Creating Synonyms for DB2 Data Sources
|
How to: |
|
Reference: |
The AUTOSYN facility creates synonyms (Master and Access Files) for existing tables using RDBMS catalog definitions and user selections. All data types supported by the adapter are available for the generated Master Files.
Only single-segment Master and Access Files can be created with this facility. Each synonym created describes a single table or a view of a single table.
Master Files are generated in the first writable data set allocated to DDNAME MASTER. Access Files are generated in the first writable data set allocated to DDNAME ACCESS, which is a required DDNAME for using this facility to generate synonyms. For running requests and for viewing or editing synonyms, both the ACCESS and FOCSQL DDNAMEs are supported.
Reference: Overview of the AUTOSYN Facility
When you invoke the AUTOSYN facility, a screen displays on which you enter search fields and processing options.
The search fields are used to generate a list of candidate tables.
Once the list of tables has been generated, you can select tables from the list and select a processing option by pressing a Function key.
The synonyms processed by the AUTOSYN facility do not have to be generated by the facility. The following processing options are available:
- Create synonyms.
- View/Edit Master Files.
- View/Edit Access Files.
- Issue the CHECK FILE command.
- Execute test queries.
Procedure: How to Create Synonyms for DB2 Tables
- Issue the following command from the
FOCUS prompt.
EX AUTOSYN
The SQL Master File Generation Facility opens, as shown in the following image:
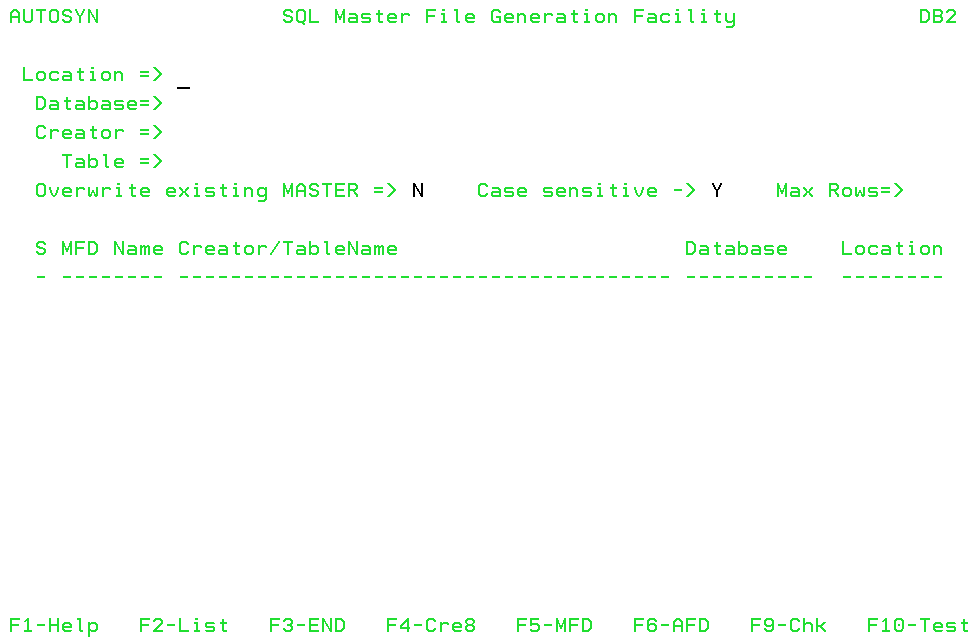
- Enter one or more search values and processing options
on this screen.
You can enter information into one or more of the search fields at the top of the screen. Based on the values you enter, a list of candidate tables will be generated when you press F2.
You can enter specific values or a pattern that uses wildcard characters. The underscore character (_) indicates that any single character in that position will be considered a match to the pattern. A percent symbol (%) indicates that a variable number of characters in that position will be considered a match to the pattern. A blank search field accepts any value found for that field.
Following is a list of the search fields. To proceed from one field to the next, press the Tab key. To move backward, press Shift+Tab.
- Location.
- Database.
- Creator.
- Table name.
The following entry fields on the screen have default values that you can change:
- Overwrite existing MASTER. The default is N (No). To overwrite an existing synonym with the same name, enter Y.
- Case sensitive. The default is Y (Yes). To turn off case sensitivity, enter N.
- Max Rows. By default, all matching tables display, and you can scroll through the list using the F7 and F8 keys. To limit the number of lines displayed, enter a number.
Help is available for each entry field by pressing F1 when the cursor is in the field.
- Press F2 to generate a list of
tables that match the criteria you specified in the entry fields.
A list similar to the following displays:
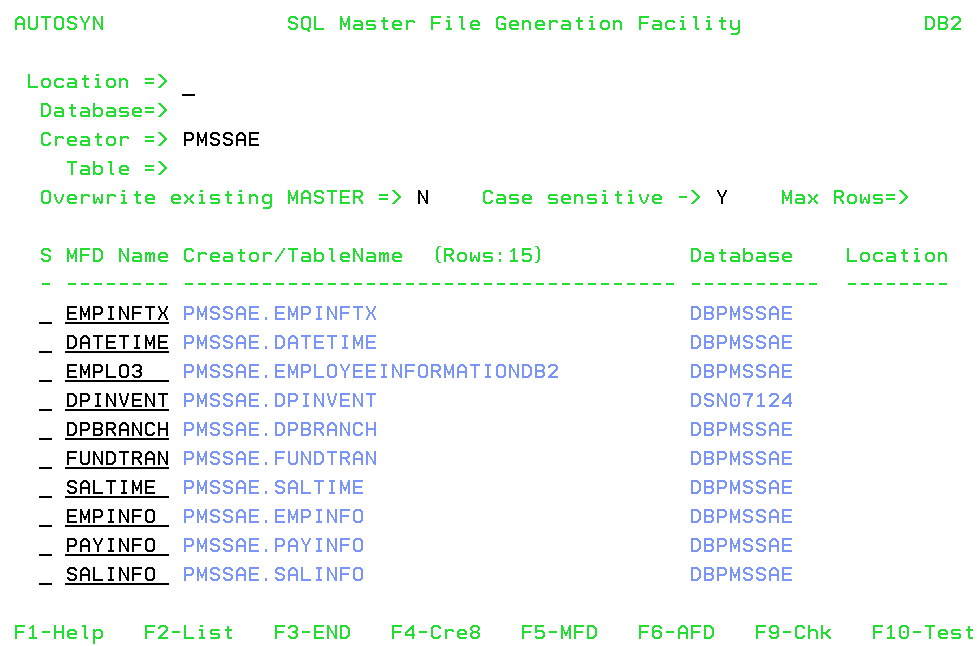
You can then select one or more tables from this list by entering S in the S column.
By selecting rows from this list, you can:
- Create synonyms (F4).
- View/Edit Master Files (F5).
- View/Edit Access Files (F6).
- Issue the CHECK FILE command (F9).
- Run test queries (F10).
The list of tables has the following columns:
- S. Enter S on each row you want to select for the operation to be performed.
- MFD Name. Is the default synonym name that will be generated when you press F4. You can type over this name to specify your own synonym name. The name can be up to eight characters long. The default name is the table name, if it is less than or equal to eight characters. If the table name is more than eight characters, the default name is composed of the first four characters of the table name appended with the line number.
- Creator/TableName. Contains the Creator and Table name for that row.
- Location. Contains the Location name for that row. A blank represents a local table.
- Enter S in the S column on one or more lines, and press the Function key that corresponds to the operation you wish to perform.
Reference: Results of the AUTOSYN Facility Processing Options
Synonym Generation Results
If you used the synonym generation processing option (F4), the following changes display on the list:
- On each line for which the operation was successful, P displays in the S column, and both the P and the synonym name are light blue.
- On each line for which the operation was unsuccessful, F displays
in the S column, and both the P and the synonym name are red. In
addition, a message displays at the bottom of the screen indicating
what the problem was, as shown on the following screen:
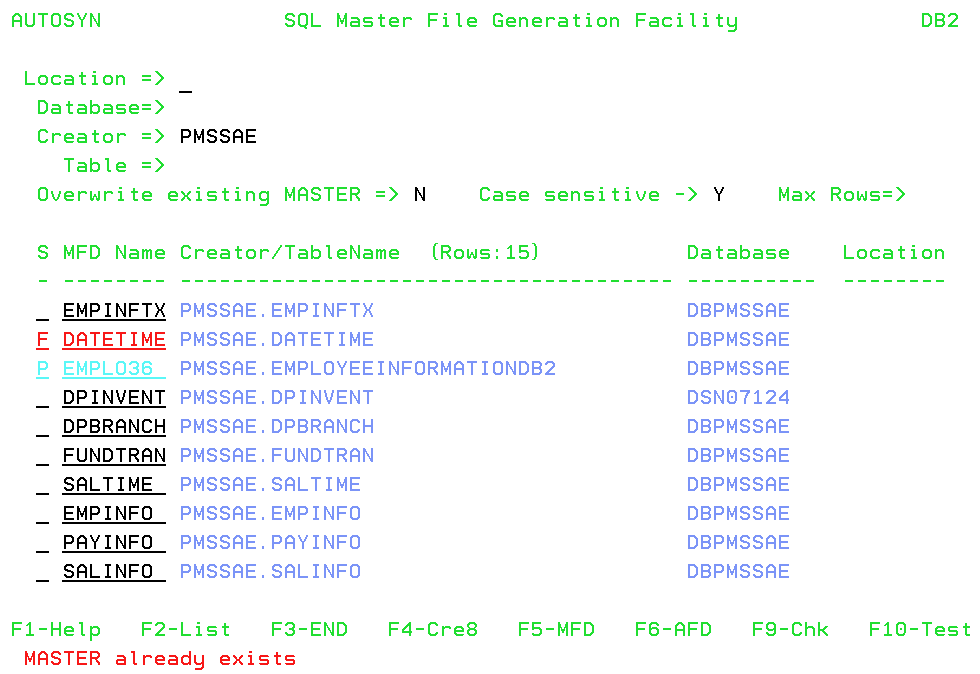
A synonym named EMPL036 was generated successfully, but the DATETIME synonym was not generated because the synonym already exists, and Overwrite existing MASTER is set to N.
Master Files are generated in the first writable data set allocated to DDNAME MASTER. Access Files are generated in the first writable data set allocated to DDNAME ACCESS. DDNAME ACCESS is a required DDNAME for using this facility to generate synonyms. For viewing or editing synonyms or for running requests against relational data sources, both the FOCSQL and ACCESS DDNAMEs are supported.
View/Edit Master and Access Files Results
If your processing option was F5 to view Master Files or F6 to view Access Files, the TED editor opens, as shown in the following image.
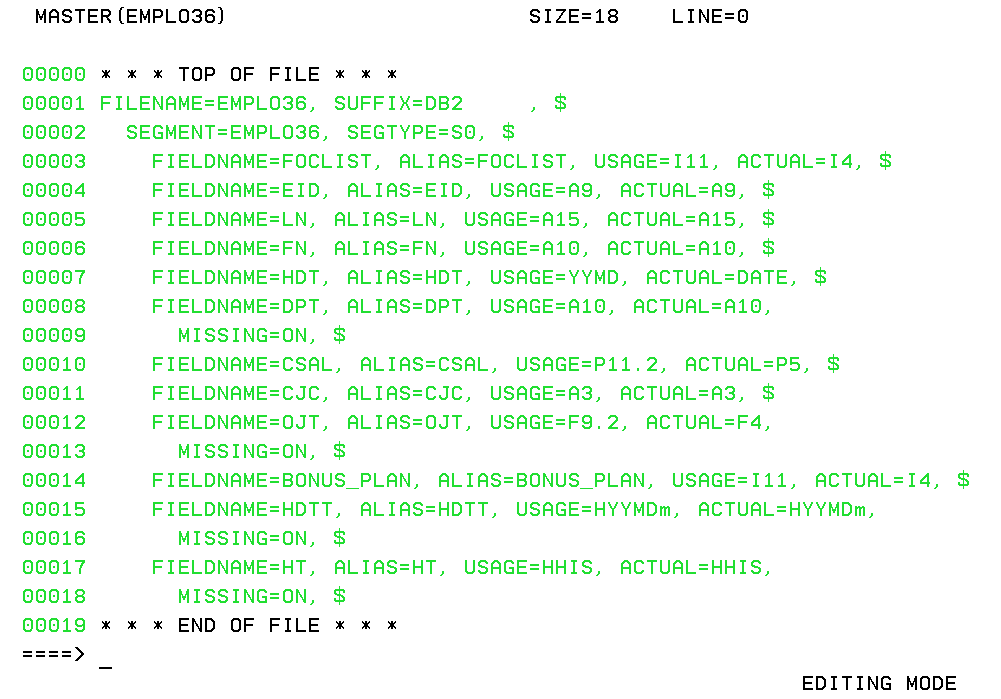
You can edit the Master or Access File, if necessary.
To exit TED, leaving the file unchanged:
- Press F3 if you did not make changes,
- Issue the QQ command if you did make changes.
To exit TED and save changes, issue the FILE command.
If you selected multiple tables, the Master or Access File for the next selected table will open. After the last selected Master or Access File is processed, you return to the list of candidate tables.
CHECK FILE Results
If your processing option was F9 to issue the CHECK FILE command, an output screen will display, as shown in the following image.

To exit the CHECK FILE output screen, enter EXIT at the WAIT prompt.
Test Query Results
If your processing option was F10 to run test queries, Hotscreen opens, as shown in the following image.
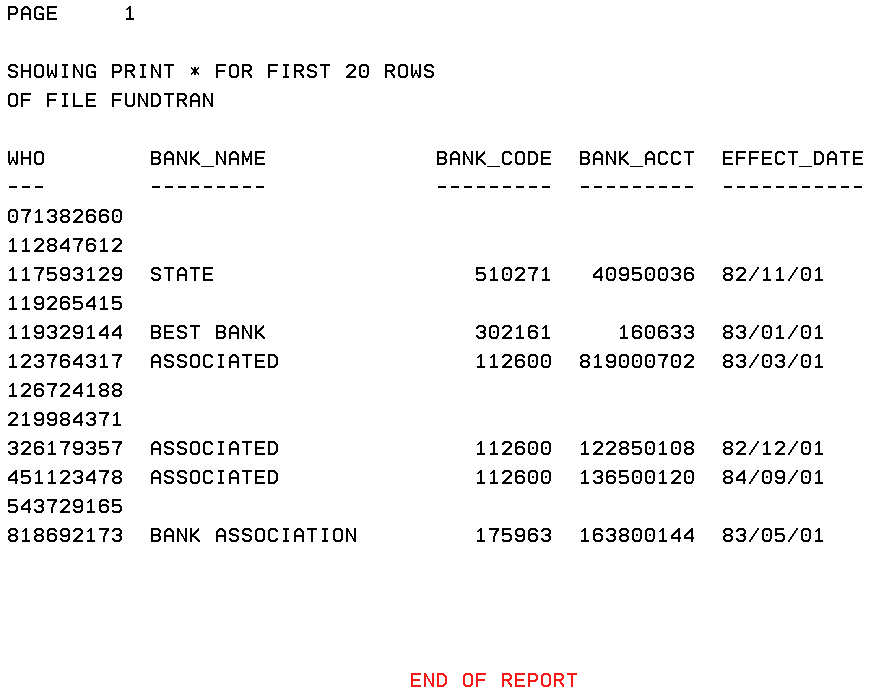
To exit Hotscreen at the last page of output, press Enter.
Reference: Properties of Generated Synonyms
In the Master File:
- The FILENAME and SEGMENT values are the synonym (member) name you specified on the initial screen.
- The SEGTYPE value is always S0.
- Field declarations for primary key columns are listed first, followed by those for non-key fields.
- FIELDNAME and ALIAS values are the full RDBMS column names.
- Data types are determined as specified in the Data Type Support section of the Relational Adapter User’s Manual. Field lengths for USAGE and ACTUAL formats are calculated automatically.
- The MISSING attribute is included and is set ON if the RDBMS table definition allows NULLs.
In the Access File:
- The SEGNAME value matches the corresponding SEGMENT value in the Master File.
- The TABLENAME value is composed of the creator name and the table name. If a location was specified, the location, creator, and table name compose the TABLENAME value.
- The KEYS value is supplied. It is determined using existing
RDBMS indexes. This also determines the order in which to place
fields in the Master File. KEYS is set to zero if a unique index
does not exist or if an RDBMS view is described.
Note: In the case of a view, the unique indexes are described on the underlying tables, not on the view. They may not be valid as a primary key for the view. If possible, edit the Master and Access Files to reflect the index structure of the base tables.
- The optional keyword DBSPACE is omitted.
You may need to edit the generated Master File or its corresponding Access File if:
- You prefer field names different from the generated names.
- There are RDBMS data types in the tables or views that the adapter does not support. Field declarations are not generated for columns with unsupported data types. You can add the field declarations yourself.
- A unique index does not exist, or you want to use a different index from the selected one. If the table or view has a primary key, specify a value greater than zero for the KEYS attribute, and rearrange the fields in the Master File so that the columns comprising the primary key are described first.
- Certain fields are classified for security reasons. To add security, delete field declarations or include FOCUS DBA attributes.
- You require options such as DEFINE fields and KEYORDER.
Reference: Function Key Assignments
The following table describes the function of each Function key.
|
Function Key |
Description |
|---|---|
|
F1 |
Displays context sensitive Help. Note: If you press F1 twice, a list of Function key assignments is displayed. |
|
F2 |
Generate a list of candidate tables using the search fields at the top of the screen. |
|
F3 |
Exit the current screen. |
|
F4 |
Generate synonyms for selected tables. |
|
F5 |
View/Edit Master Files of selected tables. |
|
F6 |
View/Edit Access Files of selected tables. |
|
F7 |
Scroll down. |
|
F8 |
Scroll up. |
|
F9 |
Issue the CHECK FILE command for the selected tables. |
|
F10 |
Run test queries for the selected tables. |