NEXTFMT FOR &FMTCNT FROM 1 TO 2
-SET &EMPID1=DECODE &FMTCNT(1 '071382660' 2 '818-69-2173');
-SET &EMPID=IF &EMPID1.(|VALIDATE=REGEX,REGEX='^\d{3}\-?\d{2}\-?\d{4}$').Employee ID. CONTAINS '-'
- THEN EDIT(&EMPID1,'999$99$9999') ELSE &EMPID1;
TABLE FILE EMPLOYEE
HEADING
" "
"Testing EMPID = &EMPID1</1"
PRINT EID CSAL
WHERE EID EQ '&EMPID.EVAL'
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
END
-RUN
-NEXTFMT L'emissione è
Testing EMPID = 071382660
EMP_ID CURR_SAL
071382660 $11,000.00
Testing EMPID = 818-69-2173
EMP_ID CURR_SAL
818692173 $27,062.00
I seguenti messaggi si visualizzano in caso di errore:
(FOC2909) INVALID REGULAR EXPRESSION:
(FOC2910) RESPONSE DOES NOT MATCH THE REGULAR EXPRESSION:
xAggiunta di limiti DBA ad una Condizione Unione
Quando le restrizioni DBA si applicano ad una richiesta su una struttura multi-segmento, per impostazione predefinita, le restrizioni si aggiungono come condizioni WHERE nella richiesta di prospetto. Quando il parametro DBAJOIN è impostato su ON, i limiti DBA sono trattati come interni al file o segmento per cui specificati e si aggiungono alla sintassi di unione.
Questa differenza è importante quando il file o segmento in restrizione presenta un elemento principale nella struttura e l'unione è una unione esterna o unica.
Quando le restrizioni si trattano come filtri di prospetto, le istanze di segmenti di livello inferiore non soddisfacenti sono omesse dall'emissione di prospetto, insieme ai segmenti host. Poiché i segmenti host sono omessi, l'emissione non riflette una unione unica o esterna true.
Quando le restrizioni si trattano come condizioni unione, i valori di livello inferiore da istanze di segmenti non soddisfacenti si visualizzano come valori mancanti e l'emissione di prospetto visualizza tutte le righe host.
x
Sintassi: Come aggiungere limiti DBA ad una Condizione Unione
SET DBAJOIN = {OFF|ON}
dove:
-
INATTIVO
-
Tratta limiti DBA come filtri WHERE nella richiesta di prospetto. Il valore predefinito è OFF.
- ATTIVO
-
Tratta limiti DBA come condizioni unione.
Esempio: Uso dell'impostazione DBAJOIN con tabelle relazionali
La seguente richiesta crea due tabelle: EMPINFOSQL e EDINFOSQL:
TABLE FILE EMPLOYEE
SUM LAST_NAME FIRST_NAME CURR_JOBCODE
BY EMP_ID
ON TABLE HOLD AS EMPINFOSQL FORMAT SQLMSS
END
-RUN
TABLE FILE EDUCFILE
SUM COURSE_CODE COURSE_NAME
BY EMP_ID
ON TABLE HOLD AS EDINFOSQL FORMAT SQLMSS
END
Aggiungere i seguenti attributi DBA alla fine del file principale EMPINFOSQL generato. Con le restrizioni elencate, USER2 non è in grado di recuperare codici corso di 300 o oltre:
END
DBA=USER1,$
USER=USER2, ACCESS = R, $
FILENAME=EDINFOSQL,$
USER=USER2, ACCESS = R, RESTRICT = VALUE, NAME=SYSTEM, VALUE=COURSE_CODE LT 300;,$
Aggiungere i seguenti attributi DBA alla fine del file principale EMPINFOSQL generato:
END
DBA=USER1,DBAFILE=EMPINFOSQL,$
Emettere la seguente richiesta:
SET USER=USER2
SET DBAJOIN=OFF
JOIN LEFT_OUTER EMP_ID IN EMPINFOSQL TO MULTIPLE EMP_ID IN EDINFOSQL AS J1
TABLE FILE EMPINFOSQL
PRINT LAST_NAME FIRST_NAME COURSE_CODE COURSE_NAME
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
END
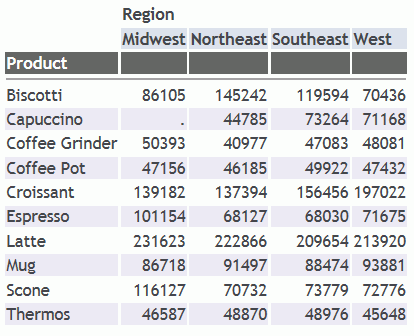
Sull'emissione di prospetto, tutte le righe host e secondarie con codici del corso 300 o superiore sono state omesse, come illustrato nella seguente immagine.

Nell'SQL generato, la restrizione DBA è stata aggiunta al predicato WHERE nella dichiarazione SELECT:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."CC",
T2."CD"
FROM
EMPINFOSQL T1,
EDINFOSQL T2
WHERE
(T2."EID" = T1."EID") AND
(T2."CC" < '300;');
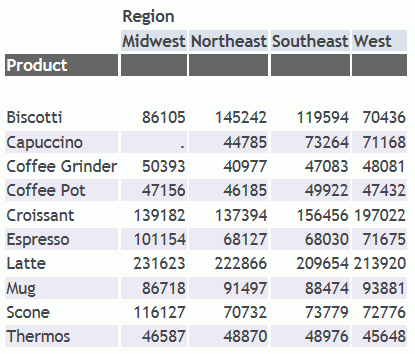
Rieseguire la richiesta con SET DBAJOIN=ON. L'emissione ora visualizza tutte le righe host, con i valori mancanti sostituiti per istanze di segmento di livello inferiore che non soddisfano la restrizione DBA, come illustrato nella seguente immagine.
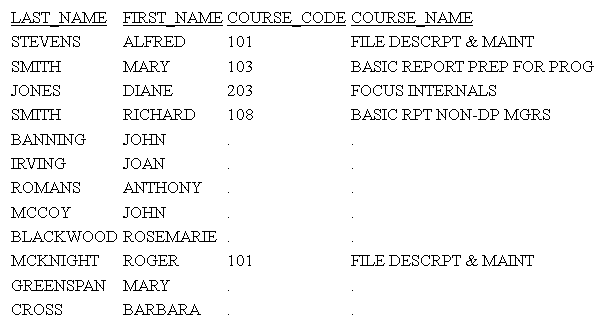
Nell'SQL generato, la restrizione DBA è stata aggiunta all'unione e non è presente il predicato WHERE:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."EID",
T2."CC",
T2."CD"
FROM
( EMPINFOSQL T1
LEFT OUTER JOIN EDINFOSQL T2
ON T2."EID" = T1."EID" AND
(T2."CC" < '300;') );
xMemorizzazione di metadati localizzati in file di lingua
Gli attributi di descrizioni e titoli di colonna localizzati possono essere memorizzati in un file master, usando gli attributi TITLE_lng e DESC_lng.
Tuttavia, se si desidera centralizzare titoli, descrizioni e richieste di colonne localizzate, applicandole a più file principali, è possibile creare un set di file di traduzione e usare l'attributo TRANS_FILE in un file principale per richiamarli.
x
Sintassi: Come creare e richiamare file di traduzione dei metadati
Convenzioni Denominazione File di Traduzione
I file di traduzione hanno nomi nella seguente forma:
prefix lng.lng
dove:
- prefisso
-
Un gruppo di caratteri anteposti ad ogni relativo file di traduzione.
- lng
-
Un codice di linguaggio.
Per esempio, se il prefisso comune è dt, il file di traduzione francese si chiamerebbe dtfre.lng e il file di traduzione inglese si chiamerebbe dteng.lng.
Contenuti File di Traduzione
Il file prefixeng.lng deve contenere qualsiasi valore titolo, descrizione e richiesta che si desidera tradurre quando si visualizza nel file master, sia in inglese che in un'altra lingua:
- Copiare ogni valore attributo dal file master che si desidera tradurre nel file di traduzione (eng) predefinito e assegnare un numero indice. I numeri di indice non devono essere consecutivi o in ordine. Per esempio:
39 = Product,Category
- Aggiungere traduzioni di questi valori attributo ai file di traduzione per altre lingue in cui si desidera visualizzare i metadati. Assegnare lo stesso numero di indice alle traduzioni. Per esempio, nel file di traduzione francese:
39 = Produit,Catégorie
Identificazione dei file di traduzione da usare per un file master
Per specificare che il file master dovrebbe usare un set specifico di file di traduzione, identificare il prefisso comune nella dichiarazione FILE del file master:
FILENAME=filename, TRANS_FILE=[path]/prefix, ...
Dove:
- filename
-
Il nome specificato nell'attributo FILE=.
- percorso
-
Le informazioni necessarie per localizzare il set dei file di traduzione. È in grado di essere un percorso completo o un app riferimento. Se è presente un set di file di traduzione con il prefisso in uso e si trova nel percorso app, è possibile ometterlo.
- prefisso
-
Il prefisso comune per il set dei file di traduzione.
Richiamo dei file di traduzione per una richiesta
- Assicurarsi che il server stia usando un code page che supporta le lingue da usare.
- Impostare il parametro LANGUAGE al linguaggio in cui si dovrebbero visualizzare i metadati.
- Eseguire la richiesta.
Esempio: Uso di File di Traduzione
La seguente richiesta usa l'origine dati WF_RETAIL_LITE:
TABLE FILE WF_RETAIL
SUM REVENUE_US
BY PRODUCT_CATEGORY
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE = TITLE, FONT='Trebuchet MS', $
ENDSTYLE
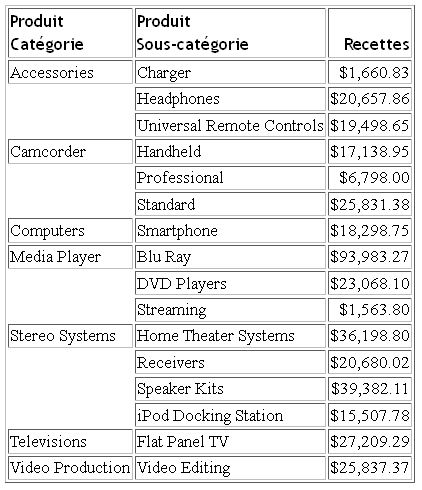
END
L'emissione è:
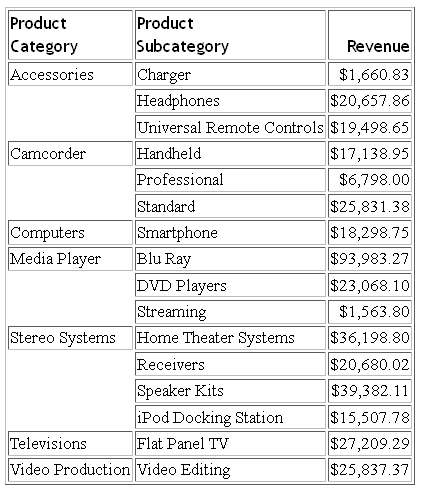
Il file master contiene il seguente attributo TRANS_FILE:
FILENAME=WF_RETAIL_LITE, TRANS_FILE=_EDAHOME/NLS/dt, ...
L'attributo TRANS_FILE punta ai file che iniziano con i caratteri dt, nella cartella NLS, nella directory EDAHOME. Il seguente campione mostra alcuni dei contenuti del file di traduzione predefinito, dteng.lng:
1 = Age
2 = Age Range
3 = Age Group
6 = Gender
9 = Discount,Rate
10 = Discount,Price,Multiplier
15 = Country
17 = State
19 = City
31 = Customer,Income Range
32 = Customer,Income Subrange
33 = Households
34 = Number of,Earners
35 = Household,Size
36 = Industry
38 = Occupation
39 = Product,Category
40 = Product,Subcategory
41 = Brand Type
Il testo assegnato ad ogni numero si trova in uno dei file master associati con il file master WF_RETAIL_LITE. WF_RETAIL_LITE è un file master cluster che fa riferimento a file principale fact e dimensione, per creare uno schema a stella.
Il seguente campione mostra i contenuti corrispondenti del file di traduzione francese, dtfre.lng:
1 = Age
2 = Tranche d'âge
3 = Groupe d'âge
6 = Sexe
9 = Remise,Taux
10 = Remise,Prix,Multiplicateur
15 = Pays
17 = Département
19 = Ville
31 = Client,Tranche de revenus
32 = Client,Sous-tranche de revenus
33 = Ménages
34 = Nombre de,Salariés
35 = Ménage,Taille
36 = Secteur d'activité
38 = Profession
39 = Produit,Catégorie
40 = Produit,Sous-catégorie
41 = Type de marque
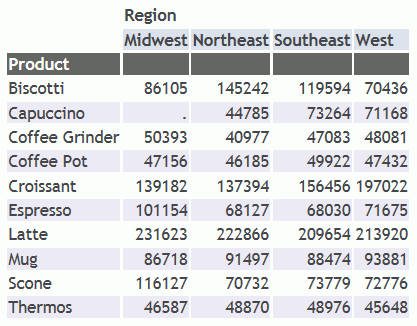
Quando la lingua è impostata su Francese, qualsiasi testo da visualizzare che rappresenta una corrispondenza esatta a qualsiasi numero indice nel file dteng.lng verrà sostituita con il testo per lo stesso numero indice nel file dtfre.lng.
La seguente versione della richiesta aggiunge il comando SET LANG=FRE. Il code page server supporta inglese e francese:
SET LANG = FRE
TABLE FILE WF_RETAIL
SUM REVENUE_US
BY PRODUCT_CATEGORY
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE = TITLE, FONT='Trebuchet MS', $
ENDSTYLE
END
L'emissione ha tradotto i titoli di colonna: