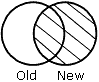spécifie la façon dont les enregistrements récupérés des fichiers sont comparés.
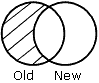
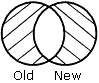
Les résultats de chaque phrase sont représentés graphiquement dans des diagrammes de Venn. Dans ces diagrammes, le cercle de gauche représente la vieille source de données, le cercle de droite représente la nouvelle source de données et les zones grises représentent les données écrites dans le fichier HOLD.
OLD-OR-NEW spécifie que tous les enregistrements de la vieille source de données et de la nouvelle source de données s'affichent dans le fichier HOLD. Ceci est la valeur par défaut si la ligne AFTER MATCH est omise.
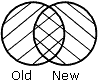
OLD-AND-NEW spécifie que les enregistrements s'affichent dans les vieilles et nouvelles sources de données dans le fichier HOLD. (L'intersection des ensembles).
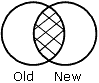
OLD-NOT-NEW spécifie qu'uniquement les enregistrements qui se trouvent dans la vieille source de données s'affichent dans le fichier HOLD.
NEW-NOT-OLD spécifie qu'uniquement les enregistrements qui se trouvent dans la nouvelle source de données s'affichent dans le fichier HOLD.
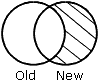
OLD-NOR-NEW spécifie qu'uniquement les enregistrements qui se trouvent dans le vieille source de données mais pas dans la nouvelle source de données, ou vise versa, s'affichent dans le fichier HOLD (l'ensemble entier d'enregistrements non correspondants des deux sources de données).
OLD spécifie que tous les enregistrements de la vieille source de données, et tout enregistrement correspondant de la nouvelle source de données, soient fusionnés dans le fichier HOLD.
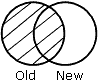
NEW spécifie que tous les enregistrements de la nouvelle source de données, et tout enregistrement correspondant de la vieille source de données, soient fusionnés dans le fichier HOLD.