Syntax: How to Calculate a Double Exponential Smoothing Column
FORECAST_DOUBLEXP(display, infield, interval, npredict, npoint1, npoint2)
where:
- display
-
Keyword
Specifies which values to display for rows of output that represent existing data. Valid values are:
- INPUT_FIELD. This displays the original field values for rows that represent existing data.
- MODEL_DATA. This displays the calculated values for rows that represent existing data.
Note: You can show both types of output for any field by creating two independent COMPUTE commands in the same request, each with a different display option.
- infield
- Is any numeric field. It can be the same field as the result field, or a different field. It cannot be a date-time field or a numeric field with date display options.
- interval
- Is the increment to add to each sort field value (after
the last data point) to create the next value. This must be a positive
integer. To sort in descending order, use the BY HIGHEST phrase.
The result of adding this number to the sort field values
is converted to the same format as the sort field.
For date fields, the minimal component in the format determines how the number is interpreted. For example, if the format is YMD, MDY, or DMY, an interval value of 2 is interpreted as meaning two days. If the format is YM, the 2 is interpreted as meaning two months.
- npredict
- Is the number of predictions for FORECAST to calculate. It must be an integer greater than or equal to zero. Zero indicates that you do not want predictions, and is only supported with a non-recursive FORECAST.
- npoint1
- For
DOUBLEXP, this number is used to calculate
the weights for each component in the average. This value must be
a positive whole number. The weight, k, is calculated by the following
formula:
k=2/(1+npoint1)
- npoint2
- For DOUBLEXP, this positive whole number is used
to calculate the weights for each term in the trend. The weight,
g, is calculated by the following formula:
g=2/(1+npoint2)
Example: Calculating a Double Exponential Smoothing Column
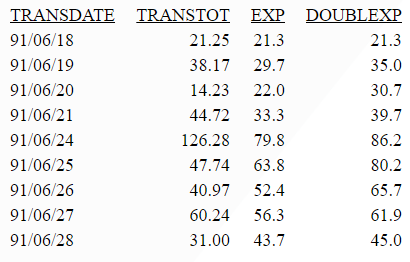
The following sums the TRANSTOT field of the VIDEOTRK data source by TRANSDATE, and calculates a single exponential and double exponential moving average. The report columns show the calculated values for existing data points.
TABLE FILE VIDEOTRK SUM TRANSTOT COMPUTE EXP/D15.1 = FORECAST_EXPAVE(MODEL_DATA,TRANSTOT,1,0,3); DOUBLEXP/D15.1 = FORECAST_DOUBLEXP(MODEL_DATA,TRANSTOT,1,0,3,3); BY TRANSDATE WHERE TRANSDATE NE '19910617' ON TABLE SET STYLE * GRID=OFF,$ END
The output is shown in the following image: